Metric-based defect prediction from class diagram
IF 4.5
Q2 COMPUTER SCIENCE, THEORY & METHODS
引用次数: 0
Abstract
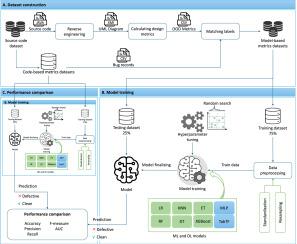
A software defect refers to a fault, failure, or error in software. With the rapid development and increasing reliance on software products, it is essential to identify these defects as early and easily as possible, given the efforts and budget invested in their creation and maintenance. In the literature, various approaches such as machine learning (ML) and deep learning (DL), have been proposed and proven effective in detecting defects in source code during the implementation or testing phases of the software development life cycle (SDLC). A promising approach is crucial for predicting defects at earlier stages of the SDLC, particularly during the design phase, with the goal of enhancing software quality while reducing time, effort, and costs. Meanwhile, software metrics provide a quantifiable way to analyze the software, making it easier to identify defects. Many researchers have leveraged these metrics to predict defects using ML and DL methods, achieving state-of-the-art performance. The objective of this paper is to present a novel approach to predict defects in class diagram (i.e., at design stage) using ML and DL with software metrics. Due to a lack of defect datasets extracted from class diagram, firstly, we created a model-based metric dataset using reverse engineering from a code-based dataset. Then, we apply various ML and DL techniques to the newly created dataset to predict defects in classes by classifying them as either defective or clean. The study utilizes a large dataset called the Unified Bug Dataset, which comprises five publicly available sub-datasets. We compare ML and DL models in terms of accuracy, precision, recall, F-measure, AUC and provide a performance comparison against code-based methods. Finally, we conducted a cross-dataset experiment to evaluate the generalizability of our approach.
来自类图的基于度量的缺陷预测
软件缺陷是指软件中的错误、失败或错误。随着快速的开发和对软件产品的日益依赖,考虑到在它们的创建和维护中投入的努力和预算,尽早和尽可能容易地识别这些缺陷是至关重要的。在文献中,各种方法,如机器学习(ML)和深度学习(DL),已经被提出并证明在软件开发生命周期(SDLC)的实现或测试阶段有效地检测源代码中的缺陷。有希望的方法对于在SDLC的早期阶段预测缺陷是至关重要的,特别是在设计阶段,其目标是在减少时间、工作和成本的同时提高软件质量。同时,软件度量提供了一种可量化的方法来分析软件,使得识别缺陷变得更容易。许多研究人员已经利用这些度量来使用ML和DL方法预测缺陷,实现了最先进的性能。本文的目的是提出一种新的方法来预测类图中的缺陷(即,在设计阶段),使用带有软件度量的ML和DL。由于缺乏从类图中提取的缺陷数据集,首先,我们使用基于代码的数据集的反向工程创建了一个基于模型的度量数据集。然后,我们将各种ML和DL技术应用于新创建的数据集,通过将它们分类为有缺陷的或干净的来预测类中的缺陷。该研究使用了一个名为统一Bug数据集的大型数据集,其中包括五个公开可用的子数据集。我们在准确性、精密度、召回率、F-measure、AUC方面比较ML和DL模型,并提供与基于代码的方法的性能比较。最后,我们进行了一个跨数据集实验来评估我们的方法的泛化性。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


