Corentin Molitor, Timothy Labidi, Antoine Rimbert, Bertrand Cariou, Mathilde Di Filippo, Claire Bardel
{"title":"KILDA: identifying KIV-2 repeats from kmers.","authors":"Corentin Molitor, Timothy Labidi, Antoine Rimbert, Bertrand Cariou, Mathilde Di Filippo, Claire Bardel","doi":"10.1093/nargab/lqaf070","DOIUrl":null,"url":null,"abstract":"<p><p>High concentration of lipoprotein(a) [Lp(a)], a lipoprotein with proatherogenic properties, is an important risk factor for cardiovascular disease. This concentration is mostly genetically determined by a complex interplay between the number of kringle IV type 2 repeats and Lp(a)-affecting variants. Besides Lp(a) plasma concentration, there is an unmet need to identify individuals most at risk based on their <i>LPA</i> genotype. We developed KILDA (KIv2 Length Determined from a kmer Analysis), a Nextflow pipeline, to identify the number of kringle IV type 2 repeats and Lp(a)-affecting variants directly from kmers generated from FASTQ files. The pipeline was tested on the 1000 Genomes Project (<i>n</i> = 2459) and results were equivalent to DRAGEN-LPA (<i>R</i> <sup>2</sup>= 0.92). <i>In silico</i> datasets proved the robustness of KILDA's predictions under different scenarios of sequencing coverage and quality. In brief, KILDA is a robust, open-source, and free-to-use pipeline that can identify the number of kringle IV type 2 repeats and Lp(a)-associated variants even when inputting low-coverage libraries.</p>","PeriodicalId":33994,"journal":{"name":"NAR Genomics and Bioinformatics","volume":"7 2","pages":"lqaf070"},"PeriodicalIF":2.8000,"publicationDate":"2025-05-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12123407/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"NAR Genomics and Bioinformatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/nargab/lqaf070","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/6/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"GENETICS & HEREDITY","Score":null,"Total":0}
引用次数: 0
Abstract
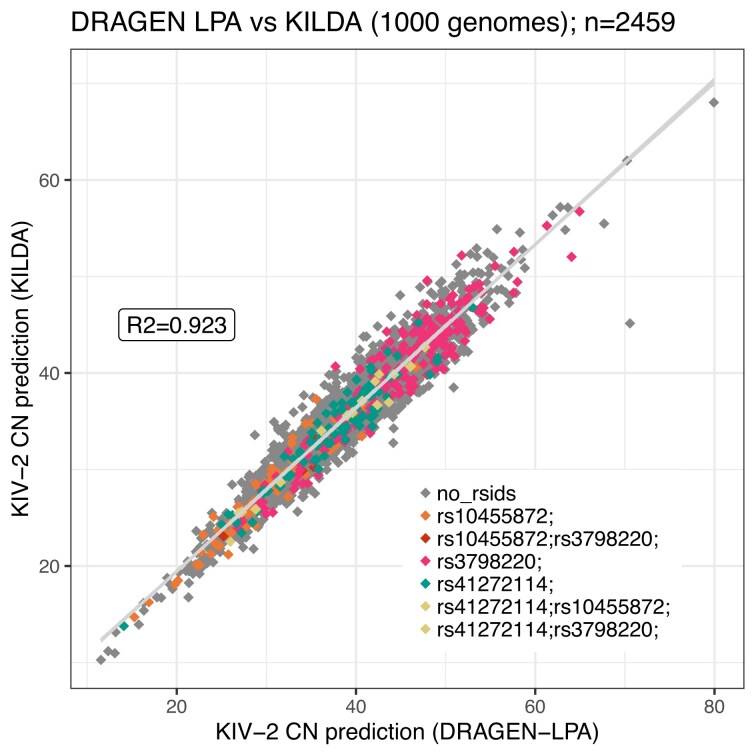
High concentration of lipoprotein(a) [Lp(a)], a lipoprotein with proatherogenic properties, is an important risk factor for cardiovascular disease. This concentration is mostly genetically determined by a complex interplay between the number of kringle IV type 2 repeats and Lp(a)-affecting variants. Besides Lp(a) plasma concentration, there is an unmet need to identify individuals most at risk based on their LPA genotype. We developed KILDA (KIv2 Length Determined from a kmer Analysis), a Nextflow pipeline, to identify the number of kringle IV type 2 repeats and Lp(a)-affecting variants directly from kmers generated from FASTQ files. The pipeline was tested on the 1000 Genomes Project (n = 2459) and results were equivalent to DRAGEN-LPA (R2= 0.92). In silico datasets proved the robustness of KILDA's predictions under different scenarios of sequencing coverage and quality. In brief, KILDA is a robust, open-source, and free-to-use pipeline that can identify the number of kringle IV type 2 repeats and Lp(a)-associated variants even when inputting low-coverage libraries.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


