Mortality Prediction Performance Under Geographical, Temporal, and COVID-19 Pandemic Dataset Shift: External Validation of the Global Open-Source Severity of Illness Score Model.
Takeshi Tohyama, Liam G McCoy, Euma Ishii, Sahil Sood, Jesse Raffa, Takahiro Kinoshita, Leo Anthony Celi, Satoru Hashimoto
{"title":"Mortality Prediction Performance Under Geographical, Temporal, and COVID-19 Pandemic Dataset Shift: External Validation of the Global Open-Source Severity of Illness Score Model.","authors":"Takeshi Tohyama, Liam G McCoy, Euma Ishii, Sahil Sood, Jesse Raffa, Takahiro Kinoshita, Leo Anthony Celi, Satoru Hashimoto","doi":"10.1097/CCE.0000000000001275","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Risk-prediction models are widely used for quality of care evaluations, resource management, and patient stratification in research. While established models have long been used for risk prediction, healthcare has evolved significantly, and the optimal model must be selected for evaluation in line with contemporary healthcare settings and regional considerations.</p><p><strong>Objectives: </strong>To evaluate the geographic and temporal generalizability of the models for mortality prediction in ICUs through external validation in Japan.</p><p><strong>Derivation cohort: </strong>Not applicable.</p><p><strong>Validation cohort: </strong>The care Japanese Intensive care PAtient Database from 2015 to 2022.</p><p><strong>Prediction model: </strong>The Global Open-Source Severity of Illness Score (GOSSIS-1), a modern risk model utilizing machine learning approaches, was compared with conventional models-the Acute Physiology and Chronic Health Evaluation (APACHE-II and APACHE-III)-and a locally calibrated model, the Japan Risk of Death (JROD).</p><p><strong>Results: </strong>Despite the demographic and clinical differences of the validation cohort, GOSSIS-1 maintained strong discrimination, achieving an area under the curve of 0.908, comparable to APACHE-III (0.908) and JROD (0.910). It also exhibited superior calibration, achieving a standardized mortality ratio (SMR) of 0.89 (95% CI, 0.88-0.90), significantly outperforming APACHE-II (SMR, 0.39; 95% CI, 0.39-0.40) and APACHE-III (SMR, 0.46; 95% CI, 0.46-0.47), and demonstrating a performance close to that of JROD (SMR, 0.97; 95% CI, 0.96-0.99). However, performance varied significantly across disease categories, with suboptimal calibration for neurologic conditions and trauma. While the model showed temporal stability from 2015 to 2019, performance deteriorated during the COVID-19 pandemic, broadly reducing performance across disease categories in 2020. This trend was particularly pronounced in GOSSIS compared with APACHE-III.</p><p><strong>Conclusions: </strong>GOSSIS-1 demonstrates robust discrimination despite substantial geographic dataset shift but shows important calibration variations across disease categories. In particular, in a complex model like GOSSIS-1, stresses on the health system, such as a pandemic, can manifest changes in model calibration.</p>","PeriodicalId":93957,"journal":{"name":"Critical care explorations","volume":"7 6","pages":"e1275"},"PeriodicalIF":2.7000,"publicationDate":"2025-06-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12140679/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Critical care explorations","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1097/CCE.0000000000001275","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/6/1 0:00:00","PubModel":"eCollection","JCR":"Q4","JCRName":"Medicine","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Risk-prediction models are widely used for quality of care evaluations, resource management, and patient stratification in research. While established models have long been used for risk prediction, healthcare has evolved significantly, and the optimal model must be selected for evaluation in line with contemporary healthcare settings and regional considerations.
Objectives: To evaluate the geographic and temporal generalizability of the models for mortality prediction in ICUs through external validation in Japan.
Derivation cohort: Not applicable.
Validation cohort: The care Japanese Intensive care PAtient Database from 2015 to 2022.
Prediction model: The Global Open-Source Severity of Illness Score (GOSSIS-1), a modern risk model utilizing machine learning approaches, was compared with conventional models-the Acute Physiology and Chronic Health Evaluation (APACHE-II and APACHE-III)-and a locally calibrated model, the Japan Risk of Death (JROD).
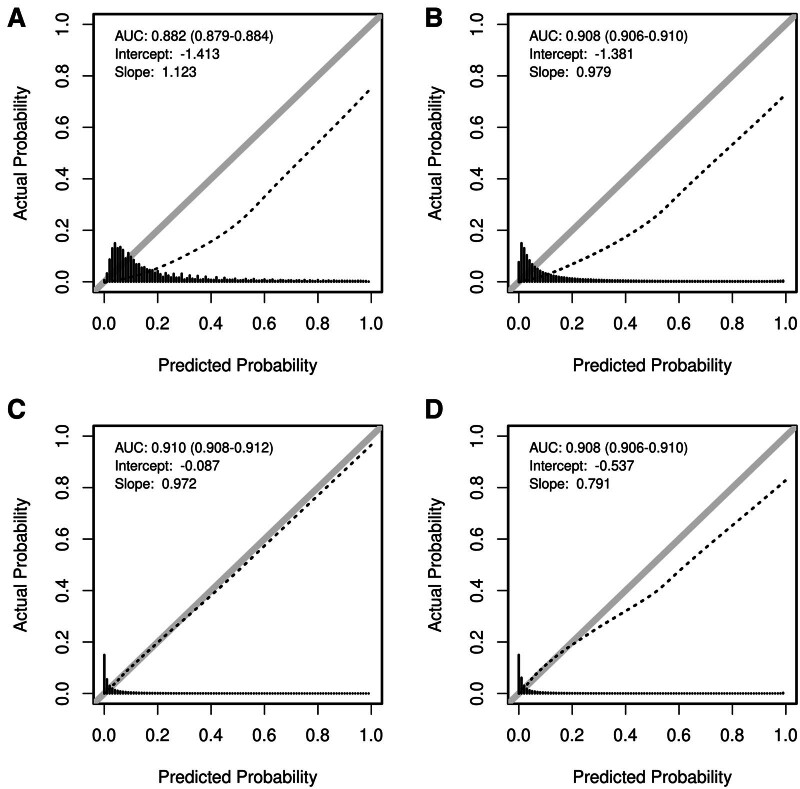
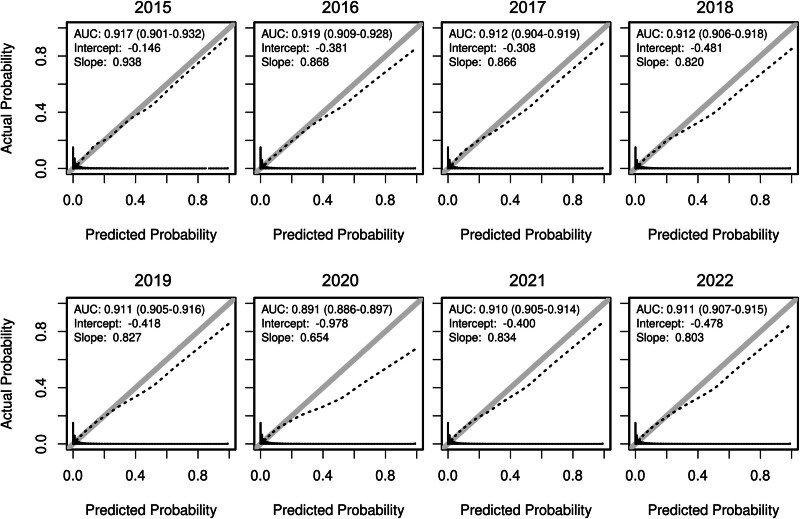
Results: Despite the demographic and clinical differences of the validation cohort, GOSSIS-1 maintained strong discrimination, achieving an area under the curve of 0.908, comparable to APACHE-III (0.908) and JROD (0.910). It also exhibited superior calibration, achieving a standardized mortality ratio (SMR) of 0.89 (95% CI, 0.88-0.90), significantly outperforming APACHE-II (SMR, 0.39; 95% CI, 0.39-0.40) and APACHE-III (SMR, 0.46; 95% CI, 0.46-0.47), and demonstrating a performance close to that of JROD (SMR, 0.97; 95% CI, 0.96-0.99). However, performance varied significantly across disease categories, with suboptimal calibration for neurologic conditions and trauma. While the model showed temporal stability from 2015 to 2019, performance deteriorated during the COVID-19 pandemic, broadly reducing performance across disease categories in 2020. This trend was particularly pronounced in GOSSIS compared with APACHE-III.
Conclusions: GOSSIS-1 demonstrates robust discrimination despite substantial geographic dataset shift but shows important calibration variations across disease categories. In particular, in a complex model like GOSSIS-1, stresses on the health system, such as a pandemic, can manifest changes in model calibration.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


