Riste Stojanov, Milos Jovanovik, Sasho Gramatikov, Igor Mishkovski, Eftim Zdravevski, Darko Sasanski, Zorica Karapancheva, Goce Spasovski, Ivona Vasileska, Tome Eftimov, Wu Zhuojun, Joachim Jankowski, Dimitar Trajanov
{"title":"Applicability Assessment of Technologies for Predictive and Prescriptive Analytics of Nephrology Big Data","authors":"Riste Stojanov, Milos Jovanovik, Sasho Gramatikov, Igor Mishkovski, Eftim Zdravevski, Darko Sasanski, Zorica Karapancheva, Goce Spasovski, Ivona Vasileska, Tome Eftimov, Wu Zhuojun, Joachim Jankowski, Dimitar Trajanov","doi":"10.1002/pmic.202400135","DOIUrl":null,"url":null,"abstract":"<p>The integration of big data into nephrology research will open new avenues for analyzing and understanding complex biological datasets, driving advances in personalized management of kidney diseases. This paper describes the multifaceted challenges and opportunities by incorporating big data in nephrology, emphasizing the importance of data standardization, advanced storage solutions, and advanced analytical methods. We discuss the role of data science workflows, including data collection, preprocessing, integration, and analysis, in facilitating comprehensive insights into disease mechanisms and patient outcomes. Furthermore, we highlight predictive and prescriptive analytics, as well as the application of large language models (LLMs) in improving clinical decision-making and enhancing the accuracy of disease predictions. The use of high-performance computing (HPC) is also examined, showcasing its role in processing large-scale datasets and accelerating machine learning algorithms. Through this exploration, we aim to provide a comprehensive overview of the current state and future directions of big data analytics in nephrology, with a focus on enhancing patient care and advancing medical research.</p>","PeriodicalId":224,"journal":{"name":"Proteomics","volume":"25 11-12","pages":""},"PeriodicalIF":3.9000,"publicationDate":"2025-05-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/pmic.202400135","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Proteomics","FirstCategoryId":"99","ListUrlMain":"https://analyticalsciencejournals.onlinelibrary.wiley.com/doi/10.1002/pmic.202400135","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
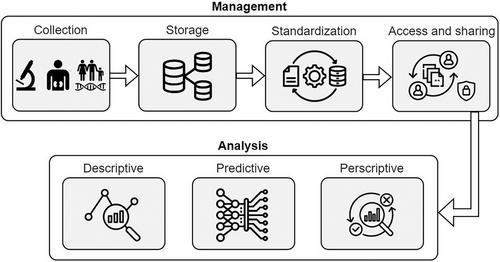
The integration of big data into nephrology research will open new avenues for analyzing and understanding complex biological datasets, driving advances in personalized management of kidney diseases. This paper describes the multifaceted challenges and opportunities by incorporating big data in nephrology, emphasizing the importance of data standardization, advanced storage solutions, and advanced analytical methods. We discuss the role of data science workflows, including data collection, preprocessing, integration, and analysis, in facilitating comprehensive insights into disease mechanisms and patient outcomes. Furthermore, we highlight predictive and prescriptive analytics, as well as the application of large language models (LLMs) in improving clinical decision-making and enhancing the accuracy of disease predictions. The use of high-performance computing (HPC) is also examined, showcasing its role in processing large-scale datasets and accelerating machine learning algorithms. Through this exploration, we aim to provide a comprehensive overview of the current state and future directions of big data analytics in nephrology, with a focus on enhancing patient care and advancing medical research.
期刊介绍:
PROTEOMICS is the premier international source for information on all aspects of applications and technologies, including software, in proteomics and other "omics". The journal includes but is not limited to proteomics, genomics, transcriptomics, metabolomics and lipidomics, and systems biology approaches. Papers describing novel applications of proteomics and integration of multi-omics data and approaches are especially welcome.





 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


