Angel Manuel Garcia-Carmona, Maria-Lorena Prieto, Enrique Puertas, Juan-Jose Beunza
{"title":"Leveraging Large Language Models for Accurate Retrieval of Patient Information From Medical Reports: Systematic Evaluation Study.","authors":"Angel Manuel Garcia-Carmona, Maria-Lorena Prieto, Enrique Puertas, Juan-Jose Beunza","doi":"10.2196/68776","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The digital transformation of health care has introduced both opportunities and challenges, particularly in managing and analyzing the vast amounts of unstructured medical data generated daily. There is a need to explore the feasibility of generative solutions in extracting data from medical reports, categorized by specific criteria.</p><p><strong>Objective: </strong>This study aimed to investigate the application of large language models (LLMs) for the automated extraction of structured information from unstructured medical reports, using the LangChain framework in Python.</p><p><strong>Methods: </strong>Through a systematic evaluation of leading LLMs-GPT-4o, Llama 3, Llama 3.1, Gemma 2, Qwen 2, and Qwen 2.5-using zero-shot prompting techniques and embedding results into a vector database, this study assessed the performance of LLMs in extracting patient demographics, diagnostic details, and pharmacological data.</p><p><strong>Results: </strong>Evaluation metrics, including accuracy, precision, recall, and F<sub>1</sub>-score, revealed high efficacy across most categories, with GPT-4o achieving the highest overall performance (91.4% accuracy).</p><p><strong>Conclusions: </strong>The findings highlight notable differences in precision and recall between models, particularly in extracting names and age-related information. There were challenges in processing unstructured medical text, including variability in model performance across data types. Our findings demonstrate the feasibility of integrating LLMs into health care workflows; LLMs offer substantial improvements in data accessibility and support clinical decision-making processes. In addition, the paper describes the role of retrieval-augmented generation techniques in enhancing information retrieval accuracy, addressing issues such as hallucinations and outdated data in LLM outputs. Future work should explore the need for optimization through larger and more diverse training datasets, advanced prompting strategies, and the integration of domain-specific knowledge to improve model generalizability and precision.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e68776"},"PeriodicalIF":2.0000,"publicationDate":"2025-07-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12271962/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/68776","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The digital transformation of health care has introduced both opportunities and challenges, particularly in managing and analyzing the vast amounts of unstructured medical data generated daily. There is a need to explore the feasibility of generative solutions in extracting data from medical reports, categorized by specific criteria.
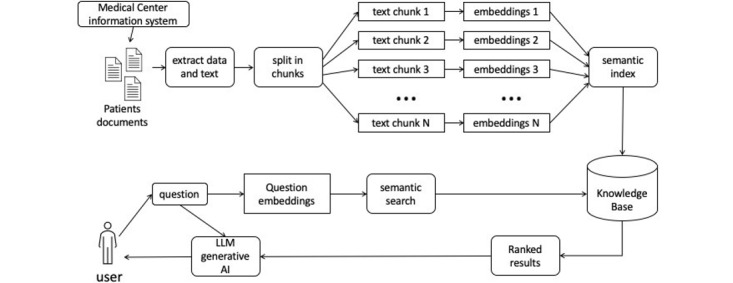
Objective: This study aimed to investigate the application of large language models (LLMs) for the automated extraction of structured information from unstructured medical reports, using the LangChain framework in Python.
Methods: Through a systematic evaluation of leading LLMs-GPT-4o, Llama 3, Llama 3.1, Gemma 2, Qwen 2, and Qwen 2.5-using zero-shot prompting techniques and embedding results into a vector database, this study assessed the performance of LLMs in extracting patient demographics, diagnostic details, and pharmacological data.
Results: Evaluation metrics, including accuracy, precision, recall, and F1-score, revealed high efficacy across most categories, with GPT-4o achieving the highest overall performance (91.4% accuracy).
Conclusions: The findings highlight notable differences in precision and recall between models, particularly in extracting names and age-related information. There were challenges in processing unstructured medical text, including variability in model performance across data types. Our findings demonstrate the feasibility of integrating LLMs into health care workflows; LLMs offer substantial improvements in data accessibility and support clinical decision-making processes. In addition, the paper describes the role of retrieval-augmented generation techniques in enhancing information retrieval accuracy, addressing issues such as hallucinations and outdated data in LLM outputs. Future work should explore the need for optimization through larger and more diverse training datasets, advanced prompting strategies, and the integration of domain-specific knowledge to improve model generalizability and precision.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


