Sync-4D: Monocular 4D reconstruction and generation with Synchronized Canonical Distillation
IF 3.1
4区 计算机科学
Q2 COMPUTER SCIENCE, INFORMATION SYSTEMS
Journal of Visual Communication and Image Representation
Pub Date : 2025-05-31
DOI:10.1016/j.jvcir.2025.104483
引用次数: 0
Abstract
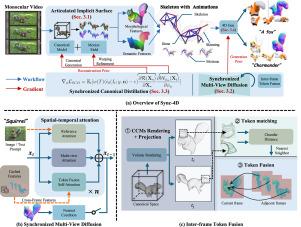
The development of video diffusion models and score distillation techniques has advanced dynamic 3D content generation. However, motion priors from video diffusion models have limited quality and temporal extent. Inspired by motion capture, we propose a text-to-4D framework that generates 4D content using skeletal animations extracted from monocular video. To enhance the 2D diffusion model for temporal-consistent 4D generation, we establish inter-frame token correspondences through canonical coordinate matching and fuse diffusion features. We further propose Synchronized Canonical Distillation (SCD) from a gradient-based perspective. In the score-matching process, SCD computes gradients over articulated models and denoises both the canonical model and motion field synchronously. By accumulating inter-frame and inter-view gradients, SCD mitigates multi-face artifacts and temporal inconsistencies, while diffusion priors further enhance consistency in unobserved regions. Experiments demonstrate that our method outperforms state-of-the-art monocular non-rigid reconstruction and 4D generation methods, achieving a 42.5% lower average Chamfer Distance.
同步四维:单眼四维重建和生成与同步典型蒸馏
视频扩散模型和分数蒸馏技术的发展促进了动态3D内容生成。然而,从视频扩散模型得到的运动先验具有有限的质量和时间范围。受动作捕捉的启发,我们提出了一个文本到4D的框架,使用从单目视频中提取的骨骼动画生成4D内容。为了增强二维扩散模型以实现时间一致的四维生成,我们通过规范坐标匹配和融合扩散特征建立帧间令牌对应关系。我们进一步从基于梯度的角度提出了同步典型蒸馏(SCD)。在分数匹配过程中,SCD计算铰接模型的梯度,并同步去噪规范模型和运动场。通过累积帧间和视图间的梯度,SCD减轻了多面伪影和时间不一致性,而扩散先验进一步增强了未观测区域的一致性。实验表明,我们的方法优于最先进的单眼非刚性重建和4D生成方法,平均倒角距离降低了42.5%。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Journal of Visual Communication and Image Representation
工程技术-计算机:软件工程
CiteScore
5.40
自引率
11.50%
发文量
188
审稿时长
9.9 months
期刊介绍:
The Journal of Visual Communication and Image Representation publishes papers on state-of-the-art visual communication and image representation, with emphasis on novel technologies and theoretical work in this multidisciplinary area of pure and applied research. The field of visual communication and image representation is considered in its broadest sense and covers both digital and analog aspects as well as processing and communication in biological visual systems.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


