Shizhao Lu, Tanny Chavez, Wiebke Koepp, Guanhua Hao, Petrus H Zwart, Alexander Hexemer
{"title":"Optimizing inference of segmentation on high-resolution images in MLExchange.","authors":"Shizhao Lu, Tanny Chavez, Wiebke Koepp, Guanhua Hao, Petrus H Zwart, Alexander Hexemer","doi":"10.1007/s11227-025-07413-5","DOIUrl":null,"url":null,"abstract":"<p><p>MLExchange is a machine learning (ML) operations platform providing web user-interfaces (UIs) for data visualization and analysis pipelines at synchrotron facilities. Among these UIs is the segmentation app which helps synchrotron users utilize ML algorithms to automatically segment high-resolution scientific images with minimal manual annotation effort. In this work, we share code optimizations that significantly speed up the segmentation inference workflow of large data in short time. By optimizing the sequence of CPU-GPU data transfers and introducing CPU parallelization to key operations, we improve the per-device, per-image frame computational efficiency and observe close to 3 <math><mo>×</mo></math> speedup over the original segmentation inference workflow run time when utilizing a single GPU. Further adaptations enabling multi-GPU inference yield more than 40 <math><mo>×</mo></math> speedup with 100 GPUs compared to the optimized single GPU inference workflow. This acceleration of the segmentation inference workflow will provide MLExchange users with easy access to segmentation results with little wait time.</p>","PeriodicalId":50034,"journal":{"name":"Journal of Supercomputing","volume":"81 9","pages":"1058"},"PeriodicalIF":2.7000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12181103/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Supercomputing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11227-025-07413-5","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/6/20 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE","Score":null,"Total":0}
引用次数: 0
Abstract
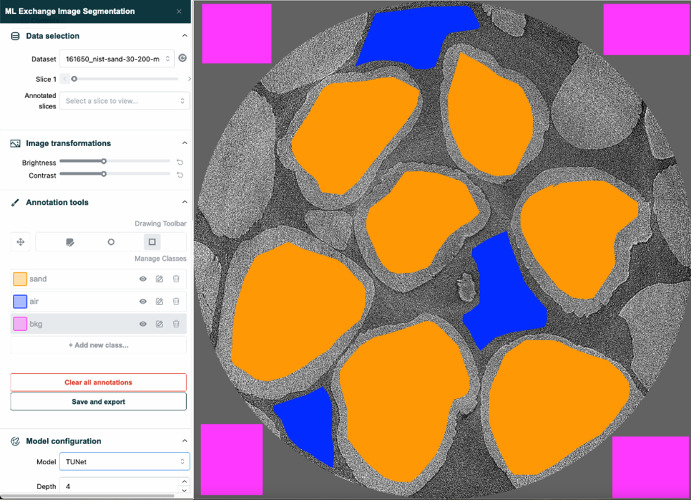
MLExchange is a machine learning (ML) operations platform providing web user-interfaces (UIs) for data visualization and analysis pipelines at synchrotron facilities. Among these UIs is the segmentation app which helps synchrotron users utilize ML algorithms to automatically segment high-resolution scientific images with minimal manual annotation effort. In this work, we share code optimizations that significantly speed up the segmentation inference workflow of large data in short time. By optimizing the sequence of CPU-GPU data transfers and introducing CPU parallelization to key operations, we improve the per-device, per-image frame computational efficiency and observe close to 3 speedup over the original segmentation inference workflow run time when utilizing a single GPU. Further adaptations enabling multi-GPU inference yield more than 40 speedup with 100 GPUs compared to the optimized single GPU inference workflow. This acceleration of the segmentation inference workflow will provide MLExchange users with easy access to segmentation results with little wait time.
期刊介绍:
The Journal of Supercomputing publishes papers on the technology, architecture and systems, algorithms, languages and programs, performance measures and methods, and applications of all aspects of Supercomputing. Tutorial and survey papers are intended for workers and students in the fields associated with and employing advanced computer systems. The journal also publishes letters to the editor, especially in areas relating to policy, succinct statements of paradoxes, intuitively puzzling results, partial results and real needs.
Published theoretical and practical papers are advanced, in-depth treatments describing new developments and new ideas. Each includes an introduction summarizing prior, directly pertinent work that is useful for the reader to understand, in order to appreciate the advances being described.



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


