{"title":"Large Language Models for Pre-mediation Counseling in Medical Disputes: A Comparative Evaluation against Human Experts.","authors":"Min Seo Kim, Jung Su Lee, Hyuna Bae","doi":"10.4258/hir.2025.31.2.200","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>Assessing medical disputes requires both medical and legal expertise, presenting challenges for patients seeking clarity regarding potential malpractice claims. This study aimed to develop and evaluate a chatbot based on a chain-of-thought pipeline using a large language model (LLM) for providing medical dispute counseling and compare its performance with responses from human experts.</p><p><strong>Methods: </strong>Retrospective counseling cases (n = 279) were collected from the Korea Medical Dispute Mediation and Arbitration Agency's website, from which 50 cases were randomly selected as a validation dataset. The Claude 3.5 Sonnet model processed each counseling request through a five-step chain-of-thought pipeline. Thirty-eight experts evaluated the chatbot's responses against the original human expert responses, rating them across four dimensions on a 5-point Likert scale. Statistical analyses were conducted using Wilcoxon signed-rank tests.</p><p><strong>Results: </strong>The chatbot significantly outperformed human experts in quality of information (p < 0.001), understanding and reasoning (p < 0.001), and overall satisfaction (p < 0.001). It also demonstrated a stronger tendency to produce opinion-driven content (p < 0.001). Despite generally high scores, evaluators noted specific instances where the chatbot encountered difficulties.</p><p><strong>Conclusions: </strong>A chain-of-thought-based LLM chatbot shows promise for enhancing the quality of medical dispute counseling, outperforming human experts across key evaluation metrics. Future research should address inaccuracies resulting from legal and contextual variability, investigate patient acceptance, and further refine the chatbot's performance in domain-specific applications.</p>","PeriodicalId":12947,"journal":{"name":"Healthcare Informatics Research","volume":"31 2","pages":"200-208"},"PeriodicalIF":2.1000,"publicationDate":"2025-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12086436/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Healthcare Informatics Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4258/hir.2025.31.2.200","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/4/30 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: Assessing medical disputes requires both medical and legal expertise, presenting challenges for patients seeking clarity regarding potential malpractice claims. This study aimed to develop and evaluate a chatbot based on a chain-of-thought pipeline using a large language model (LLM) for providing medical dispute counseling and compare its performance with responses from human experts.
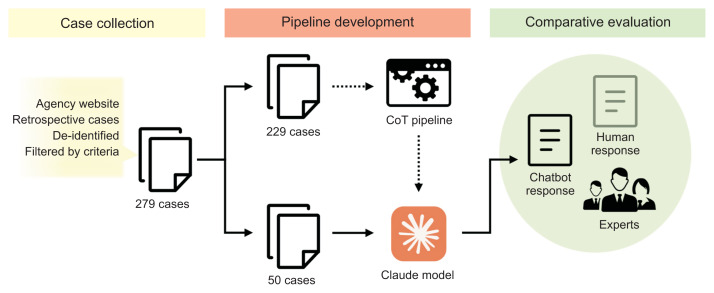
Methods: Retrospective counseling cases (n = 279) were collected from the Korea Medical Dispute Mediation and Arbitration Agency's website, from which 50 cases were randomly selected as a validation dataset. The Claude 3.5 Sonnet model processed each counseling request through a five-step chain-of-thought pipeline. Thirty-eight experts evaluated the chatbot's responses against the original human expert responses, rating them across four dimensions on a 5-point Likert scale. Statistical analyses were conducted using Wilcoxon signed-rank tests.
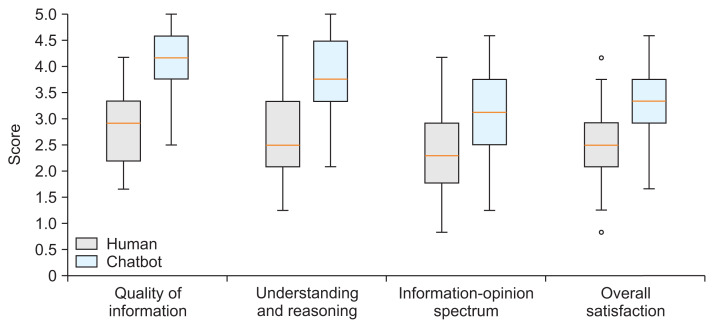
Results: The chatbot significantly outperformed human experts in quality of information (p < 0.001), understanding and reasoning (p < 0.001), and overall satisfaction (p < 0.001). It also demonstrated a stronger tendency to produce opinion-driven content (p < 0.001). Despite generally high scores, evaluators noted specific instances where the chatbot encountered difficulties.
Conclusions: A chain-of-thought-based LLM chatbot shows promise for enhancing the quality of medical dispute counseling, outperforming human experts across key evaluation metrics. Future research should address inaccuracies resulting from legal and contextual variability, investigate patient acceptance, and further refine the chatbot's performance in domain-specific applications.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


