Bradley Karlin, Doug Henry, Ryan Anderson, Salvatore Cieri, Michael Aratow, Elizabeth Shriberg, Michelle Hoy
{"title":"Digital Phenotyping for Detecting Depression Severity in a Large Payor-Provider System: Retrospective Study of Speech and Language Model Performance.","authors":"Bradley Karlin, Doug Henry, Ryan Anderson, Salvatore Cieri, Michael Aratow, Elizabeth Shriberg, Michelle Hoy","doi":"10.2196/69149","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>There is considerable need to improve and increase the detection and measurement of depression. The use of speech as a digital biomarker of depression represents a considerable opportunity for transforming and accelerating depression identification and treatment; however, research to date has primarily consisted of small-sample feasibility or pilot studies incorporating highly controlled applications and settings. There has been limited examination of the technology in real-world use contexts.</p><p><strong>Objective: </strong>This study evaluated the performance of a machine learning (ML) model examining both semantic and acoustic properties of speech in predicting depression across more than 2000 real-world interactions between health plan members and case managers.</p><p><strong>Methods: </strong>A total of 2086 recordings of case management calls with verbally administered Patient Health Questionnaire-9 questions (PHQ-9) surveys were analyzed using the ML model after the portions of the recordings with the PHQ-9 survey were manually redacted. The recordings were divided into a Development Set (Dev Set) (n=1336) and a Blind Set (n=671), and Patient Health Questionnaire-8 questions (PHQ-8) scores were provided for the Dev Set for ML model refinement while PHQ-8 scores from the Blind Set were withheld until after ML model depression severity output was reported.</p><p><strong>Results: </strong>The Dev Set and the Blind Set were well matched for age (Dev Set: mean 53.7, SD 16.3 years; Blind Set: mean 51.7, SD 16.9 years), gender (Dev Set: 910/1336, 68.1% of female participants; Blind Set: 462/671, 68.9% of female participants), and depression severity (Dev Set: mean 10.5, SD 6.1 of PHQ-8 scores; Blind Set: mean 10.9, SD 6.0 of PHQ-8 scores). The concordance correlation coefficient was ρc=0.57 for the test of the ML model on the Dev Set and ρc=0.54 on the Blind Set, while the mean absolute error was 3.91 for the Dev Set and 4.06 for the Blind Set, demonstrating strong model performance. This performance was maintained when dividing each set into subgroups of age brackets (≤39, 40-64, and ≥65 years), biological sex, and the 4 categories of Social Vulnerability Index (an index based on 16 social factors), with concordance correlation coefficients ranging as ρc=0.44-0.61. Performance at PHQ-8 threshold score cutoffs of 5, 10, 15, and 20, representing the depression severity categories of none, mild, moderate, moderately severe, and severe (≥20), respectively, expressed as area under the receiver operating characteristic curve values, varied between 0.79 and 0.83 in both the Dev and Blind Sets.</p><p><strong>Conclusions: </strong>Overall, the findings suggest that speech may have significant potential for detection and measurement of depression severity over a variety of ages, gender, and socioeconomic categories that may enhance treatment, improve clinical decision-making, and enable truly personalized treatment recommendations.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e69149"},"PeriodicalIF":2.0000,"publicationDate":"2025-06-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12223686/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/69149","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: There is considerable need to improve and increase the detection and measurement of depression. The use of speech as a digital biomarker of depression represents a considerable opportunity for transforming and accelerating depression identification and treatment; however, research to date has primarily consisted of small-sample feasibility or pilot studies incorporating highly controlled applications and settings. There has been limited examination of the technology in real-world use contexts.
Objective: This study evaluated the performance of a machine learning (ML) model examining both semantic and acoustic properties of speech in predicting depression across more than 2000 real-world interactions between health plan members and case managers.
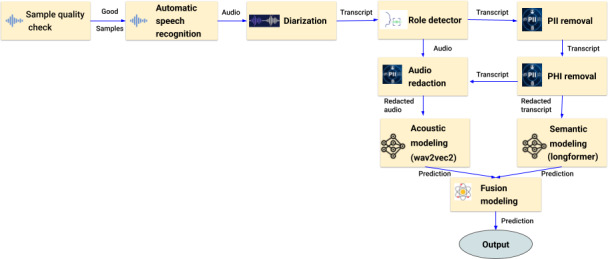
Methods: A total of 2086 recordings of case management calls with verbally administered Patient Health Questionnaire-9 questions (PHQ-9) surveys were analyzed using the ML model after the portions of the recordings with the PHQ-9 survey were manually redacted. The recordings were divided into a Development Set (Dev Set) (n=1336) and a Blind Set (n=671), and Patient Health Questionnaire-8 questions (PHQ-8) scores were provided for the Dev Set for ML model refinement while PHQ-8 scores from the Blind Set were withheld until after ML model depression severity output was reported.
Results: The Dev Set and the Blind Set were well matched for age (Dev Set: mean 53.7, SD 16.3 years; Blind Set: mean 51.7, SD 16.9 years), gender (Dev Set: 910/1336, 68.1% of female participants; Blind Set: 462/671, 68.9% of female participants), and depression severity (Dev Set: mean 10.5, SD 6.1 of PHQ-8 scores; Blind Set: mean 10.9, SD 6.0 of PHQ-8 scores). The concordance correlation coefficient was ρc=0.57 for the test of the ML model on the Dev Set and ρc=0.54 on the Blind Set, while the mean absolute error was 3.91 for the Dev Set and 4.06 for the Blind Set, demonstrating strong model performance. This performance was maintained when dividing each set into subgroups of age brackets (≤39, 40-64, and ≥65 years), biological sex, and the 4 categories of Social Vulnerability Index (an index based on 16 social factors), with concordance correlation coefficients ranging as ρc=0.44-0.61. Performance at PHQ-8 threshold score cutoffs of 5, 10, 15, and 20, representing the depression severity categories of none, mild, moderate, moderately severe, and severe (≥20), respectively, expressed as area under the receiver operating characteristic curve values, varied between 0.79 and 0.83 in both the Dev and Blind Sets.
Conclusions: Overall, the findings suggest that speech may have significant potential for detection and measurement of depression severity over a variety of ages, gender, and socioeconomic categories that may enhance treatment, improve clinical decision-making, and enable truly personalized treatment recommendations.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


