Francesc Suñol, Candelaria de Haro, Verónica Santos-Pulpón, Sol Fernández-Gonzalo, Lluís Blanch, Josefina López-Aguilar, Leonardo Sarlabous
{"title":"Leveraging large language models for patient-ventilator asynchrony detection.","authors":"Francesc Suñol, Candelaria de Haro, Verónica Santos-Pulpón, Sol Fernández-Gonzalo, Lluís Blanch, Josefina López-Aguilar, Leonardo Sarlabous","doi":"10.1136/bmjhci-2024-101426","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>The objective of this study is to evaluate whether large language models (LLMs) can achieve performance comparable to expert-developed deep neural networks in detecting flow starvation (FS) asynchronies during mechanical ventilation.</p><p><strong>Methods: </strong>Popular LLMs (GPT-4, Claude-3.5, Gemini-1.5, DeepSeek-R1) were tested on a dataset of 6500 airway pressure cycles from 28 patients, classifying breaths into three FS categories. They were also tasked with generating executable code for one-dimensional convolutional neural network (CNN-1D) and Long Short-Term Memory networks. Model performances were assessed using repeated holdout validation and compared with expert-developed models.</p><p><strong>Results: </strong>LLMs performed poorly in direct FS classification (accuracy: GPT-4: 0.497; Claude-3.5: 0.627; Gemini-1.5: 0.544, DeepSeek-R1: 0.520). However, Claude-3.5-generated CNN-1D code achieved the highest accuracy (0.902 (0.899-0.906)), outperforming expert-developed models.</p><p><strong>Discussion: </strong>LLMs demonstrated limited capability in direct classification but excelled in generating effective neural network models with minimal human intervention. This suggests LLMs' potential in accelerating model development for clinical applications, particularly for detecting patient-ventilator asynchronies, though their clinical implementation requires further validation and consideration of ethical factors.</p>","PeriodicalId":9050,"journal":{"name":"BMJ Health & Care Informatics","volume":"32 1","pages":""},"PeriodicalIF":4.4000,"publicationDate":"2025-06-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12207101/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Health & Care Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1136/bmjhci-2024-101426","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: The objective of this study is to evaluate whether large language models (LLMs) can achieve performance comparable to expert-developed deep neural networks in detecting flow starvation (FS) asynchronies during mechanical ventilation.
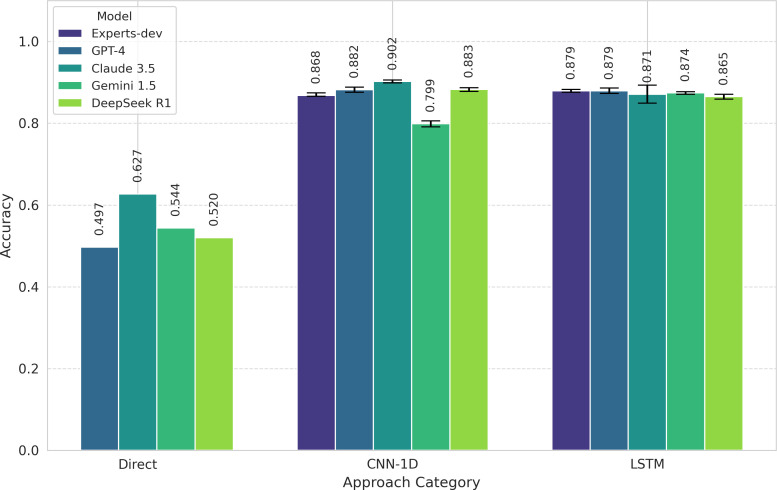
Methods: Popular LLMs (GPT-4, Claude-3.5, Gemini-1.5, DeepSeek-R1) were tested on a dataset of 6500 airway pressure cycles from 28 patients, classifying breaths into three FS categories. They were also tasked with generating executable code for one-dimensional convolutional neural network (CNN-1D) and Long Short-Term Memory networks. Model performances were assessed using repeated holdout validation and compared with expert-developed models.
Results: LLMs performed poorly in direct FS classification (accuracy: GPT-4: 0.497; Claude-3.5: 0.627; Gemini-1.5: 0.544, DeepSeek-R1: 0.520). However, Claude-3.5-generated CNN-1D code achieved the highest accuracy (0.902 (0.899-0.906)), outperforming expert-developed models.
Discussion: LLMs demonstrated limited capability in direct classification but excelled in generating effective neural network models with minimal human intervention. This suggests LLMs' potential in accelerating model development for clinical applications, particularly for detecting patient-ventilator asynchronies, though their clinical implementation requires further validation and consideration of ethical factors.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


