Md Sabbir Ahmed, Arafat Rahman, Zhiyuan Wang, Mark Rucker, Laura E Barnes
{"title":"A Resource Efficient System for On-Smartwatch Audio Processing.","authors":"Md Sabbir Ahmed, Arafat Rahman, Zhiyuan Wang, Mark Rucker, Laura E Barnes","doi":"10.1145/3636534.3698866","DOIUrl":null,"url":null,"abstract":"<p><p>While audio data shows promise in addressing various health challenges, there is a lack of research on on-device audio processing for smartwatches. Privacy concerns make storing raw audio and performing post-hoc analysis undesirable for many users. Additionally, current on-device audio processing systems for smartwatches are limited in their feature extraction capabilities, restricting their potential for understanding user behavior and health. We developed a real-time system for on-device audio processing on smartwatches, which takes an average of 1.78 minutes (SD = 0.07 min) to extract 22 spectral and rhythmic features from a 1-minute audio sample, using a small window size of 25 milliseconds. Using these extracted audio features on a public dataset, we developed and incorporated models into a watch to classify foreground and background speech in real-time. Our Random Forest-based model classifies speech with a balanced accuracy of 80.3%.</p>","PeriodicalId":91382,"journal":{"name":"Proceedings of the ... annual International Conference on Mobile Computing and Networking. International Conference on Mobile Computing and Networking","volume":"2024 ","pages":"1805-1807"},"PeriodicalIF":0.0000,"publicationDate":"2024-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12126283/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Proceedings of the ... annual International Conference on Mobile Computing and Networking. International Conference on Mobile Computing and Networking","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1145/3636534.3698866","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/12/4 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
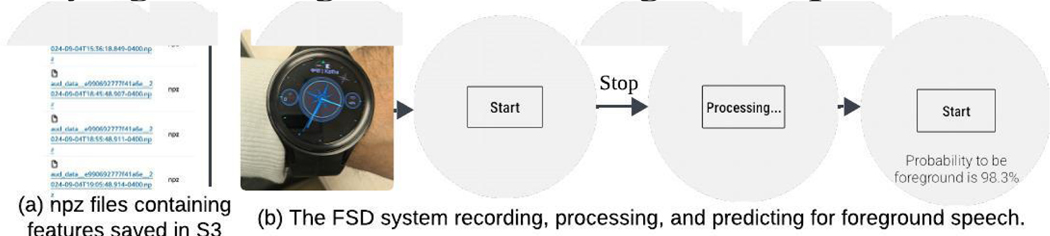
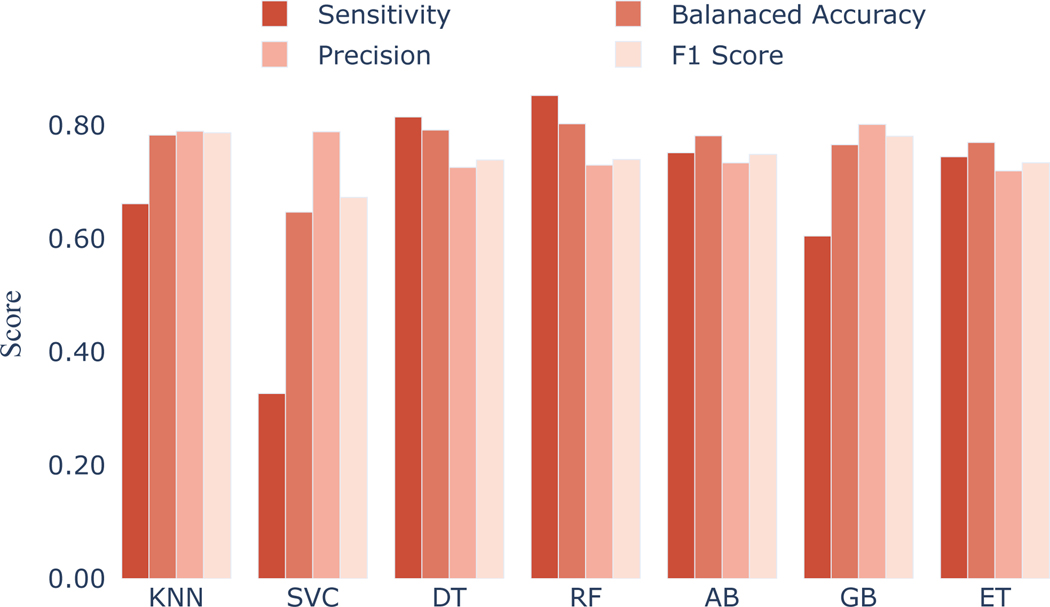
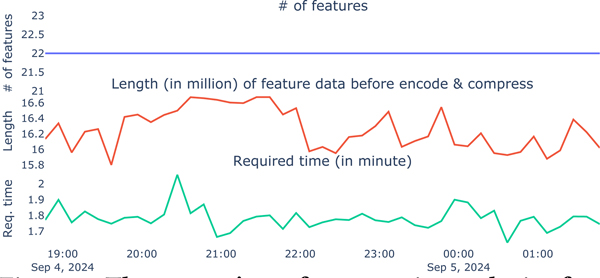
While audio data shows promise in addressing various health challenges, there is a lack of research on on-device audio processing for smartwatches. Privacy concerns make storing raw audio and performing post-hoc analysis undesirable for many users. Additionally, current on-device audio processing systems for smartwatches are limited in their feature extraction capabilities, restricting their potential for understanding user behavior and health. We developed a real-time system for on-device audio processing on smartwatches, which takes an average of 1.78 minutes (SD = 0.07 min) to extract 22 spectral and rhythmic features from a 1-minute audio sample, using a small window size of 25 milliseconds. Using these extracted audio features on a public dataset, we developed and incorporated models into a watch to classify foreground and background speech in real-time. Our Random Forest-based model classifies speech with a balanced accuracy of 80.3%.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


