Jawad Sadek, Andreas Vlachidis, Victoria Pickering, Marco Humbel, Daniele Metilli, Mark Carine, Julianne Nyhan
{"title":"Leveraging OCR and HTR cloud services towards data mobilisation of historical plant names.","authors":"Jawad Sadek, Andreas Vlachidis, Victoria Pickering, Marco Humbel, Daniele Metilli, Mark Carine, Julianne Nyhan","doi":"10.1007/s42803-024-00091-4","DOIUrl":null,"url":null,"abstract":"<p><p>We present our solution to the problem of how to mobilise (that is, extract and enrich) digital data from the analogue, printed book version Sir Hans Sloane's copy of John Ray's Historia Plantarum, to create the first searchable facility of its kind to the plants contained in the Sloane Herbarium, housed in the National History Museum UK. The data mobilisation workflow presented here enables the automatic detection of printed and handwritten marginalia text and annotations in Sir Hans Sloane\" personal copy of John Ray's Historia Plantarum. The rationale of adopting AWS Amazon's Textract service and the development of a specialised information extraction workflow for mobilising printed text and handwritten annotations is discussed. Testing of our workflow demonstrates the need for human-checking of outputs to ensure the accuracy of a large set of structured data comprising 7600 plant names and 4540 handwritten marginalia annotation. The links we have created serve as the first digital index to Sloan's Herbarium, a unique development in the longer analogue and digital format-history of these resources.</p>","PeriodicalId":91018,"journal":{"name":"International journal of digital humanities","volume":"6 3","pages":"237-261"},"PeriodicalIF":0.0000,"publicationDate":"2024-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12106164/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International journal of digital humanities","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s42803-024-00091-4","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/28 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
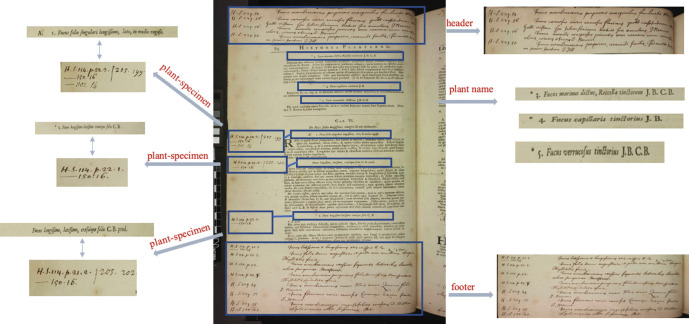
We present our solution to the problem of how to mobilise (that is, extract and enrich) digital data from the analogue, printed book version Sir Hans Sloane's copy of John Ray's Historia Plantarum, to create the first searchable facility of its kind to the plants contained in the Sloane Herbarium, housed in the National History Museum UK. The data mobilisation workflow presented here enables the automatic detection of printed and handwritten marginalia text and annotations in Sir Hans Sloane" personal copy of John Ray's Historia Plantarum. The rationale of adopting AWS Amazon's Textract service and the development of a specialised information extraction workflow for mobilising printed text and handwritten annotations is discussed. Testing of our workflow demonstrates the need for human-checking of outputs to ensure the accuracy of a large set of structured data comprising 7600 plant names and 4540 handwritten marginalia annotation. The links we have created serve as the first digital index to Sloan's Herbarium, a unique development in the longer analogue and digital format-history of these resources.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


