Yukang Liu, Hua Li, Jianfeng Ouyang, Zhaowen Xue, Min Wang, Hebei He, Bin Song, Xiaofei Zheng, Wenyi Gan
{"title":"Evaluating Large Language Models for Preoperative Patient Education in Superior Capsular Reconstruction: Comparative Study of Claude, GPT, and Gemini.","authors":"Yukang Liu, Hua Li, Jianfeng Ouyang, Zhaowen Xue, Min Wang, Hebei He, Bin Song, Xiaofei Zheng, Wenyi Gan","doi":"10.2196/70047","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Large language models (LLMs) are revolutionizing natural language processing, increasingly applied in clinical settings to enhance preoperative patient education.</p><p><strong>Objective: </strong>This study aimed to evaluate the effectiveness and applicability of various LLMs in preoperative patient education by analyzing their responses to superior capsular reconstruction (SCR)-related inquiries.</p><p><strong>Methods: </strong>In total, 10 sports medicine clinical experts formulated 11 SCR issues and developed preoperative patient education strategies during a webinar, inputting 12 text commands into Claude-3-Opus (Anthropic), GPT-4-Turbo (OpenAI), and Gemini-1.5-Pro (Google DeepMind). A total of 3 experts assessed the language models' responses for correctness, completeness, logic, potential harm, and overall satisfaction, while preoperative education documents were evaluated using DISCERN questionnaire and Patient Education Materials Assessment Tool instruments, and reviewed by 5 postoperative patients for readability and educational value; readability of all responses was also analyzed using the cntext package and py-readability-metrics.</p><p><strong>Results: </strong>Between July 1 and August 17, 2024, sports medicine experts and patients evaluated 33 responses and 3 preoperative patient education documents generated by 3 language models regarding SCR surgery. For the 11 query responses, clinicians rated Gemini significantly higher than Claude in all categories (P<.05) and higher than GPT in completeness, risk avoidance, and overall rating (P<.05). For the 3 educational documents, Gemini's Patient Education Materials Assessment Tool score significantly exceeded Claude's (P=.03), and patients rated Gemini's materials superior in all aspects, with significant differences in educational quality versus Claude (P=.02) and overall satisfaction versus both Claude (P<.01) and GPT (P=.01). GPT had significantly higher readability than Claude on 3 R-based metrics (P<.01). Interrater agreement was high among clinicians and fair among patients.</p><p><strong>Conclusions: </strong>Claude-3-Opus, GPT-4-Turbo, and Gemini-1.5-Pro effectively generated readable presurgical education materials but lacked citations and failed to discuss alternative treatments or the risks of forgoing SCR surgery, highlighting the need for expert oversight when using these LLMs in patient education.</p>","PeriodicalId":73557,"journal":{"name":"JMIR perioperative medicine","volume":"8 ","pages":"e70047"},"PeriodicalIF":0.0000,"publicationDate":"2025-06-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12178570/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR perioperative medicine","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/70047","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Large language models (LLMs) are revolutionizing natural language processing, increasingly applied in clinical settings to enhance preoperative patient education.
Objective: This study aimed to evaluate the effectiveness and applicability of various LLMs in preoperative patient education by analyzing their responses to superior capsular reconstruction (SCR)-related inquiries.
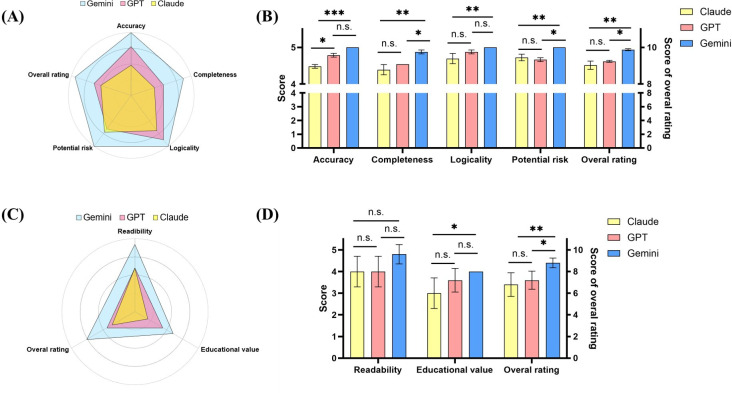
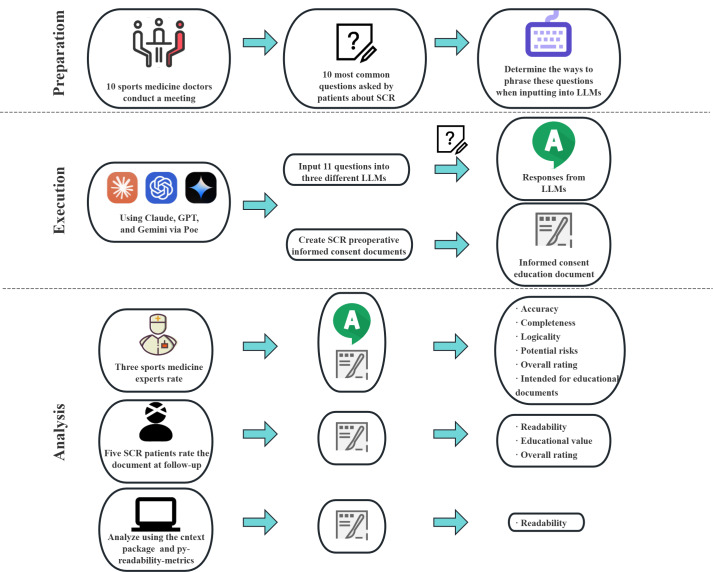
Methods: In total, 10 sports medicine clinical experts formulated 11 SCR issues and developed preoperative patient education strategies during a webinar, inputting 12 text commands into Claude-3-Opus (Anthropic), GPT-4-Turbo (OpenAI), and Gemini-1.5-Pro (Google DeepMind). A total of 3 experts assessed the language models' responses for correctness, completeness, logic, potential harm, and overall satisfaction, while preoperative education documents were evaluated using DISCERN questionnaire and Patient Education Materials Assessment Tool instruments, and reviewed by 5 postoperative patients for readability and educational value; readability of all responses was also analyzed using the cntext package and py-readability-metrics.
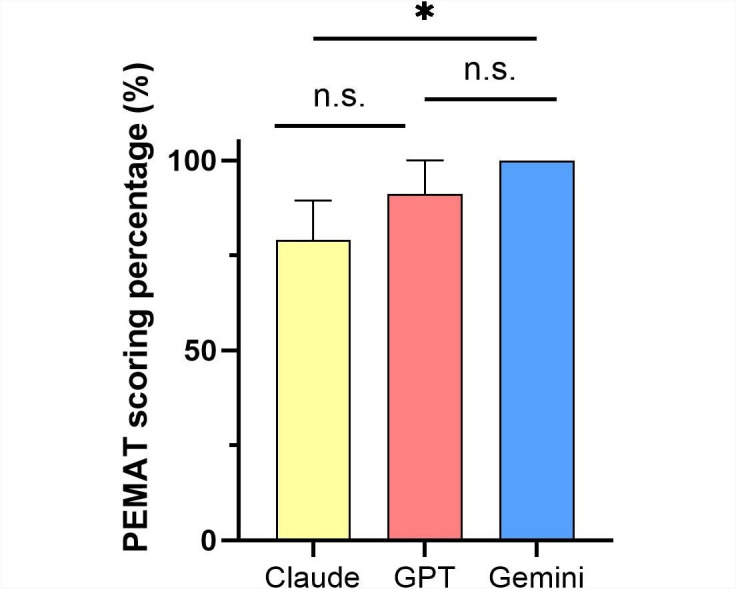
Results: Between July 1 and August 17, 2024, sports medicine experts and patients evaluated 33 responses and 3 preoperative patient education documents generated by 3 language models regarding SCR surgery. For the 11 query responses, clinicians rated Gemini significantly higher than Claude in all categories (P<.05) and higher than GPT in completeness, risk avoidance, and overall rating (P<.05). For the 3 educational documents, Gemini's Patient Education Materials Assessment Tool score significantly exceeded Claude's (P=.03), and patients rated Gemini's materials superior in all aspects, with significant differences in educational quality versus Claude (P=.02) and overall satisfaction versus both Claude (P<.01) and GPT (P=.01). GPT had significantly higher readability than Claude on 3 R-based metrics (P<.01). Interrater agreement was high among clinicians and fair among patients.
Conclusions: Claude-3-Opus, GPT-4-Turbo, and Gemini-1.5-Pro effectively generated readable presurgical education materials but lacked citations and failed to discuss alternative treatments or the risks of forgoing SCR surgery, highlighting the need for expert oversight when using these LLMs in patient education.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


