{"title":"Temporal coherence effects on voice attribution in multi-speaker stream segregation.","authors":"Jaeeun Lee, Andrew J Oxenham","doi":"10.1121/10.0036672","DOIUrl":null,"url":null,"abstract":"<p><p>The principle of temporal coherence predicts that two temporally coherent voices should form a unified auditory stream, whereas incoherent voices should form separate streams. This prediction was tested by asking 20 normal-hearing listeners to identify the last word spoken by the higher or lower of two talkers, preceded by temporally coherent or incoherent phrases spoken by the same two talkers, or by silence. In contrast to results from stream-segregation studies using simple repeating stimuli that manipulated temporal coherence, no significant differences in performance were observed between the conditions, raising questions regarding the generalization of temporal-coherence principles to complex speech.</p>","PeriodicalId":73538,"journal":{"name":"JASA express letters","volume":"5 5","pages":""},"PeriodicalIF":1.4000,"publicationDate":"2025-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12077373/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JASA express letters","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1121/10.0036672","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"ACOUSTICS","Score":null,"Total":0}
引用次数: 0
Abstract
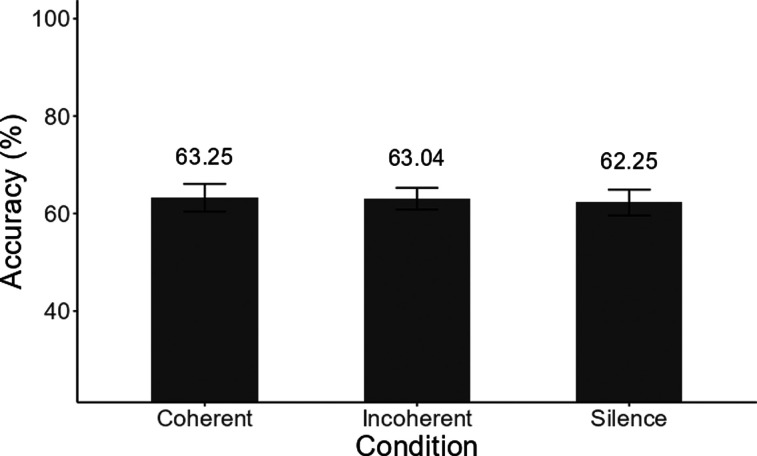
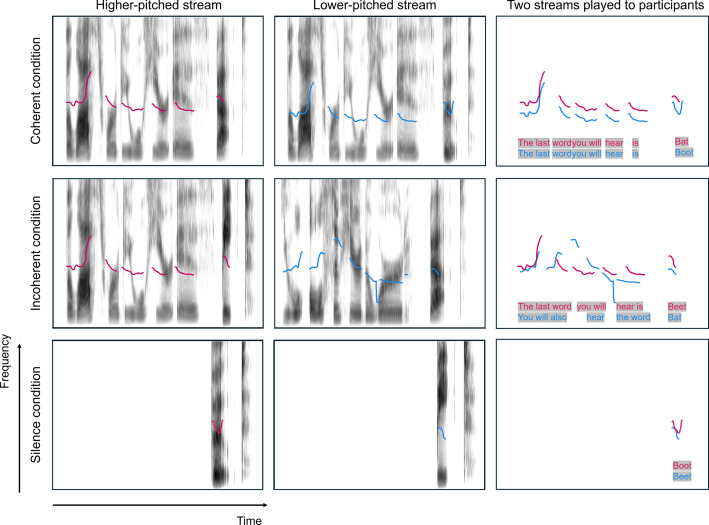
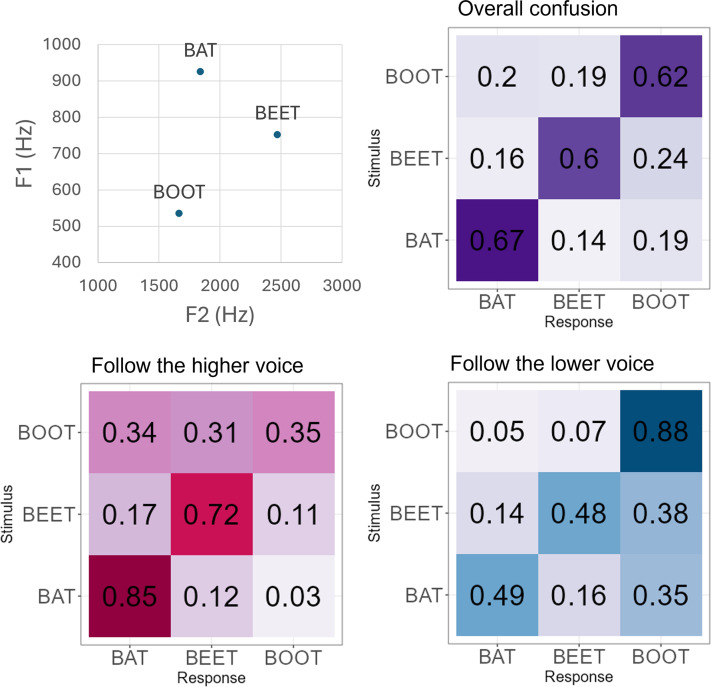
The principle of temporal coherence predicts that two temporally coherent voices should form a unified auditory stream, whereas incoherent voices should form separate streams. This prediction was tested by asking 20 normal-hearing listeners to identify the last word spoken by the higher or lower of two talkers, preceded by temporally coherent or incoherent phrases spoken by the same two talkers, or by silence. In contrast to results from stream-segregation studies using simple repeating stimuli that manipulated temporal coherence, no significant differences in performance were observed between the conditions, raising questions regarding the generalization of temporal-coherence principles to complex speech.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


