The Diagnostic Performance of Large Language Models and Oral Medicine Consultants for Identifying Oral Lesions in Text-Based Clinical Scenarios: Prospective Comparative Study.
Sarah AlFarabi Ali, Hebah AlDehlawi, Ahoud Jazzar, Heba Ashi, Nihal Esam Abuzinadah, Mohammad AlOtaibi, Abdulrahman Algarni, Hazzaa Alqahtani, Sara Akeel, Soulafa Almazrooa
{"title":"The Diagnostic Performance of Large Language Models and Oral Medicine Consultants for Identifying Oral Lesions in Text-Based Clinical Scenarios: Prospective Comparative Study.","authors":"Sarah AlFarabi Ali, Hebah AlDehlawi, Ahoud Jazzar, Heba Ashi, Nihal Esam Abuzinadah, Mohammad AlOtaibi, Abdulrahman Algarni, Hazzaa Alqahtani, Sara Akeel, Soulafa Almazrooa","doi":"10.2196/70566","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The use of artificial intelligence (AI), especially large language models (LLMs), is increasing in health care, including in dentistry. There has yet to be an assessment of the diagnostic performance of LLMs in oral medicine.</p><p><strong>Objective: </strong>We aimed to compare the effectiveness of ChatGPT (OpenAI) and Microsoft Copilot (integrated within the Microsoft 365 suite) with oral medicine consultants in formulating accurate differential and final diagnoses for oral lesions from written clinical scenarios.</p><p><strong>Methods: </strong>Fifty comprehensive clinical case scenarios including patient age, presenting complaint, history of the presenting complaint, medical history, allergies, intra- and extraoral findings, lesion description, and any additional information including laboratory investigations and specific clinical features were given to three oral medicine consultants, who were asked to formulate a differential diagnosis and a final diagnosis. Specific prompts for the same 50 cases were designed and input into ChatGPT and Copilot to formulate both differential and final diagnoses. The diagnostic accuracy was compared between the LLMs and oral medicine consultants.</p><p><strong>Results: </strong>ChatGPT exhibited the highest accuracy, providing the correct differential diagnoses in 37 of 50 cases (74%). There were no significant differences in the accuracy of providing the correct differential diagnoses between AI models and oral medicine consultants. ChatGPT was as accurate as consultants in making the final diagnoses, but Copilot was significantly less accurate than ChatGPT (P=.015) and one of the oral medicine consultants (P<.001) in providing the correct final diagnosis.</p><p><strong>Conclusions: </strong>ChatGPT and Copilot show promising performance for diagnosing oral medicine pathology in clinical case scenarios to assist dental practitioners. ChatGPT-4 and Copilot are still evolving, but even now, they might provide a significant advantage in the clinical setting as tools to help dental practitioners in their daily practice.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e70566"},"PeriodicalIF":2.0000,"publicationDate":"2025-04-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12223689/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/70566","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The use of artificial intelligence (AI), especially large language models (LLMs), is increasing in health care, including in dentistry. There has yet to be an assessment of the diagnostic performance of LLMs in oral medicine.
Objective: We aimed to compare the effectiveness of ChatGPT (OpenAI) and Microsoft Copilot (integrated within the Microsoft 365 suite) with oral medicine consultants in formulating accurate differential and final diagnoses for oral lesions from written clinical scenarios.
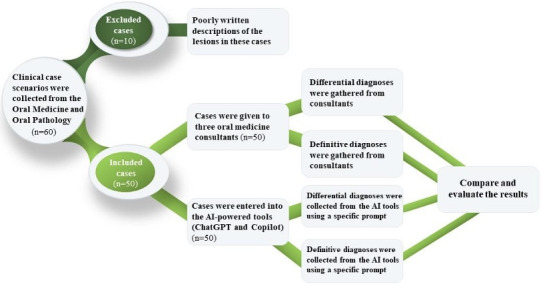
Methods: Fifty comprehensive clinical case scenarios including patient age, presenting complaint, history of the presenting complaint, medical history, allergies, intra- and extraoral findings, lesion description, and any additional information including laboratory investigations and specific clinical features were given to three oral medicine consultants, who were asked to formulate a differential diagnosis and a final diagnosis. Specific prompts for the same 50 cases were designed and input into ChatGPT and Copilot to formulate both differential and final diagnoses. The diagnostic accuracy was compared between the LLMs and oral medicine consultants.
Results: ChatGPT exhibited the highest accuracy, providing the correct differential diagnoses in 37 of 50 cases (74%). There were no significant differences in the accuracy of providing the correct differential diagnoses between AI models and oral medicine consultants. ChatGPT was as accurate as consultants in making the final diagnoses, but Copilot was significantly less accurate than ChatGPT (P=.015) and one of the oral medicine consultants (P<.001) in providing the correct final diagnosis.
Conclusions: ChatGPT and Copilot show promising performance for diagnosing oral medicine pathology in clinical case scenarios to assist dental practitioners. ChatGPT-4 and Copilot are still evolving, but even now, they might provide a significant advantage in the clinical setting as tools to help dental practitioners in their daily practice.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


