Luca Di Palma, Fatemeh Darvizeh, Marco Alì, Deborah Fazzini
{"title":"Structured Transformation of Unstructured Prostate MRI Reports Using Large Language Models.","authors":"Luca Di Palma, Fatemeh Darvizeh, Marco Alì, Deborah Fazzini","doi":"10.3390/tomography11060069","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>to assess the ability of high-performing open-weight large language models (LLMs) in extracting key radiological features from prostate MRI reports.</p><p><strong>Methods: </strong>Five LLMs (Llama3.3, DeepSeek-R1-Llama3.3, Phi4, Gemma-2, and Qwen2.5-14B) were used to analyze free-text MRI reports retrieved from clinical practice. Each LLM processed reports three times using specialized prompts to extract (1) dimensions, (2) volume and PSA density, and (3) lesion characteristics. An experienced radiologist manually annotated the dataset, defining entities (Exam) and sub-entities (Lesion, Dimension). Feature- and physician-level performance were then assessed.</p><p><strong>Results: </strong>250 MRI exams reported by 7 radiologists were analyzed by the LLMs. Feature-level performances showed that DeepSeek-R1-Llama3.3 exhibited the highest average score (98.6% ± 2.1%), followed by Phi4 (98.1% ± 2.2%), Llama3.3 (98.0% ± 3.0%), Qwen2.5 (97.5% ± 3.9%), and Gemma2 (96.0% ± 3.4%). All models excelled in extracting PSA density (100%) and volume (≥98.4%), while lesions' extraction showed greater variability (88.4-94.0%). LLMs' performance varied among radiologists: Physician B's reports yielded the highest mean score (99.9% ± 0.2%), while Physician C's resulted in the lowest (94.4% ± 2.3%).</p><p><strong>Conclusions: </strong>LLMs showed promising results in automated feature-extraction from radiology reports, with DeepSeek-R1-Llama3.3 achieving the highest overall score. These models can improve clinical workflows by structuring unstructured medical text. However, a preliminary analysis of reporting styles is necessary to identify potential challenges and optimize prompt design to better align with individual physician reporting styles. This approach can further enhance the robustness and adaptability of LLM-driven clinical data extraction.</p>","PeriodicalId":51330,"journal":{"name":"Tomography","volume":"11 6","pages":""},"PeriodicalIF":2.2000,"publicationDate":"2025-06-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12196861/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Tomography","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.3390/tomography11060069","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: to assess the ability of high-performing open-weight large language models (LLMs) in extracting key radiological features from prostate MRI reports.
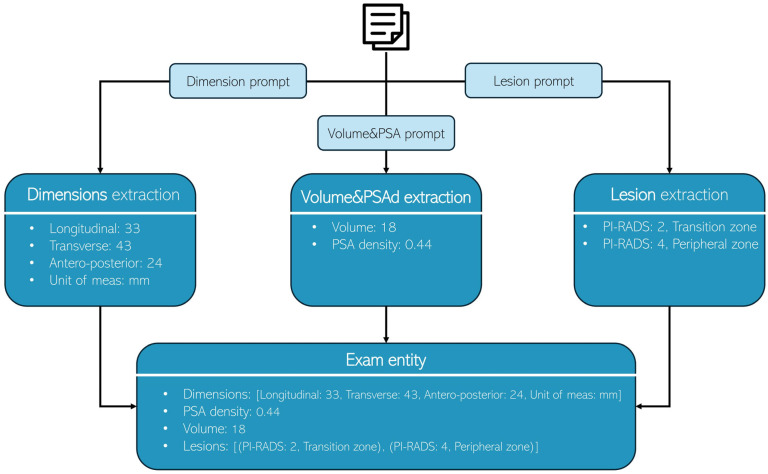
Methods: Five LLMs (Llama3.3, DeepSeek-R1-Llama3.3, Phi4, Gemma-2, and Qwen2.5-14B) were used to analyze free-text MRI reports retrieved from clinical practice. Each LLM processed reports three times using specialized prompts to extract (1) dimensions, (2) volume and PSA density, and (3) lesion characteristics. An experienced radiologist manually annotated the dataset, defining entities (Exam) and sub-entities (Lesion, Dimension). Feature- and physician-level performance were then assessed.
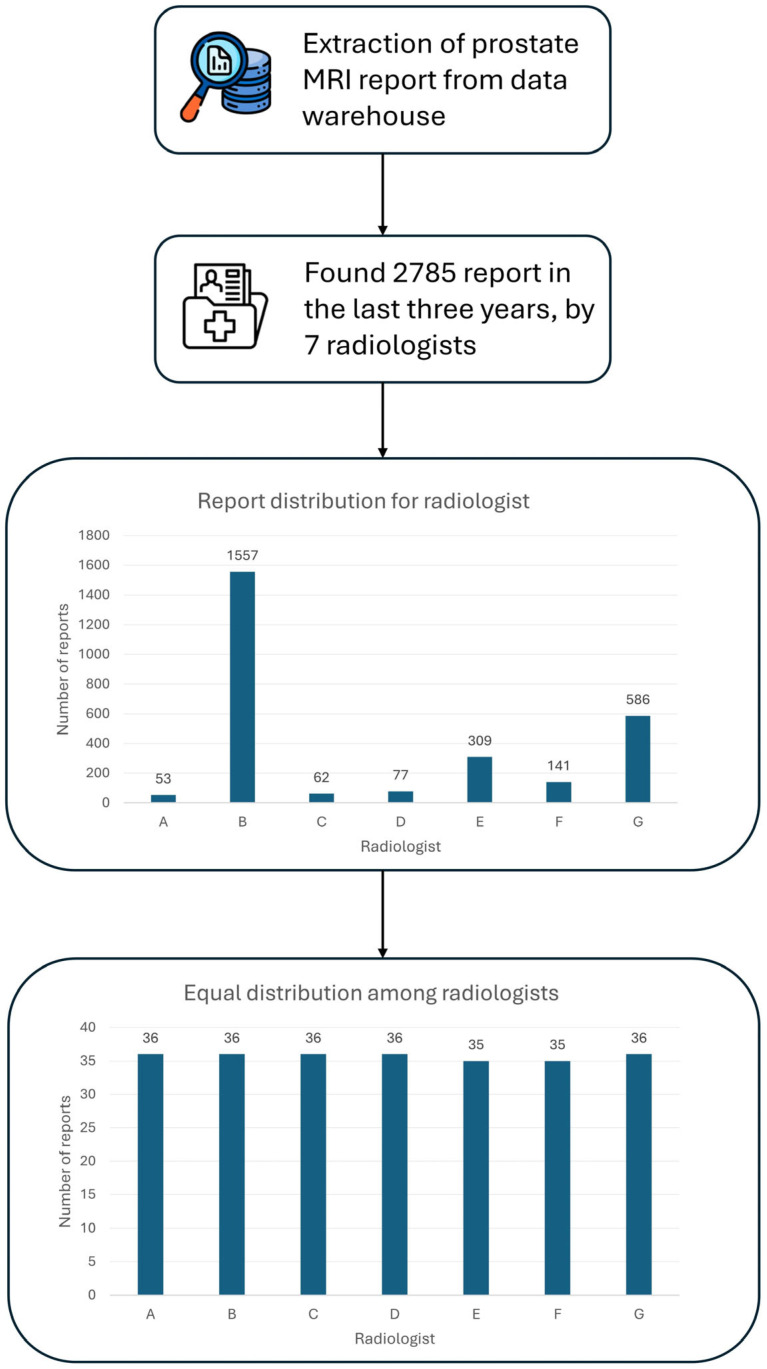
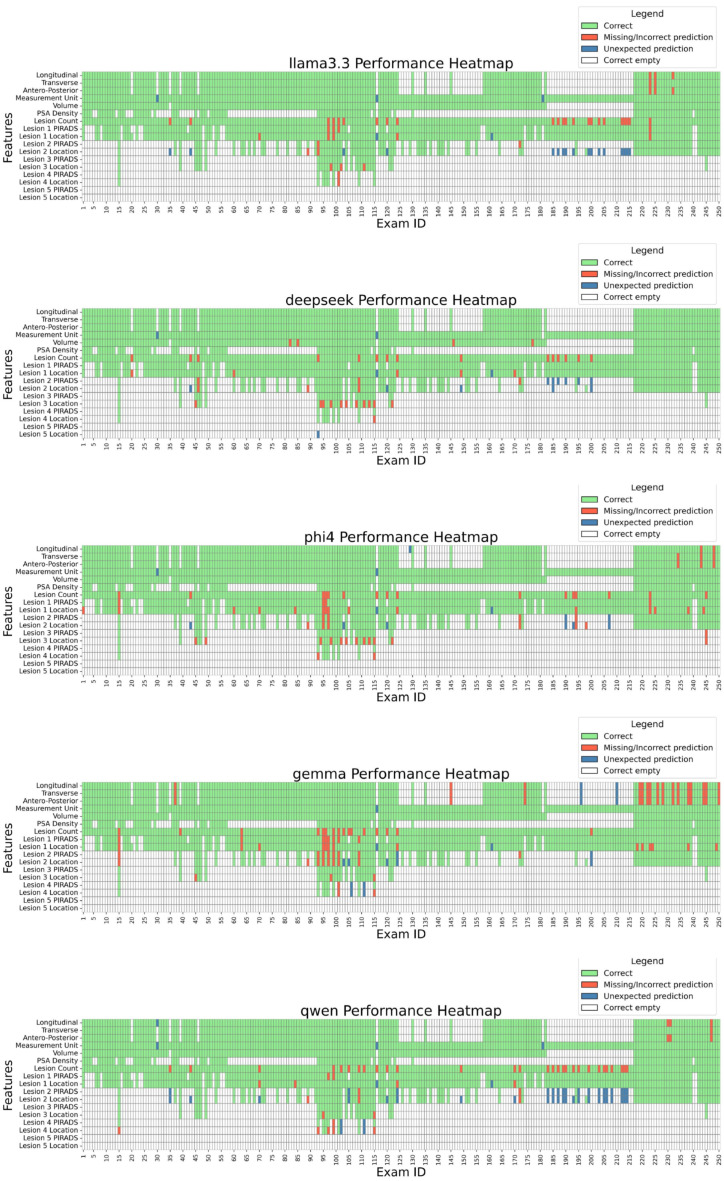
Results: 250 MRI exams reported by 7 radiologists were analyzed by the LLMs. Feature-level performances showed that DeepSeek-R1-Llama3.3 exhibited the highest average score (98.6% ± 2.1%), followed by Phi4 (98.1% ± 2.2%), Llama3.3 (98.0% ± 3.0%), Qwen2.5 (97.5% ± 3.9%), and Gemma2 (96.0% ± 3.4%). All models excelled in extracting PSA density (100%) and volume (≥98.4%), while lesions' extraction showed greater variability (88.4-94.0%). LLMs' performance varied among radiologists: Physician B's reports yielded the highest mean score (99.9% ± 0.2%), while Physician C's resulted in the lowest (94.4% ± 2.3%).
Conclusions: LLMs showed promising results in automated feature-extraction from radiology reports, with DeepSeek-R1-Llama3.3 achieving the highest overall score. These models can improve clinical workflows by structuring unstructured medical text. However, a preliminary analysis of reporting styles is necessary to identify potential challenges and optimize prompt design to better align with individual physician reporting styles. This approach can further enhance the robustness and adaptability of LLM-driven clinical data extraction.
TomographyMedicine-Radiology, Nuclear Medicine and Imaging
CiteScore
2.70
自引率
10.50%
发文量
222
期刊介绍:
TomographyTM publishes basic (technical and pre-clinical) and clinical scientific articles which involve the advancement of imaging technologies. Tomography encompasses studies that use single or multiple imaging modalities including for example CT, US, PET, SPECT, MR and hyperpolarization technologies, as well as optical modalities (i.e. bioluminescence, photoacoustic, endomicroscopy, fiber optic imaging and optical computed tomography) in basic sciences, engineering, preclinical and clinical medicine.
Tomography also welcomes studies involving exploration and refinement of contrast mechanisms and image-derived metrics within and across modalities toward the development of novel imaging probes for image-based feedback and intervention. The use of imaging in biology and medicine provides unparalleled opportunities to noninvasively interrogate tissues to obtain real-time dynamic and quantitative information required for diagnosis and response to interventions and to follow evolving pathological conditions. As multi-modal studies and the complexities of imaging technologies themselves are ever increasing to provide advanced information to scientists and clinicians.
Tomography provides a unique publication venue allowing investigators the opportunity to more precisely communicate integrated findings related to the diverse and heterogeneous features associated with underlying anatomical, physiological, functional, metabolic and molecular genetic activities of normal and diseased tissue. Thus Tomography publishes peer-reviewed articles which involve the broad use of imaging of any tissue and disease type including both preclinical and clinical investigations. In addition, hardware/software along with chemical and molecular probe advances are welcome as they are deemed to significantly contribute towards the long-term goal of improving the overall impact of imaging on scientific and clinical discovery.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


