Yao-Shun Chuang, Chun-Teh Lee, Guo-Hao Lin, Ryan Brandon, Xiaoqian Jiang, Muhammad F Walji, Oluwabunmi Tokede
{"title":"Cross-institutional dental electronic health record entity extraction via generative artificial intelligence and synthetic notes.","authors":"Yao-Shun Chuang, Chun-Teh Lee, Guo-Hao Lin, Ryan Brandon, Xiaoqian Jiang, Muhammad F Walji, Oluwabunmi Tokede","doi":"10.1093/jamiaopen/ooaf061","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>While most health-care providers now use electronic health records (EHRs) to document clinical care, many still treat them as digital versions of paper records. As a result, documentation often remains unstructured, with free-text entries in progress notes. This limits the potential for secondary use and analysis, as machine-learning and data analysis algorithms are more effective with structured data.</p><p><strong>Objective: </strong>This study aims to use advanced artificial intelligence (AI) and natural language processing (NLP) techniques to improve diagnostic information extraction from clinical notes in a periodontal use case. By automating this process, the study seeks to reduce missing data in dental records and minimize the need for extensive manual annotation, a long-standing barrier to widespread NLP deployment in dental data extraction.</p><p><strong>Materials and methods: </strong>This research utilizes large language models (LLMs), specifically Generative Pretrained Transformer 4, to generate synthetic medical notes for fine-tuning a RoBERTa model. This model was trained to better interpret and process dental language, with particular attention to periodontal diagnoses. Model performance was evaluated by manually reviewing 360 clinical notes randomly selected from each of the participating site's dataset.</p><p><strong>Results: </strong>The results demonstrated high accuracy of periodontal diagnosis data extraction, with the sites 1 and 2 achieving a weighted average score of 0.97-0.98. This performance held for all dimensions of periodontal diagnosis in terms of stage, grade, and extent.</p><p><strong>Discussion: </strong>Synthetic data effectively reduced manual annotation needs while preserving model quality. Generalizability across institutions suggests viability for broader adoption, though future work is needed to improve contextual understanding.</p><p><strong>Conclusion: </strong>The study highlights the potential transformative impact of AI and NLP on health-care research. Most clinical documentation (40%-80%) is free text. Scaling our method could enhance clinical data reuse.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"8 3","pages":"ooaf061"},"PeriodicalIF":3.4000,"publicationDate":"2025-06-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12205731/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooaf061","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/6/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Background: While most health-care providers now use electronic health records (EHRs) to document clinical care, many still treat them as digital versions of paper records. As a result, documentation often remains unstructured, with free-text entries in progress notes. This limits the potential for secondary use and analysis, as machine-learning and data analysis algorithms are more effective with structured data.
Objective: This study aims to use advanced artificial intelligence (AI) and natural language processing (NLP) techniques to improve diagnostic information extraction from clinical notes in a periodontal use case. By automating this process, the study seeks to reduce missing data in dental records and minimize the need for extensive manual annotation, a long-standing barrier to widespread NLP deployment in dental data extraction.
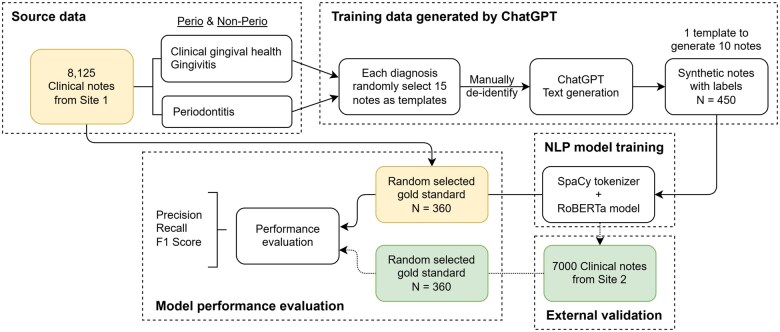
Materials and methods: This research utilizes large language models (LLMs), specifically Generative Pretrained Transformer 4, to generate synthetic medical notes for fine-tuning a RoBERTa model. This model was trained to better interpret and process dental language, with particular attention to periodontal diagnoses. Model performance was evaluated by manually reviewing 360 clinical notes randomly selected from each of the participating site's dataset.
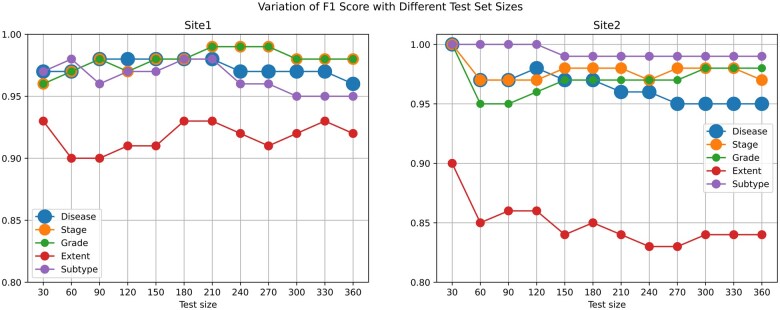
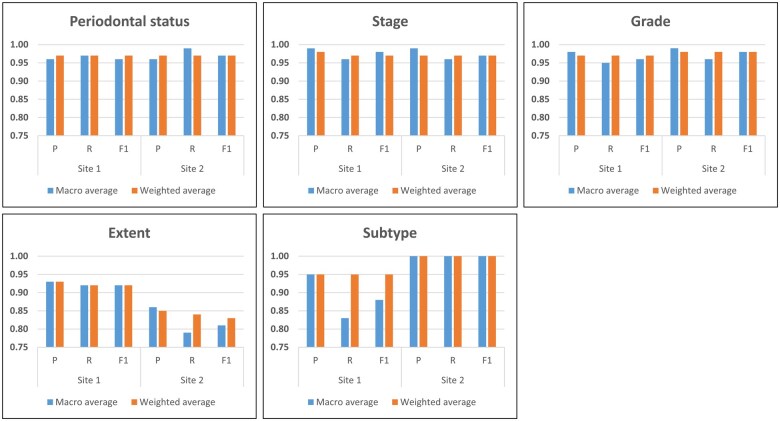
Results: The results demonstrated high accuracy of periodontal diagnosis data extraction, with the sites 1 and 2 achieving a weighted average score of 0.97-0.98. This performance held for all dimensions of periodontal diagnosis in terms of stage, grade, and extent.
Discussion: Synthetic data effectively reduced manual annotation needs while preserving model quality. Generalizability across institutions suggests viability for broader adoption, though future work is needed to improve contextual understanding.
Conclusion: The study highlights the potential transformative impact of AI and NLP on health-care research. Most clinical documentation (40%-80%) is free text. Scaling our method could enhance clinical data reuse.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


