Jerome Niyirora, Lynne Longtin, Cynthia Grabski, David Patrishkoff, Andriana Semko
{"title":"A comparative analysis of machine learning models and human expertise for nursing intervention classification.","authors":"Jerome Niyirora, Lynne Longtin, Cynthia Grabski, David Patrishkoff, Andriana Semko","doi":"10.1093/jamiaopen/ooaf057","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>This study compares the performance of machine learning (ML) models and human experts in mapping unstructured nursing notes to the standardized Nursing Interventions Classification (NIC) system. The aim is to advance automated nursing documentation classification, facilitating cross-facility benchmarking of patient care and organizational outcomes.</p><p><strong>Materials and methods: </strong>We developed and compared 4 ML models: TF-IDF text-based vectorization, UMLS semantic mapping, fine-tuned GPT-4o mini, and Bio-Clinical BERT. These models were evaluated against classifications provided by 2 expert nurses using a dataset of de-identified home healthcare nursing notes obtained from a Florida, USA-based medical clearinghouse. Model performance was assessed using agreement statistics, precision, recall, F1 scores, and Cohen's Kappa.</p><p><strong>Results: </strong>Human raters achieved the highest agreement with consensus labels, scoring 0.75 and 0.62, with corresponding F1 scores of 0.61 and 0.45, respectively. In comparison, ML models showed lower performance, with GPT achieving the best among them (agreement: 0.50, F1 score: 0.31). A distribution analysis of NIC categories revealed that ML models performed well in prevalent and clearly defined categories, such as drug management, but struggled with minority classes and context-dependent interventions, like information management.</p><p><strong>Discussion: </strong>Current ML approaches show promise in supporting clinical classification tasks, but the performance gap in handling complex, context-dependent interventions highlights the need for improved methods that can better capture the nuanced nature of clinical documentation. Future research should focus on developing methods to process clinical terminology and context-specific documentation with greater precision and adaptability.</p><p><strong>Conclusion: </strong>Current ML models can aid-but not fully replace-human judgment in classifying nuanced nursing interventions.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"8 3","pages":"ooaf057"},"PeriodicalIF":3.4000,"publicationDate":"2025-06-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12203540/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooaf057","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/6/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Objective: This study compares the performance of machine learning (ML) models and human experts in mapping unstructured nursing notes to the standardized Nursing Interventions Classification (NIC) system. The aim is to advance automated nursing documentation classification, facilitating cross-facility benchmarking of patient care and organizational outcomes.
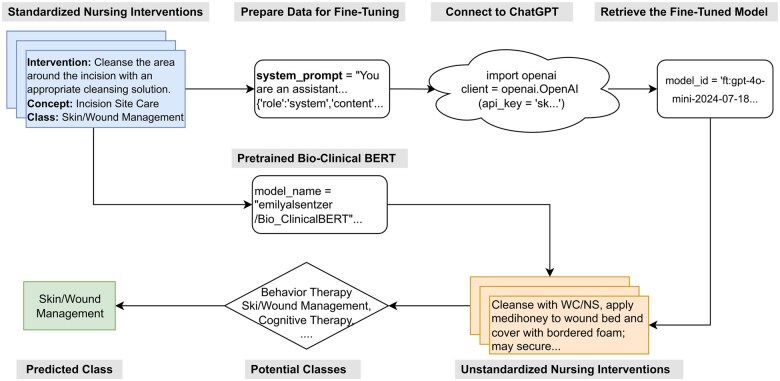
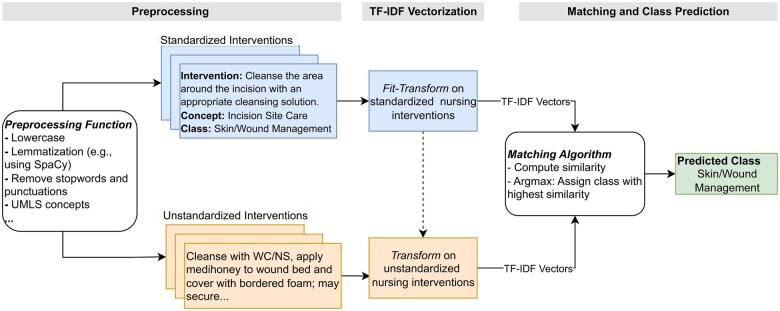
Materials and methods: We developed and compared 4 ML models: TF-IDF text-based vectorization, UMLS semantic mapping, fine-tuned GPT-4o mini, and Bio-Clinical BERT. These models were evaluated against classifications provided by 2 expert nurses using a dataset of de-identified home healthcare nursing notes obtained from a Florida, USA-based medical clearinghouse. Model performance was assessed using agreement statistics, precision, recall, F1 scores, and Cohen's Kappa.
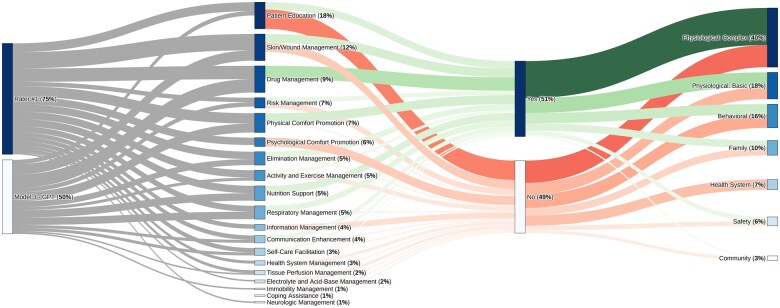
Results: Human raters achieved the highest agreement with consensus labels, scoring 0.75 and 0.62, with corresponding F1 scores of 0.61 and 0.45, respectively. In comparison, ML models showed lower performance, with GPT achieving the best among them (agreement: 0.50, F1 score: 0.31). A distribution analysis of NIC categories revealed that ML models performed well in prevalent and clearly defined categories, such as drug management, but struggled with minority classes and context-dependent interventions, like information management.
Discussion: Current ML approaches show promise in supporting clinical classification tasks, but the performance gap in handling complex, context-dependent interventions highlights the need for improved methods that can better capture the nuanced nature of clinical documentation. Future research should focus on developing methods to process clinical terminology and context-specific documentation with greater precision and adaptability.
Conclusion: Current ML models can aid-but not fully replace-human judgment in classifying nuanced nursing interventions.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


