An oversampling-undersampling strategy for large-scale data linkage.
IF 2.4
Q3 COMPUTER SCIENCE, INFORMATION SYSTEMS
Frontiers in Big Data
Pub Date : 2025-04-23
eCollection Date: 2025-01-01
DOI:10.3389/fdata.2025.1542483
引用次数: 0
Abstract
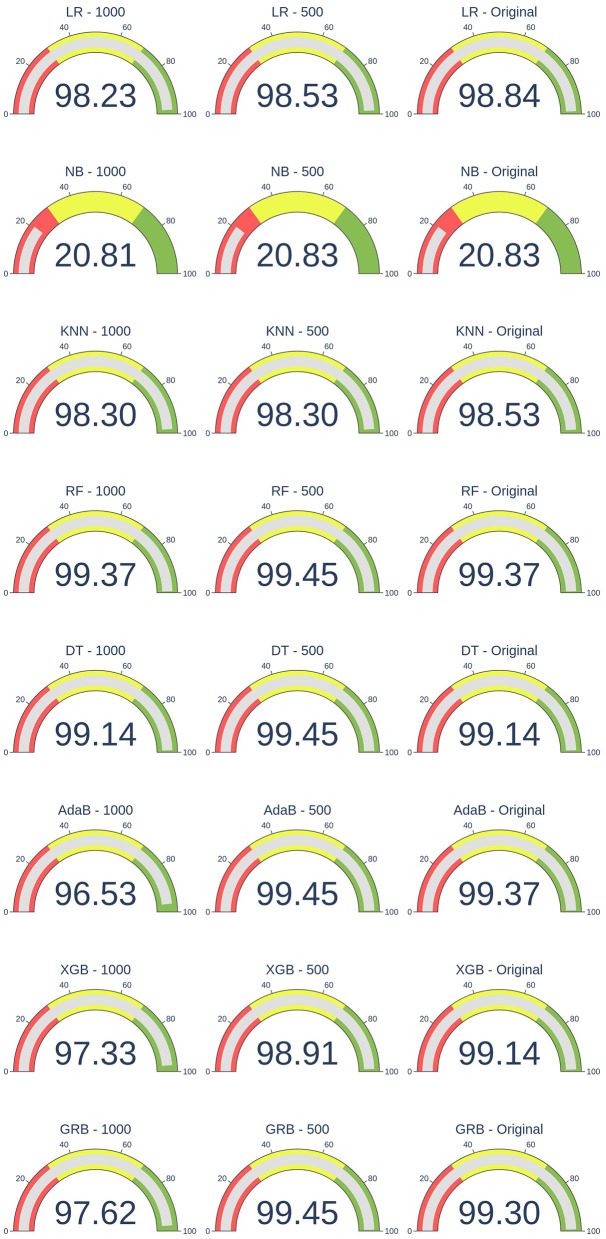
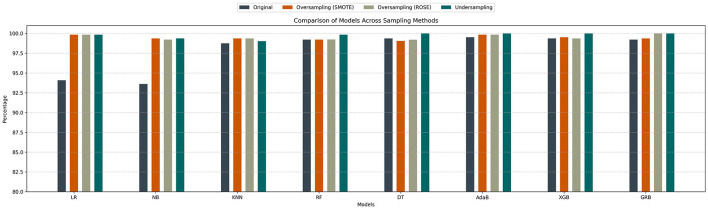
Effective record linkage in big data, particularly in imbalanced datasets, is a critical yet highly challenging task due to the inherent complexity involved. This article utilizes an oversampling-undersampling strategy to address linkage imbalances, enabling more accurate and efficient record linkage within large-scale datasets. It tries to increase the instances of the minority class and decrease the dominance of the majority classes to try to reach a more balanced dataset that can be used for training and testing. Sensitivity testing was carried out by varying the training-test ratio and degree of imbalance.
大规模数据链接的过采样-欠采样策略。
由于其固有的复杂性,在大数据中,特别是在不平衡的数据集中,有效的记录链接是一项至关重要但极具挑战性的任务。本文利用过采样-欠采样策略来解决链接不平衡问题,从而在大规模数据集中实现更准确和有效的记录链接。它试图增加少数类的实例,减少多数类的主导地位,以试图达到一个更平衡的数据集,可用于训练和测试。通过改变训练-测试比例和不平衡程度进行敏感性测试。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


