Jiajie Wu, Frederick W. B. Li, Gary K. L. Tam, Bailin Yang, Fangzhe Nan, Jiahao Pan
{"title":"Talking Face Generation With Lip and Identity Priors","authors":"Jiajie Wu, Frederick W. B. Li, Gary K. L. Tam, Bailin Yang, Fangzhe Nan, Jiahao Pan","doi":"10.1002/cav.70026","DOIUrl":null,"url":null,"abstract":"<div>\n \n <p>Speech-driven talking face video generation has attracted growing interest in recent research. While person-specific approaches yield high-fidelity results, they require extensive training data from each individual speaker. In contrast, general-purpose methods often struggle with accurate lip synchronization, identity preservation, and natural facial movements. To address these limitations, we propose a novel architecture that combines an alignment model with a rendering model. The rendering model synthesizes identity-consistent lip movements by leveraging facial landmarks derived from speech, a partially occluded target face, multi-reference lip features, and the input audio. Concurrently, the alignment model estimates optical flow using the occluded face and a static reference image, enabling precise alignment of facial poses and lip shapes. This collaborative design enhances the rendering process, resulting in more realistic and identity-preserving outputs. Extensive experiments demonstrate that our method significantly improves lip synchronization and identity retention, establishing a new benchmark in talking face video generation.</p>\n </div>","PeriodicalId":50645,"journal":{"name":"Computer Animation and Virtual Worlds","volume":"36 3","pages":""},"PeriodicalIF":1.7000,"publicationDate":"2025-05-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer Animation and Virtual Worlds","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/cav.70026","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
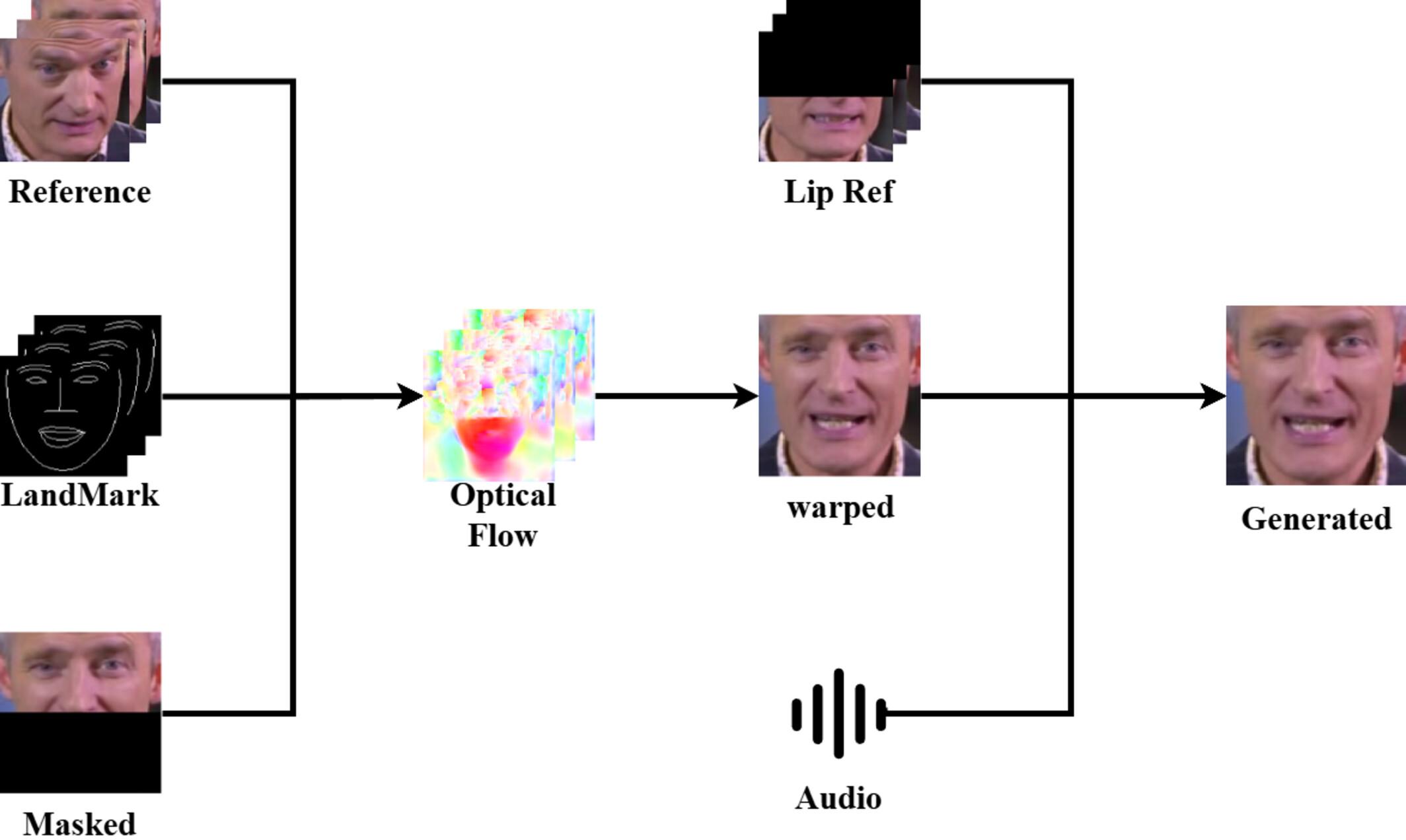
Speech-driven talking face video generation has attracted growing interest in recent research. While person-specific approaches yield high-fidelity results, they require extensive training data from each individual speaker. In contrast, general-purpose methods often struggle with accurate lip synchronization, identity preservation, and natural facial movements. To address these limitations, we propose a novel architecture that combines an alignment model with a rendering model. The rendering model synthesizes identity-consistent lip movements by leveraging facial landmarks derived from speech, a partially occluded target face, multi-reference lip features, and the input audio. Concurrently, the alignment model estimates optical flow using the occluded face and a static reference image, enabling precise alignment of facial poses and lip shapes. This collaborative design enhances the rendering process, resulting in more realistic and identity-preserving outputs. Extensive experiments demonstrate that our method significantly improves lip synchronization and identity retention, establishing a new benchmark in talking face video generation.
期刊介绍:
With the advent of very powerful PCs and high-end graphics cards, there has been an incredible development in Virtual Worlds, real-time computer animation and simulation, games. But at the same time, new and cheaper Virtual Reality devices have appeared allowing an interaction with these real-time Virtual Worlds and even with real worlds through Augmented Reality. Three-dimensional characters, especially Virtual Humans are now of an exceptional quality, which allows to use them in the movie industry. But this is only a beginning, as with the development of Artificial Intelligence and Agent technology, these characters will become more and more autonomous and even intelligent. They will inhabit the Virtual Worlds in a Virtual Life together with animals and plants.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


