John D Milner, Matthew S Quinn, Phillip Schmitt, Ashley Knebel, Jeffrey Henstenburg, Adam Nasreddine, Alexandre R Boulos, Jonathan R Schiller, Craig P Eberson, Aristides I Cruz
{"title":"Performance of Artificial Intelligence in Addressing Questions Regarding the Management of Pediatric Supracondylar Humerus Fractures.","authors":"John D Milner, Matthew S Quinn, Phillip Schmitt, Ashley Knebel, Jeffrey Henstenburg, Adam Nasreddine, Alexandre R Boulos, Jonathan R Schiller, Craig P Eberson, Aristides I Cruz","doi":"10.1016/j.jposna.2025.100164","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The vast accessibility of artificial intelligence (AI) has enabled its utilization in medicine to improve patient education, augment patient-physician communications, support research efforts, and enhance medical student education. However, there is significant concern that these models may provide responses that are incorrect, biased, or lacking in the required nuance and complexity of best practice clinical decision-making. Currently, there is a paucity of literature comparing the quality and reliability of AI-generated responses. The purpose of this study was to assess the ability of ChatGPT and Gemini to generate reponses to the 2022 American Academy of Orthopaedic Surgeons' (AAOS) current practice guidlines on pediatric supracondylar humerus fractures. We hypothesized that both ChatGPT and Gemini would demonstrate high-quality, evidence-based responses with no significant difference between the models across evaluation criteria.</p><p><strong>Methods: </strong>The responses from ChatGPT and Gemini to responses based on the 14 AAOS guidelines were evaluated by seven fellowship-trained pediatric orthopaedic surgeons using a questionnaire to assess five key characteristics on a scale from 1 to 5. The prompts were categorized into nonoperative or preoperative management and diagnosis, surgical timing and technique, and rehabilitation and prevention. Statistical analysis included mean scoring, standard deviation, and two-sided t-tests to compare the performance between ChatGPT and Gemini. Scores were then evaluated for inter-rater reliability.</p><p><strong>Results: </strong>ChatGPT and Gemini demonstrated consistent performance across the criteria, with high mean scores across all criteria except for evidence-based responses. Mean scores were highest for clarity (ChatGPT: 3.745 ± 0.237, Gemini 4.388 ± 0.154) and lowest for evidence-based responses (ChatGPT: 1.816 ± 0.181, Gemini: 3.765 ± 0.229). There were notable statistically significant differences across all criteria, with Gemini having higher mean scores in each criterion (<i>P</i> < .001). Gemini achieved statistically higher ratings in the relevance (<i>P</i> = .03) and evidence-based (<i>P</i> < .001) criteria. Both large language models (LLMs) performed comparably in the accuracy, clarity, and completeness criteria (<i>P</i> > .05).</p><p><strong>Conclusions: </strong>ChatGPT and Gemini produced responses aligned with the 2022 AAOS current guideline practices for pediatric supracondylar humerus fractures. Gemini outperformed ChatGPT across all criteria, with the greatest difference in scores seen in the evidence-based category. This study emphasizes the potential for LLMs, particularly Gemini, to provide pertinent clinical information for managing pediatric supracondylar humerus fractures.</p><p><strong>Key concepts: </strong>(1)The accessibility of artificial intelligence has enabled its utilization in medicine to improve patient education, support research efforts, enhance medical student education, and augment patient-physician communications.(2)There is a significant concern that artificial intelligence may provide responses that are incorrect, biased, or lacking in the required nuance and complexity of best practice clinical decision-making.(3)There is a paucity of literature comparing the quality and reliability of AI-generated responses regarding management of pediatric supracondylar humerus fractures.(4)In our study, both ChatGPT and Gemini produced responses that were well aligned with the AAOS current guideline practices for pediatric supracondylar humerus fractures; however, Gemini outperformed ChatGPT across all criteria, with the greatest difference in scores seen in the evidence-based category.</p><p><strong>Level of evidence: </strong>Level II.</p>","PeriodicalId":520850,"journal":{"name":"Journal of the Pediatric Orthopaedic Society of North America","volume":"11 ","pages":"100164"},"PeriodicalIF":0.0000,"publicationDate":"2025-03-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12088213/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of the Pediatric Orthopaedic Society of North America","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1016/j.jposna.2025.100164","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/5/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The vast accessibility of artificial intelligence (AI) has enabled its utilization in medicine to improve patient education, augment patient-physician communications, support research efforts, and enhance medical student education. However, there is significant concern that these models may provide responses that are incorrect, biased, or lacking in the required nuance and complexity of best practice clinical decision-making. Currently, there is a paucity of literature comparing the quality and reliability of AI-generated responses. The purpose of this study was to assess the ability of ChatGPT and Gemini to generate reponses to the 2022 American Academy of Orthopaedic Surgeons' (AAOS) current practice guidlines on pediatric supracondylar humerus fractures. We hypothesized that both ChatGPT and Gemini would demonstrate high-quality, evidence-based responses with no significant difference between the models across evaluation criteria.
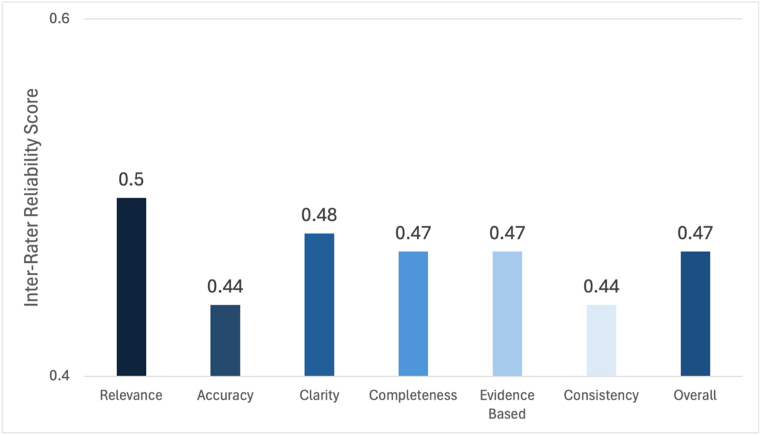
Methods: The responses from ChatGPT and Gemini to responses based on the 14 AAOS guidelines were evaluated by seven fellowship-trained pediatric orthopaedic surgeons using a questionnaire to assess five key characteristics on a scale from 1 to 5. The prompts were categorized into nonoperative or preoperative management and diagnosis, surgical timing and technique, and rehabilitation and prevention. Statistical analysis included mean scoring, standard deviation, and two-sided t-tests to compare the performance between ChatGPT and Gemini. Scores were then evaluated for inter-rater reliability.
Results: ChatGPT and Gemini demonstrated consistent performance across the criteria, with high mean scores across all criteria except for evidence-based responses. Mean scores were highest for clarity (ChatGPT: 3.745 ± 0.237, Gemini 4.388 ± 0.154) and lowest for evidence-based responses (ChatGPT: 1.816 ± 0.181, Gemini: 3.765 ± 0.229). There were notable statistically significant differences across all criteria, with Gemini having higher mean scores in each criterion (P < .001). Gemini achieved statistically higher ratings in the relevance (P = .03) and evidence-based (P < .001) criteria. Both large language models (LLMs) performed comparably in the accuracy, clarity, and completeness criteria (P > .05).
Conclusions: ChatGPT and Gemini produced responses aligned with the 2022 AAOS current guideline practices for pediatric supracondylar humerus fractures. Gemini outperformed ChatGPT across all criteria, with the greatest difference in scores seen in the evidence-based category. This study emphasizes the potential for LLMs, particularly Gemini, to provide pertinent clinical information for managing pediatric supracondylar humerus fractures.
Key concepts: (1)The accessibility of artificial intelligence has enabled its utilization in medicine to improve patient education, support research efforts, enhance medical student education, and augment patient-physician communications.(2)There is a significant concern that artificial intelligence may provide responses that are incorrect, biased, or lacking in the required nuance and complexity of best practice clinical decision-making.(3)There is a paucity of literature comparing the quality and reliability of AI-generated responses regarding management of pediatric supracondylar humerus fractures.(4)In our study, both ChatGPT and Gemini produced responses that were well aligned with the AAOS current guideline practices for pediatric supracondylar humerus fractures; however, Gemini outperformed ChatGPT across all criteria, with the greatest difference in scores seen in the evidence-based category.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


