Algorithmic Classification of Psychiatric Disorder-Related Spontaneous Communication Using Large Language Model Embeddings: Algorithm Development and Validation.
Ryan Allen Shewcraft, John Schwarz, Mariann Micsinai Balan
{"title":"Algorithmic Classification of Psychiatric Disorder-Related Spontaneous Communication Using Large Language Model Embeddings: Algorithm Development and Validation.","authors":"Ryan Allen Shewcraft, John Schwarz, Mariann Micsinai Balan","doi":"10.2196/67369","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Language, which is a crucial element of human communication, is influenced by the complex interplay between thoughts, emotions, and experiences. Psychiatric disorders have an impact on cognitive and emotional processes, which in turn affect the content and way individuals with these disorders communicate using language. The recent rapid advancements in large language models (LLMs) suggest that leveraging them for quantitative analysis of language usage has the potential to become a useful method for providing objective measures in diagnosing and monitoring psychiatric conditions by analyzing language patterns.</p><p><strong>Objective: </strong>This study aims to explore the use of LLMs in analyzing spontaneous communication to differentiate between various psychiatric disorders. We seek to show that the latent LLM embedding space identifies distinct linguistic markers that can be used to classify spontaneous communication from 7 different psychiatric disorders.</p><p><strong>Methods: </strong>We used embeddings from the 7 billion parameter Generative Representational Instruction Tuning Language Model to analyze more than 37,000 posts from subreddits dedicated to seven common conditions: schizophrenia, borderline personality disorder (BPD), depression, attention-deficit/hyperactivity disorder (ADHD), anxiety, posttraumatic stress disorder (PTSD) and bipolar disorder. A cross-validated multiclass Extreme Gradient Boosting classifier was trained on these embeddings to predict the origin subreddit for each post. Performance was evaluated using metrics such as precision, recall, F1-score, and area under the receiver operating characteristic curve (AUC). In addition, we used Uniform Manifold Approximation and Projection dimensionality reduction to visualize relationships in language between these psychiatric disorders.</p><p><strong>Results: </strong>The 10-fold cross-validated Extreme Gradient Boosting classifier achieved a support-weighted average precision, recall, F1, and accuracy score of 0.73, 0.73, 0.73, and 0.73, respectively. In one-versus-rest tasks, individual category AUCs ranged from 0.89 to 0.97, with a microaverage AUC of 0.95. ADHD posts were classified with the highest AUC of 0.97, indicating distinct linguistic features, while BPD posts had the lowest AUC of 0.89, suggesting greater linguistic overlap with other conditions. Consistent with the classifier results, the ADHD posts have a more visually distinct cluster in the Uniform Manifold Approximation and Projection projects, while BPD overlaps with depression, anxiety, and schizophrenia. Comparisons with other state-of-the-art embedding methods, such as OpenAI's text-embedding-3-small (AUC=0.94) and sentence-bidirectional encoder representations from transformers (AUC=0.86), demonstrated superior performance of the Generative Representational Instruction Tuning Language Model-7B model.</p><p><strong>Conclusions: </strong>This study introduces an innovative use of LLMs in psychiatry, showcasing their potential to objectively examine language use for distinguishing between different psychiatric disorders. The findings highlight the capability of LLMs to offer valuable insights into the linguistic patterns unique to various conditions, paving the way for more efficient, patient-focused diagnostic and monitoring strategies. Future research should aim to validate these results with clinically confirmed populations and investigate the implications of comorbidity and spectrum disorders.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e67369"},"PeriodicalIF":2.0000,"publicationDate":"2025-05-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12223684/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/67369","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Language, which is a crucial element of human communication, is influenced by the complex interplay between thoughts, emotions, and experiences. Psychiatric disorders have an impact on cognitive and emotional processes, which in turn affect the content and way individuals with these disorders communicate using language. The recent rapid advancements in large language models (LLMs) suggest that leveraging them for quantitative analysis of language usage has the potential to become a useful method for providing objective measures in diagnosing and monitoring psychiatric conditions by analyzing language patterns.
Objective: This study aims to explore the use of LLMs in analyzing spontaneous communication to differentiate between various psychiatric disorders. We seek to show that the latent LLM embedding space identifies distinct linguistic markers that can be used to classify spontaneous communication from 7 different psychiatric disorders.
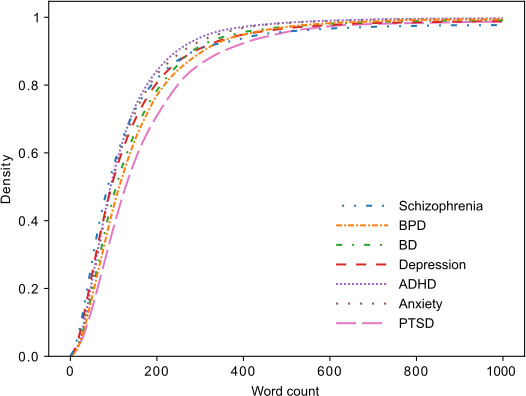
Methods: We used embeddings from the 7 billion parameter Generative Representational Instruction Tuning Language Model to analyze more than 37,000 posts from subreddits dedicated to seven common conditions: schizophrenia, borderline personality disorder (BPD), depression, attention-deficit/hyperactivity disorder (ADHD), anxiety, posttraumatic stress disorder (PTSD) and bipolar disorder. A cross-validated multiclass Extreme Gradient Boosting classifier was trained on these embeddings to predict the origin subreddit for each post. Performance was evaluated using metrics such as precision, recall, F1-score, and area under the receiver operating characteristic curve (AUC). In addition, we used Uniform Manifold Approximation and Projection dimensionality reduction to visualize relationships in language between these psychiatric disorders.
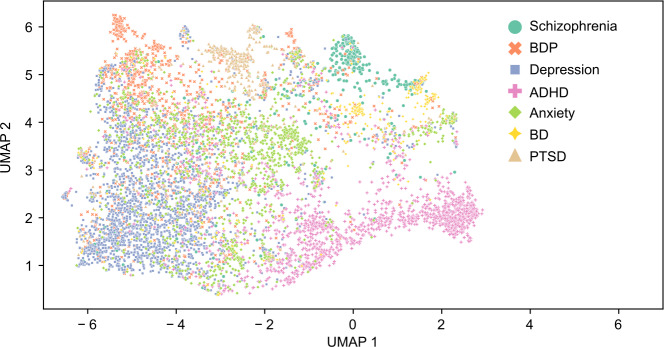
Results: The 10-fold cross-validated Extreme Gradient Boosting classifier achieved a support-weighted average precision, recall, F1, and accuracy score of 0.73, 0.73, 0.73, and 0.73, respectively. In one-versus-rest tasks, individual category AUCs ranged from 0.89 to 0.97, with a microaverage AUC of 0.95. ADHD posts were classified with the highest AUC of 0.97, indicating distinct linguistic features, while BPD posts had the lowest AUC of 0.89, suggesting greater linguistic overlap with other conditions. Consistent with the classifier results, the ADHD posts have a more visually distinct cluster in the Uniform Manifold Approximation and Projection projects, while BPD overlaps with depression, anxiety, and schizophrenia. Comparisons with other state-of-the-art embedding methods, such as OpenAI's text-embedding-3-small (AUC=0.94) and sentence-bidirectional encoder representations from transformers (AUC=0.86), demonstrated superior performance of the Generative Representational Instruction Tuning Language Model-7B model.
Conclusions: This study introduces an innovative use of LLMs in psychiatry, showcasing their potential to objectively examine language use for distinguishing between different psychiatric disorders. The findings highlight the capability of LLMs to offer valuable insights into the linguistic patterns unique to various conditions, paving the way for more efficient, patient-focused diagnostic and monitoring strategies. Future research should aim to validate these results with clinically confirmed populations and investigate the implications of comorbidity and spectrum disorders.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


