Wenjing Guo, Fan Dong, Jie Liu, Aasma Aslam, Tucker A Patterson, Huixiao Hong
{"title":"A refined set of RxNorm drug names for enhancing unstructured data analysis in drug safety surveillance.","authors":"Wenjing Guo, Fan Dong, Jie Liu, Aasma Aslam, Tucker A Patterson, Huixiao Hong","doi":"10.3389/ebm.2025.10374","DOIUrl":null,"url":null,"abstract":"<p><p>Adverse drug events are harms associated with drug use, whether the drug is used correctly or incorrectly. Identifying adverse drug events is vital in pharmacovigilance to safeguard public health. Drug safety surveillance can be performed using unstructured data. A comprehensive and accurate list of drug names is essential for effective identification of adverse drug events. While there are numerous sources for drug names, RxNorm is widely recognized as a leading resource. However, its effectiveness for unstructured data analysis in drug safety surveillance has not been thoroughly assessed. To address this, we evaluated the drug names in RxNorm for their suitability in unstructured data analysis and developed a refined set of drug names. Initially, we removed duplicates, the names exceeding 199 characters, and those that only describe administrative details. Drug names with four or fewer characters were analyzed using 18,000 drug-related PubMed abstracts to remove names which rarely appear in unstructured data. The remaining names, which ranged from five to 199 characters, were further refined to exclude those that could lead to inaccurate drug counts in unstructured data analysis. We compared the efficiency and accuracy of the refined set with the original RxNorm set by testing both on the 18,000 drug-related PubMed abstracts. The results showed a decrease in both computational cost and the number of false drug names identified. Further analysis of the removed names revealed that most originated from only one of the 14 sources. Our findings suggest that the refined set can enhance drug identification in unstructured data analysis, thereby improving pharmacovigilance.</p>","PeriodicalId":12163,"journal":{"name":"Experimental Biology and Medicine","volume":"250 ","pages":"10374"},"PeriodicalIF":2.7000,"publicationDate":"2025-05-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12083459/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Experimental Biology and Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.3389/ebm.2025.10374","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MEDICINE, RESEARCH & EXPERIMENTAL","Score":null,"Total":0}
引用次数: 0
Abstract
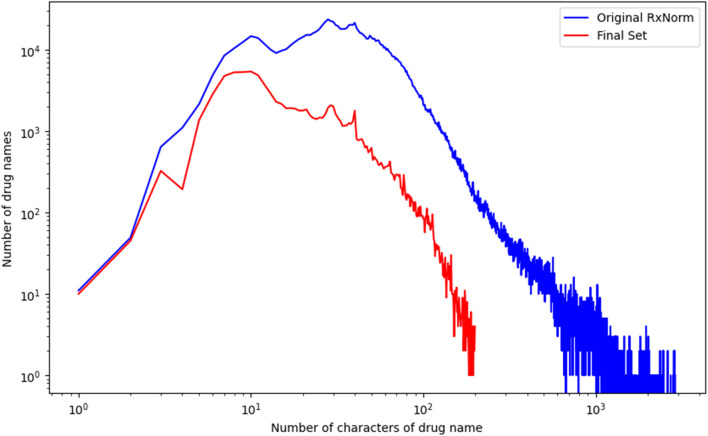
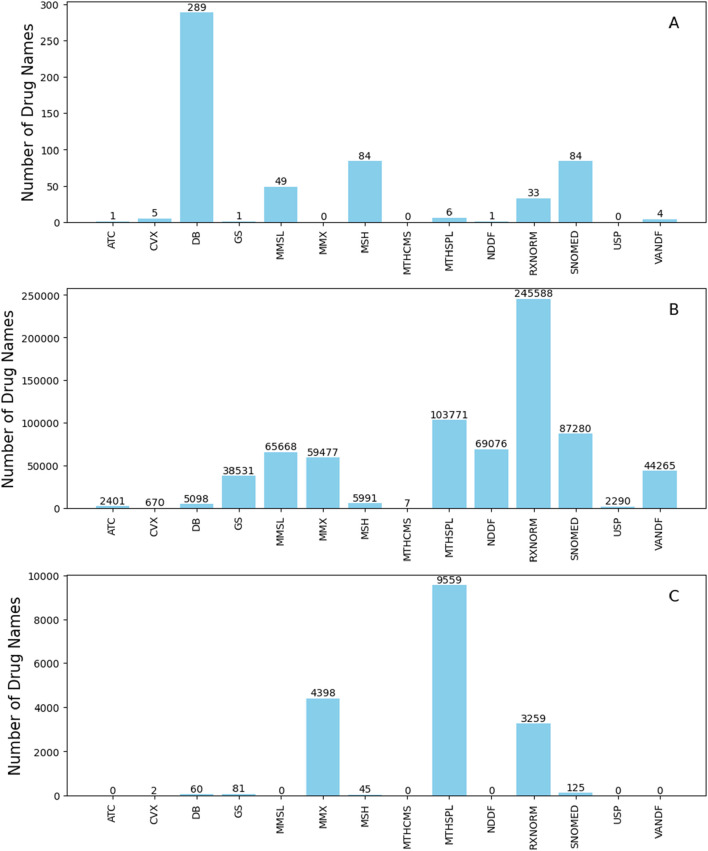
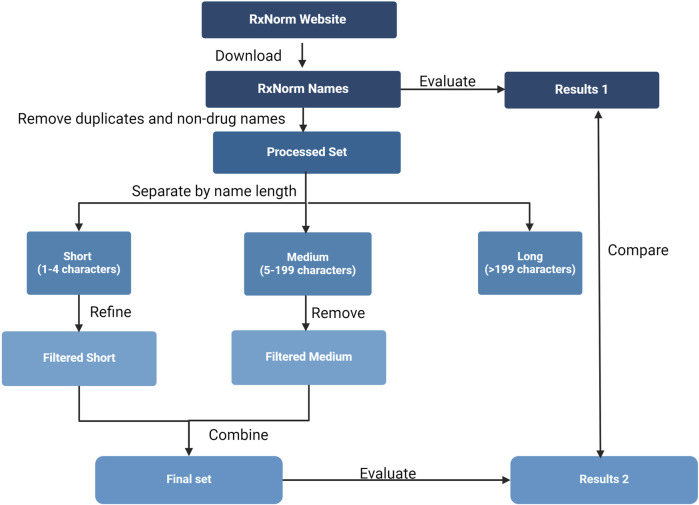
Adverse drug events are harms associated with drug use, whether the drug is used correctly or incorrectly. Identifying adverse drug events is vital in pharmacovigilance to safeguard public health. Drug safety surveillance can be performed using unstructured data. A comprehensive and accurate list of drug names is essential for effective identification of adverse drug events. While there are numerous sources for drug names, RxNorm is widely recognized as a leading resource. However, its effectiveness for unstructured data analysis in drug safety surveillance has not been thoroughly assessed. To address this, we evaluated the drug names in RxNorm for their suitability in unstructured data analysis and developed a refined set of drug names. Initially, we removed duplicates, the names exceeding 199 characters, and those that only describe administrative details. Drug names with four or fewer characters were analyzed using 18,000 drug-related PubMed abstracts to remove names which rarely appear in unstructured data. The remaining names, which ranged from five to 199 characters, were further refined to exclude those that could lead to inaccurate drug counts in unstructured data analysis. We compared the efficiency and accuracy of the refined set with the original RxNorm set by testing both on the 18,000 drug-related PubMed abstracts. The results showed a decrease in both computational cost and the number of false drug names identified. Further analysis of the removed names revealed that most originated from only one of the 14 sources. Our findings suggest that the refined set can enhance drug identification in unstructured data analysis, thereby improving pharmacovigilance.
期刊介绍:
Experimental Biology and Medicine (EBM) is a global, peer-reviewed journal dedicated to the publication of multidisciplinary and interdisciplinary research in the biomedical sciences. EBM provides both research and review articles as well as meeting symposia and brief communications. Articles in EBM represent cutting edge research at the overlapping junctions of the biological, physical and engineering sciences that impact upon the health and welfare of the world''s population.
Topics covered in EBM include: Anatomy/Pathology; Biochemistry and Molecular Biology; Bioimaging; Biomedical Engineering; Bionanoscience; Cell and Developmental Biology; Endocrinology and Nutrition; Environmental Health/Biomarkers/Precision Medicine; Genomics, Proteomics, and Bioinformatics; Immunology/Microbiology/Virology; Mechanisms of Aging; Neuroscience; Pharmacology and Toxicology; Physiology; Stem Cell Biology; Structural Biology; Systems Biology and Microphysiological Systems; and Translational Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


