Clinical Laboratory Parameter-Driven Machine Learning for Participant Selection in Bioequivalence Studies Among Patients With Gastric Cancer: Framework Development and Validation Study.
Byungeun Shon, Sook Jin Seong, Eun Jung Choi, Mi-Ri Gwon, Hae Won Lee, Jaechan Park, Ho-Young Chung, Sungmoon Jeong, Young-Ran Yoon
{"title":"Clinical Laboratory Parameter-Driven Machine Learning for Participant Selection in Bioequivalence Studies Among Patients With Gastric Cancer: Framework Development and Validation Study.","authors":"Byungeun Shon, Sook Jin Seong, Eun Jung Choi, Mi-Ri Gwon, Hae Won Lee, Jaechan Park, Ho-Young Chung, Sungmoon Jeong, Young-Ran Yoon","doi":"10.2196/64845","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Insufficient participant enrollment is a major factor responsible for clinical trial failure.</p><p><strong>Objective: </strong>We formulated a machine learning (ML)-based framework using clinical laboratory parameters to identify participants eligible for enrollment in a bioequivalence study.</p><p><strong>Methods: </strong>We acquired records of 11,592 patients with gastric cancer from the electronic medical records of Kyungpook National University Hospital in Korea. The ML model was developed using 8 clinical laboratory parameters, including complete blood count and liver and kidney function tests, along with the dates of acquisition. Two datasets were collected: (1) a training dataset to design an ML-based candidate selection method and (2) a test dataset to evaluate the performance of the proposed method. The generalization performance of the ML-based method was confirmed using the F1-score and the area under the curve (AUC). The proposed model was compared with a random selection method to evaluate its efficacy in recruiting participants.</p><p><strong>Results: </strong>The weighted ensemble model achieved strong performance with an F1-score above 0.8 and an AUC value exceeding 0.8, demonstrating its ability to accurately identify valid clinical trial candidates while minimizing misclassification. Its high sensitivity further enhanced the model's efficiency in prioritizing patients for screening. In a case study, the proposed ML model reduced the workload by 57%, efficiently identifying 150 valid patients from a pool of 209, compared to the 485 patients required by random selection.</p><p><strong>Conclusions: </strong>The proposed ML-based framework using clinical laboratory parameters can be used to identify patients eligible for a clinical trial, enabling faster participant enrollment.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e64845"},"PeriodicalIF":2.0000,"publicationDate":"2025-05-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12223687/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/64845","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Insufficient participant enrollment is a major factor responsible for clinical trial failure.
Objective: We formulated a machine learning (ML)-based framework using clinical laboratory parameters to identify participants eligible for enrollment in a bioequivalence study.
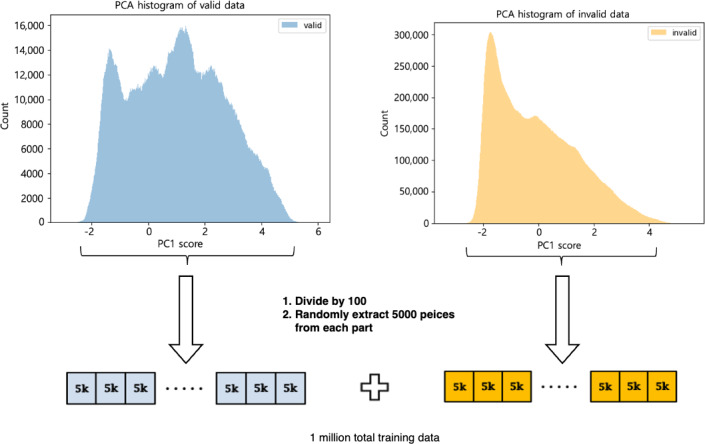
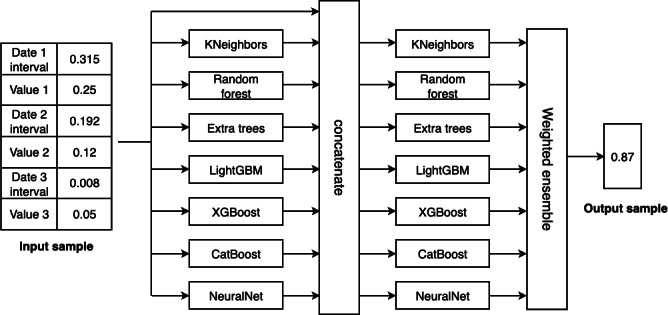
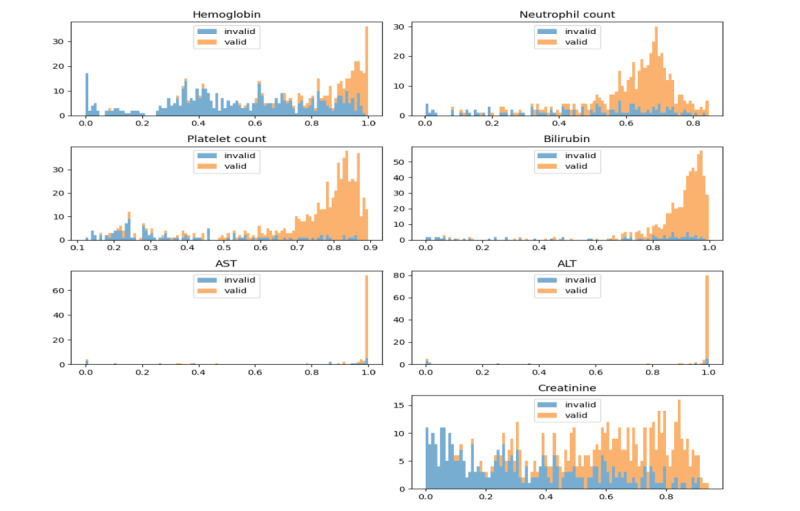
Methods: We acquired records of 11,592 patients with gastric cancer from the electronic medical records of Kyungpook National University Hospital in Korea. The ML model was developed using 8 clinical laboratory parameters, including complete blood count and liver and kidney function tests, along with the dates of acquisition. Two datasets were collected: (1) a training dataset to design an ML-based candidate selection method and (2) a test dataset to evaluate the performance of the proposed method. The generalization performance of the ML-based method was confirmed using the F1-score and the area under the curve (AUC). The proposed model was compared with a random selection method to evaluate its efficacy in recruiting participants.
Results: The weighted ensemble model achieved strong performance with an F1-score above 0.8 and an AUC value exceeding 0.8, demonstrating its ability to accurately identify valid clinical trial candidates while minimizing misclassification. Its high sensitivity further enhanced the model's efficiency in prioritizing patients for screening. In a case study, the proposed ML model reduced the workload by 57%, efficiently identifying 150 valid patients from a pool of 209, compared to the 485 patients required by random selection.
Conclusions: The proposed ML-based framework using clinical laboratory parameters can be used to identify patients eligible for a clinical trial, enabling faster participant enrollment.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


