Xiongbin Gui, Hanlin Lv, Xiao Wang, Longting Lv, Yi Xiao, Lei Wang
{"title":"Enhancing hepatopathy clinical trial efficiency: a secure, large language model-powered pre-screening pipeline.","authors":"Xiongbin Gui, Hanlin Lv, Xiao Wang, Longting Lv, Yi Xiao, Lei Wang","doi":"10.1186/s13040-025-00458-5","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Recruitment for cohorts involving complex liver diseases, such as hepatocellular carcinoma and liver cirrhosis, often requires interpreting semantically complex criteria. Traditional manual screening methods are time-consuming and prone to errors. While AI-powered pre-screening offers potential solutions, challenges remain regarding accuracy, efficiency, and data privacy.</p><p><strong>Methods: </strong>We developed a novel patient pre-screening pipeline that leverages clinical expertise to guide the precise, safe, and efficient application of large language models. The pipeline breaks down complex criteria into a series of composite questions and then employs two strategies to perform semantic question-answering through electronic health records: (1) Pathway A, Anthropomorphized Experts' Chain of Thought strategy; and (2) Pathway B, Preset Stances within an Agent Collaboration strategy, particularly in managing complex clinical reasoning scenarios. The pipeline is evaluated on key metrics including precision, recall, time consumption, and counterfactual inference-at both the question and criterion levels.</p><p><strong>Results: </strong>Our pipeline achieved a notable balance of high precision (e.g., 0.921, criteria level) and good overall recall (e.g., ~ 0.82, criteria level), alongside high efficiency (0.44s per task). Pathway B excelled in high-precision complex reasoning (while exhibiting a specific recall profile conducive to accuracy), whereas Pathway A was particularly effective for tasks requiring both robust precision and recall (e.g., direct data extraction), often with faster processing times. Both pathways achieved comparable overall precision while offering different strengths in the precision-recall trade-off. The pipeline showed promising precision-focused results in hepatocellular carcinoma (0.878) and cirrhosis trials (0.843).</p><p><strong>Conclusions: </strong>This data-secure and time-efficient pipeline shows high precision and achieves good recall in hepatopathy trials, providing promising solutions for streamlining clinical trial workflows. Its efficiency, adaptability, and balanced performance profile make it suitable for improving patient recruitment. And its capability to function in resource-constrained environments further enhances its utility in clinical settings.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"18 1","pages":"42"},"PeriodicalIF":6.1000,"publicationDate":"2025-06-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12167571/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-025-00458-5","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Recruitment for cohorts involving complex liver diseases, such as hepatocellular carcinoma and liver cirrhosis, often requires interpreting semantically complex criteria. Traditional manual screening methods are time-consuming and prone to errors. While AI-powered pre-screening offers potential solutions, challenges remain regarding accuracy, efficiency, and data privacy.
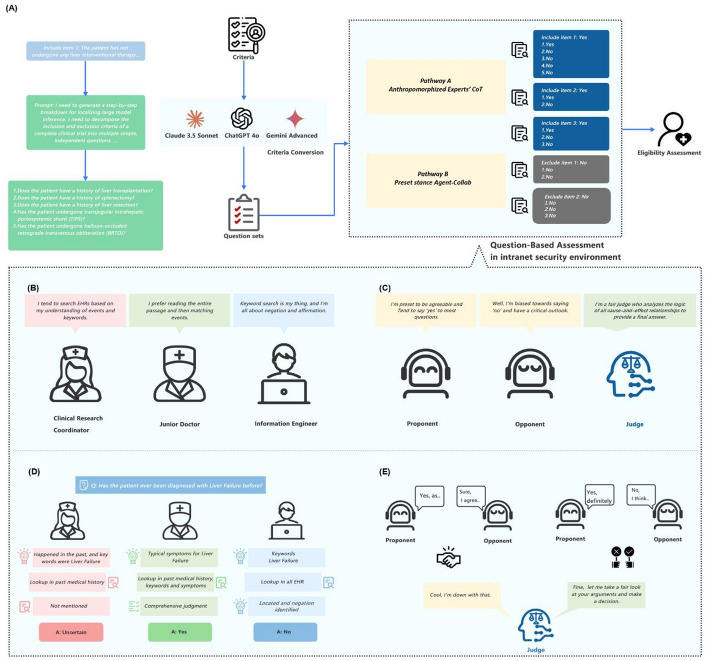
Methods: We developed a novel patient pre-screening pipeline that leverages clinical expertise to guide the precise, safe, and efficient application of large language models. The pipeline breaks down complex criteria into a series of composite questions and then employs two strategies to perform semantic question-answering through electronic health records: (1) Pathway A, Anthropomorphized Experts' Chain of Thought strategy; and (2) Pathway B, Preset Stances within an Agent Collaboration strategy, particularly in managing complex clinical reasoning scenarios. The pipeline is evaluated on key metrics including precision, recall, time consumption, and counterfactual inference-at both the question and criterion levels.
Results: Our pipeline achieved a notable balance of high precision (e.g., 0.921, criteria level) and good overall recall (e.g., ~ 0.82, criteria level), alongside high efficiency (0.44s per task). Pathway B excelled in high-precision complex reasoning (while exhibiting a specific recall profile conducive to accuracy), whereas Pathway A was particularly effective for tasks requiring both robust precision and recall (e.g., direct data extraction), often with faster processing times. Both pathways achieved comparable overall precision while offering different strengths in the precision-recall trade-off. The pipeline showed promising precision-focused results in hepatocellular carcinoma (0.878) and cirrhosis trials (0.843).
Conclusions: This data-secure and time-efficient pipeline shows high precision and achieves good recall in hepatopathy trials, providing promising solutions for streamlining clinical trial workflows. Its efficiency, adaptability, and balanced performance profile make it suitable for improving patient recruitment. And its capability to function in resource-constrained environments further enhances its utility in clinical settings.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


