Can we develop real-world prognostic models using observational healthcare data? Large-scale experiment to investigate model sensitivity to database and phenotypes.
{"title":"Can we develop real-world prognostic models using observational healthcare data? Large-scale experiment to investigate model sensitivity to database and phenotypes.","authors":"Jenna M Reps, Peter R Rijnbeek, Patrick B Ryan","doi":"10.1186/s41512-025-00191-x","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Large observational healthcare databases are frequently used to develop models to be implemented in real-world clinical practice populations. For example, these databases were used to develop COVID severity models that guided interventions such as who to prioritize vaccinating during the pandemic. However, the clinical setting and observational databases often differ in the types of patients (case mix), and it is a nontrivial process to identify patients with medical conditions (phenotyping) in these databases. In this study, we investigate how sensitive a model's performance is to the choice of development database, population, and outcome phenotype.</p><p><strong>Methods: </strong>We developed > 450 different logistic regression models for nine prediction tasks across seven databases with a range of suitable population and outcome phenotypes. Performance stability within tasks was calculated by applying each model to data created by permuting the database, population, or outcome phenotype. We investigate performance (AUROC, scaled Brier, and calibration-in-the-large) stability and individual risk estimate stability.</p><p><strong>Results: </strong>In general, changing the outcome definitions or population phenotype made little impact on the model validation discrimination. However, validation discrimination was unstable when the database changed. Calibration and Brier performance were unstable when the population, outcome definition, or database changed. This may be problematic if a model developed using observational data is implemented in a real-world setting.</p><p><strong>Conclusions: </strong>These results highlight the importance of validating a model developed using observational data in the clinical setting prior to using it for decision-making. Calibration and Brier score should be evaluated to prevent miscalibrated risk estimates being used to aid clinical decisions.</p>","PeriodicalId":72800,"journal":{"name":"Diagnostic and prognostic research","volume":"9 1","pages":"10"},"PeriodicalIF":2.6000,"publicationDate":"2025-04-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12004590/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Diagnostic and prognostic research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s41512-025-00191-x","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Large observational healthcare databases are frequently used to develop models to be implemented in real-world clinical practice populations. For example, these databases were used to develop COVID severity models that guided interventions such as who to prioritize vaccinating during the pandemic. However, the clinical setting and observational databases often differ in the types of patients (case mix), and it is a nontrivial process to identify patients with medical conditions (phenotyping) in these databases. In this study, we investigate how sensitive a model's performance is to the choice of development database, population, and outcome phenotype.
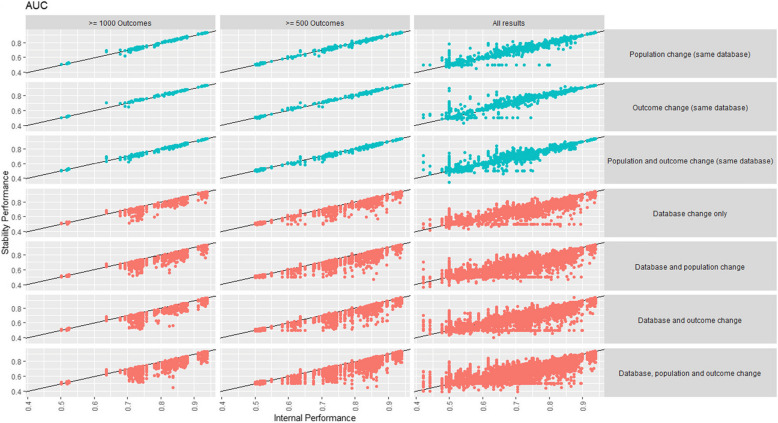
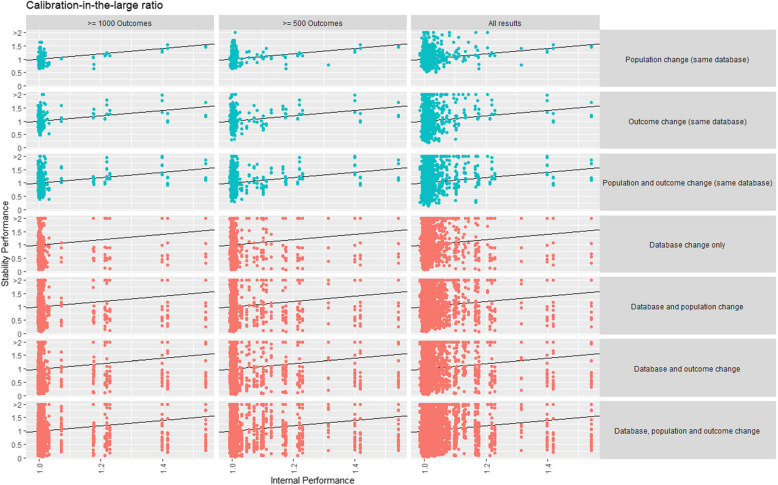
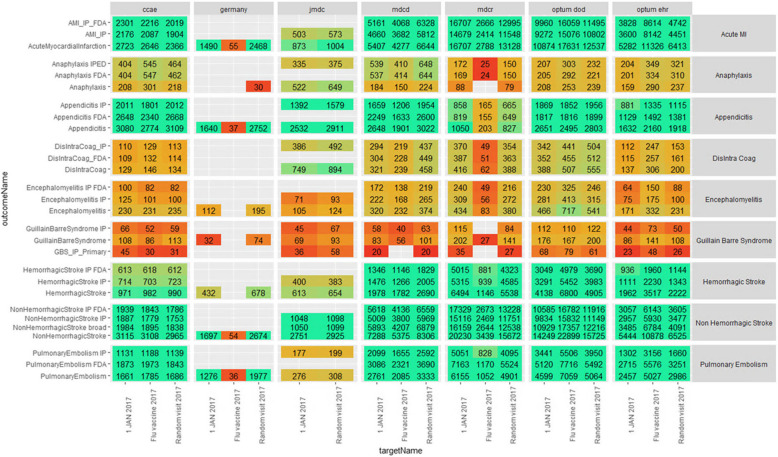
Methods: We developed > 450 different logistic regression models for nine prediction tasks across seven databases with a range of suitable population and outcome phenotypes. Performance stability within tasks was calculated by applying each model to data created by permuting the database, population, or outcome phenotype. We investigate performance (AUROC, scaled Brier, and calibration-in-the-large) stability and individual risk estimate stability.
Results: In general, changing the outcome definitions or population phenotype made little impact on the model validation discrimination. However, validation discrimination was unstable when the database changed. Calibration and Brier performance were unstable when the population, outcome definition, or database changed. This may be problematic if a model developed using observational data is implemented in a real-world setting.
Conclusions: These results highlight the importance of validating a model developed using observational data in the clinical setting prior to using it for decision-making. Calibration and Brier score should be evaluated to prevent miscalibrated risk estimates being used to aid clinical decisions.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


