Markus Hadler, Alexander Ertl, Beate Klösch, Markus Reiter-Haas, Elisabeth Lex
{"title":"The climate gluing protests: analyzing their development and framing in media since 1986 using sentiment analyses and frame detection models.","authors":"Markus Hadler, Alexander Ertl, Beate Klösch, Markus Reiter-Haas, Elisabeth Lex","doi":"10.3389/fdata.2025.1569623","DOIUrl":null,"url":null,"abstract":"<p><p>Recent climate-related protests by social movements such as <i>Extinction Rebellion, Just Stop Oil</i>, and others have included actions like defacing artwork and gluing oneself to objects and streets. Using sentiment analysis and frame detection models, we analyze a corpus of all available English-language news articles in LexisNexis, with the first recorded instance of a gluing protest appearing in 1986. Our study traces the development of this protest tactic over time and addresses three central questions from social movement literature: the use of glue in protests, the geographical spread of this tactic, and the framing of these actions. We find that gluing protests were initially associated with a range of issues-including abortion, criminal justice, and environmental concerns-but in recent years have become more strongly linked to climate activism. Media coverage of these protests is predominantly negative, although public media tends to be comparatively less so. Moreover, protesters' prognostic frames-suggestions for what should be done-are relatively rare, with discourse more often centering on policy and security concerns. From a data science perspective, we explore the use of various Natural Language Processing (NLP) methods. The discussion and conclusion section highlights challenges encountered when working with our corpus and NLP models, and suggests ways to address them in future research. We also consider how recent advancements in large language models (LLMs) could refine or extend these analyses while acknowledging important concerns related to their use.</p>","PeriodicalId":52859,"journal":{"name":"Frontiers in Big Data","volume":"8 ","pages":"1569623"},"PeriodicalIF":2.4000,"publicationDate":"2025-05-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12127360/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Big Data","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fdata.2025.1569623","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
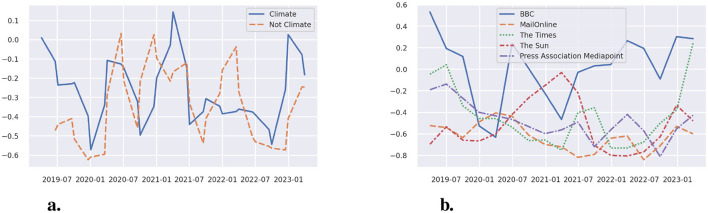
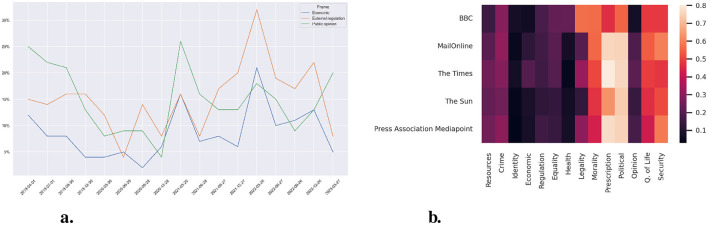
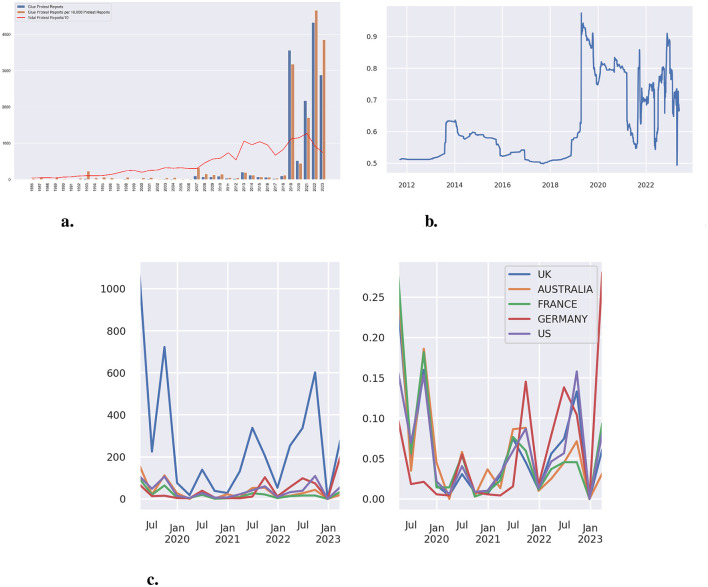
Recent climate-related protests by social movements such as Extinction Rebellion, Just Stop Oil, and others have included actions like defacing artwork and gluing oneself to objects and streets. Using sentiment analysis and frame detection models, we analyze a corpus of all available English-language news articles in LexisNexis, with the first recorded instance of a gluing protest appearing in 1986. Our study traces the development of this protest tactic over time and addresses three central questions from social movement literature: the use of glue in protests, the geographical spread of this tactic, and the framing of these actions. We find that gluing protests were initially associated with a range of issues-including abortion, criminal justice, and environmental concerns-but in recent years have become more strongly linked to climate activism. Media coverage of these protests is predominantly negative, although public media tends to be comparatively less so. Moreover, protesters' prognostic frames-suggestions for what should be done-are relatively rare, with discourse more often centering on policy and security concerns. From a data science perspective, we explore the use of various Natural Language Processing (NLP) methods. The discussion and conclusion section highlights challenges encountered when working with our corpus and NLP models, and suggests ways to address them in future research. We also consider how recent advancements in large language models (LLMs) could refine or extend these analyses while acknowledging important concerns related to their use.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


