{"title":"Supervised Natural Language Processing Classification of Violent Death Narratives: Development and Assessment of a Compact Large Language Model.","authors":"Susan T Parker","doi":"10.2196/68212","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The recent availability of law enforcement and coroner or medical examiner reports for nearly every violent death in the United States expands the potential for natural language processing (NLP) research into violence.</p><p><strong>Objective: </strong>The objective of this work is to assess applications of supervised NLP to unstructured data in the National Violent Death Reporting System to predict circumstances and types of violent death.</p><p><strong>Methods: </strong>This analysis applied distilBERT, a compact large language model (LLM) with fewer parameters relative to full-scale LLMs, to unstructured narrative data to simulate the impacts of preprocessing, volume, and composition of training data on model performance, evaluated by F1-scores, precision, recall, and the false negative rate. Model performance was evaluated for bias by race, ethnicity, and sex by comparing F1-scores across subgroups.</p><p><strong>Results: </strong>A minimum training set of 1500 cases was necessary to achieve an F1-score of 0.6 and a false negative rate of 0.01-0.05 with a compact LLM. Replacement of domain-specific jargon improved model performance, while oversampling positive class cases to address class imbalance did not substantially improve F1-scores. Between racial and ethnic groups, F1-score disparities ranged from 0.2 to 0.25, and between male and female decedents, differences ranged from 0.12 to 0.2.</p><p><strong>Conclusions: </strong>Compact LLMs with sufficient training data can be applied to supervised NLP tasks with a class imbalance in the National Violent Death Reporting System. Simulations of supervised text classification across the model-fitting process of preprocessing and training compact LLM-informed NLP applications to unstructured death narrative data.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e68212"},"PeriodicalIF":2.0000,"publicationDate":"2025-06-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12223685/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/68212","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The recent availability of law enforcement and coroner or medical examiner reports for nearly every violent death in the United States expands the potential for natural language processing (NLP) research into violence.
Objective: The objective of this work is to assess applications of supervised NLP to unstructured data in the National Violent Death Reporting System to predict circumstances and types of violent death.
Methods: This analysis applied distilBERT, a compact large language model (LLM) with fewer parameters relative to full-scale LLMs, to unstructured narrative data to simulate the impacts of preprocessing, volume, and composition of training data on model performance, evaluated by F1-scores, precision, recall, and the false negative rate. Model performance was evaluated for bias by race, ethnicity, and sex by comparing F1-scores across subgroups.
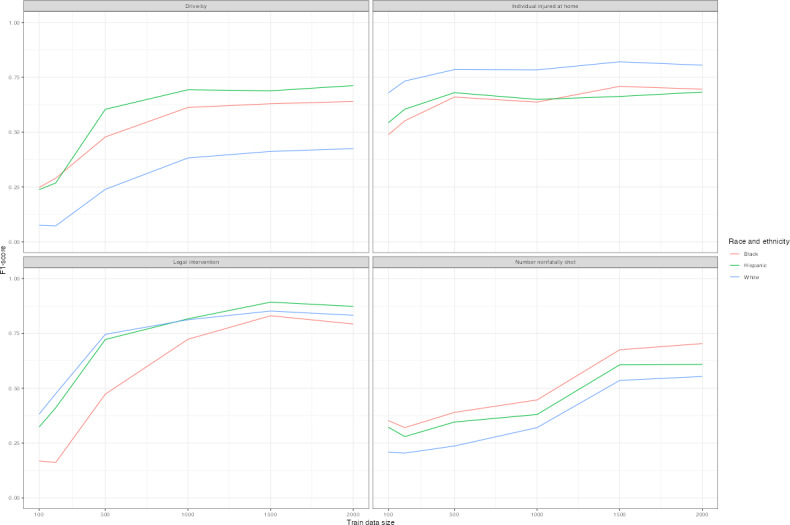
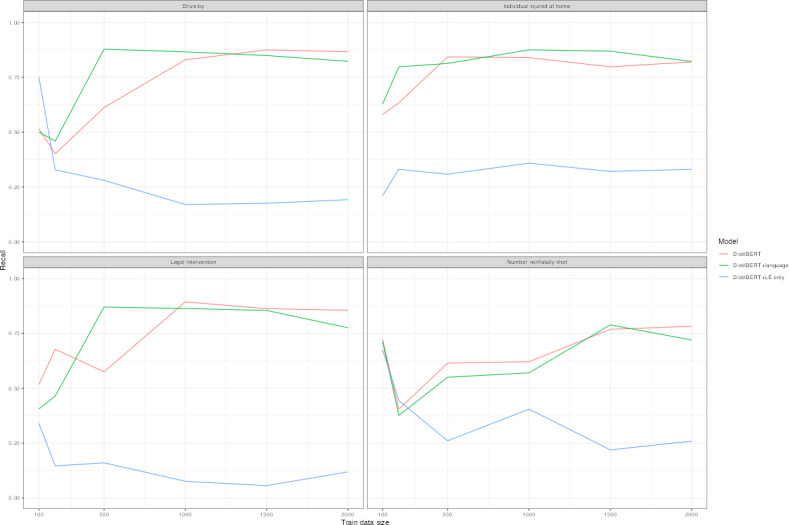
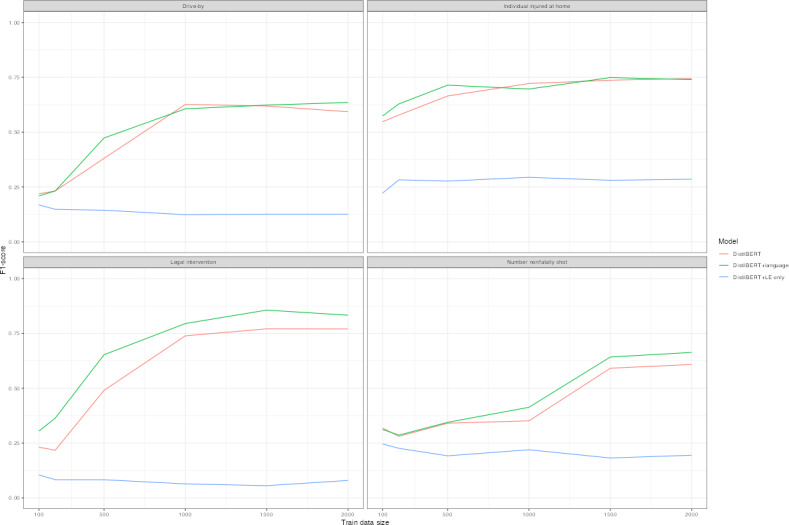
Results: A minimum training set of 1500 cases was necessary to achieve an F1-score of 0.6 and a false negative rate of 0.01-0.05 with a compact LLM. Replacement of domain-specific jargon improved model performance, while oversampling positive class cases to address class imbalance did not substantially improve F1-scores. Between racial and ethnic groups, F1-score disparities ranged from 0.2 to 0.25, and between male and female decedents, differences ranged from 0.12 to 0.2.
Conclusions: Compact LLMs with sufficient training data can be applied to supervised NLP tasks with a class imbalance in the National Violent Death Reporting System. Simulations of supervised text classification across the model-fitting process of preprocessing and training compact LLM-informed NLP applications to unstructured death narrative data.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


