{"title":"Descriptor: <i>Synthetic Genomic Dataset With Diverse Ancestry (SynGen6)</i>.","authors":"Xinyue Wang, Sitao Min, Jaideep Vaidya","doi":"10.1109/ieeedata.2024.3505852","DOIUrl":null,"url":null,"abstract":"<p><p>Advancements in genomic analysis techniques and data-driven research are driving precision medicine. However, in many cases, these advances are not equitable and do not help all subpopulations, since many existing genomic datasets lack diversity, limiting their applicability for studying populations beyond those of European ancestry. Thus, to advance genomic analysis and to allow for a fair benchmarking of novel proposed approaches, there is a significant demand for balanced and representative datasets. To address this issue, we developed, <i>SynGen6</i>, a synthetic dataset that encompasses six distinct populations, providing balanced representation across various ancestry groups. Using the <i>All of Us</i> dataset as a foundation, we utilized principal component analysis (PCA) and <i>ϵ</i>-local differential privacy (LDP) to generate synthetic samples while preserving genetic diversity and the privacy of individuals. To further enhance the dataset, we simulated phenotype vectors associated with significant single nucleotide polymorphisms (SNPs), mirroring real-world gene-disease associations. We also generated synthetic SNPs to watermark the dataset, enabling verification of cloud-based genomic computations for accuracy. Last, synthetic relatives were created to support research on kinship inference and family-based genomic analyses, resulting in a comprehensive dataset of 34 200 samples and 7120 SNPs across six populations. In this article, we describe the dataset and provide the Python scripts used to generate the dataset, which can be extended to create additional synthetic datasets, aiming to fuel advancements in genomic data analysis.</p>","PeriodicalId":520344,"journal":{"name":"IEEE data descriptions","volume":"2 ","pages":"1-7"},"PeriodicalIF":0.0000,"publicationDate":"2024-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12007885/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"IEEE data descriptions","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1109/ieeedata.2024.3505852","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/26 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
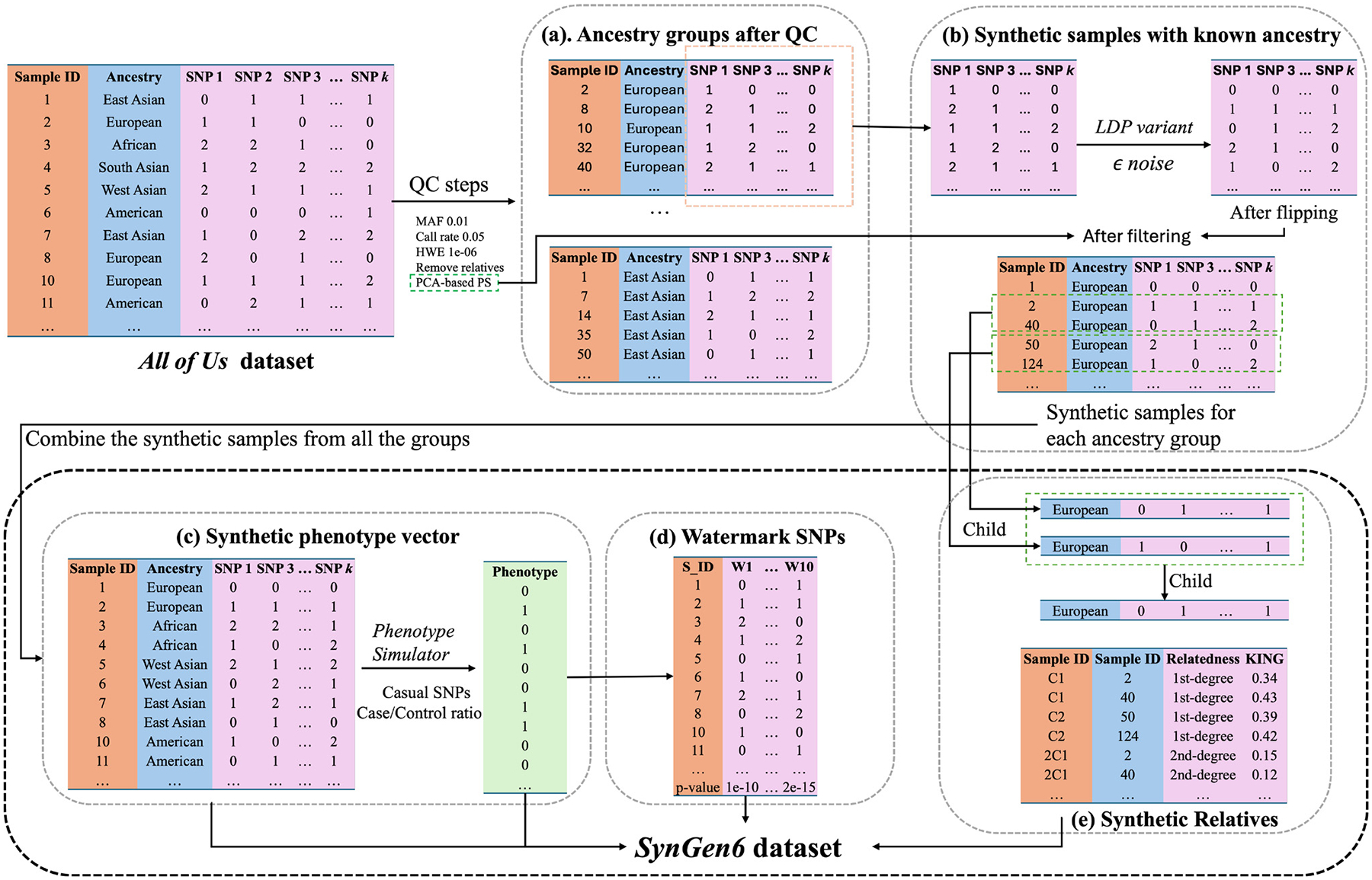
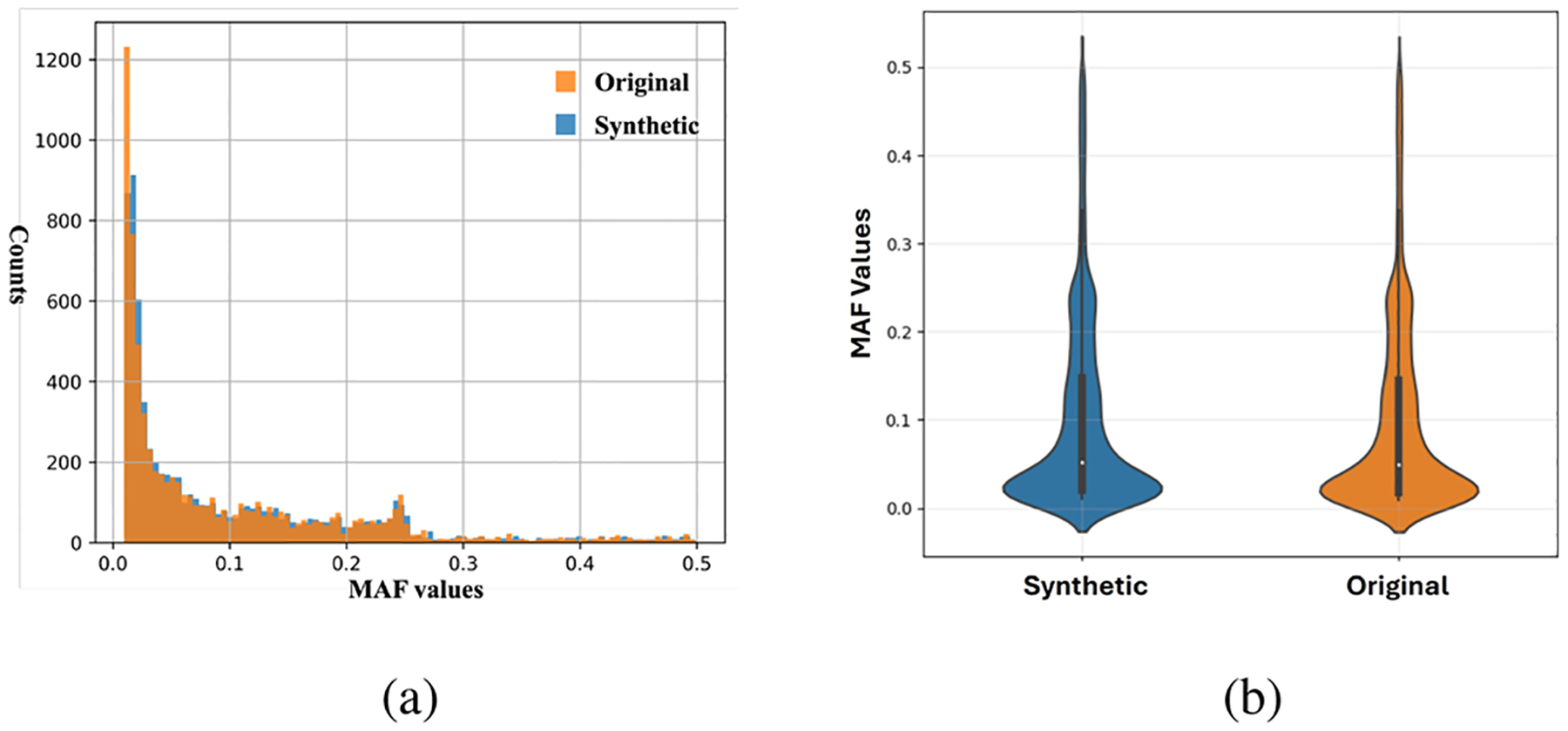
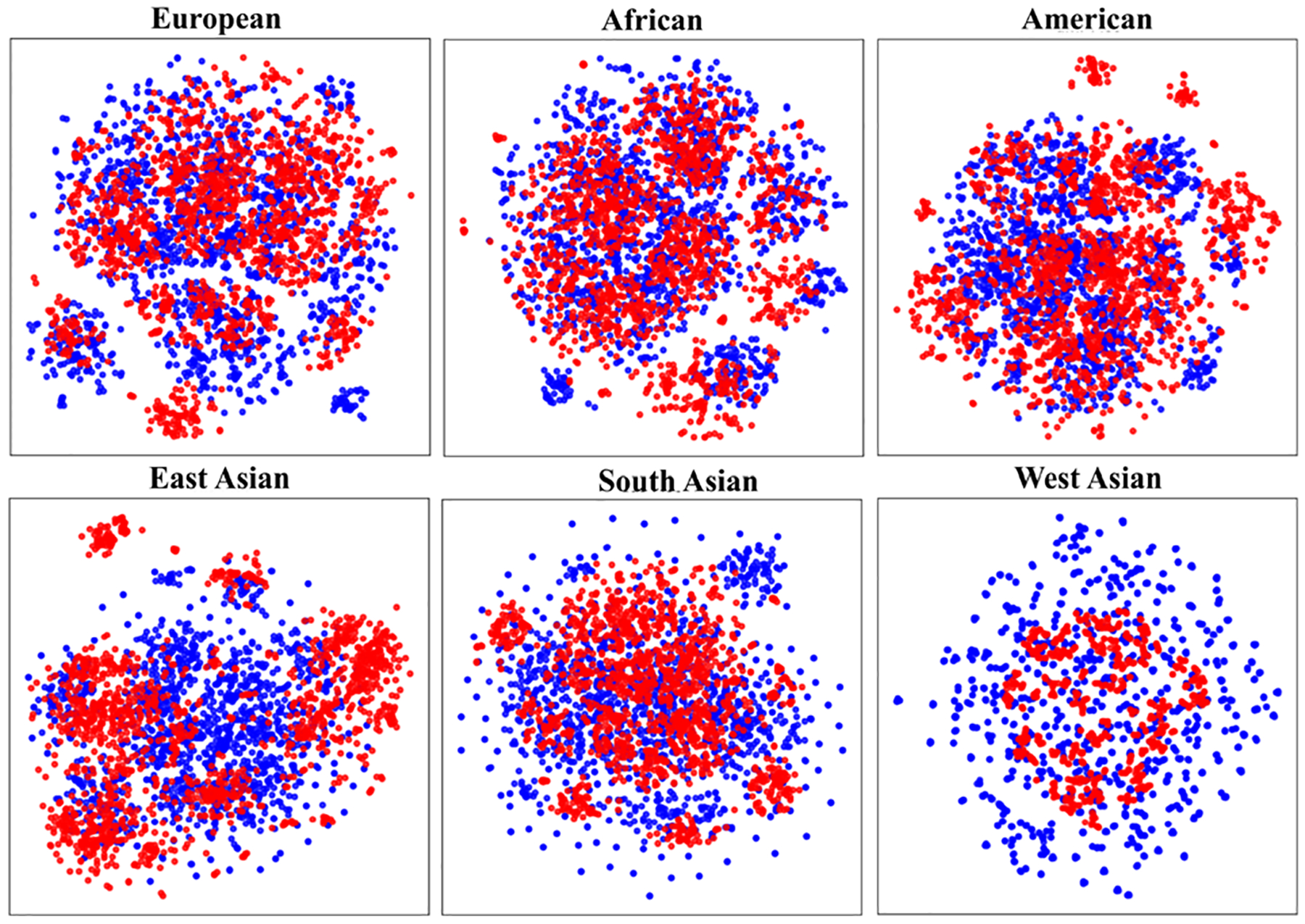
Advancements in genomic analysis techniques and data-driven research are driving precision medicine. However, in many cases, these advances are not equitable and do not help all subpopulations, since many existing genomic datasets lack diversity, limiting their applicability for studying populations beyond those of European ancestry. Thus, to advance genomic analysis and to allow for a fair benchmarking of novel proposed approaches, there is a significant demand for balanced and representative datasets. To address this issue, we developed, SynGen6, a synthetic dataset that encompasses six distinct populations, providing balanced representation across various ancestry groups. Using the All of Us dataset as a foundation, we utilized principal component analysis (PCA) and ϵ-local differential privacy (LDP) to generate synthetic samples while preserving genetic diversity and the privacy of individuals. To further enhance the dataset, we simulated phenotype vectors associated with significant single nucleotide polymorphisms (SNPs), mirroring real-world gene-disease associations. We also generated synthetic SNPs to watermark the dataset, enabling verification of cloud-based genomic computations for accuracy. Last, synthetic relatives were created to support research on kinship inference and family-based genomic analyses, resulting in a comprehensive dataset of 34 200 samples and 7120 SNPs across six populations. In this article, we describe the dataset and provide the Python scripts used to generate the dataset, which can be extended to create additional synthetic datasets, aiming to fuel advancements in genomic data analysis.
基因组分析技术和数据驱动研究的进步正在推动精准医疗。然而,在许多情况下,这些进步是不公平的,并不能帮助所有的亚种群,因为许多现有的基因组数据集缺乏多样性,限制了它们在研究欧洲血统以外的种群时的适用性。因此,为了推进基因组分析并允许对新提出的方法进行公平的基准测试,对平衡和具有代表性的数据集有很大的需求。为了解决这个问题,我们开发了SynGen6,这是一个包含六个不同种群的合成数据集,在不同的祖先群体中提供平衡的表示。以All of Us数据集为基础,利用主成分分析(PCA)和ϵ-local差分隐私(LDP)生成合成样本,同时保留遗传多样性和个体隐私。为了进一步增强数据集,我们模拟了与显著单核苷酸多态性(snp)相关的表型载体,反映了现实世界的基因-疾病关联。我们还生成了合成snp来标记数据集,从而验证基于云的基因组计算的准确性。最后,为支持亲属关系推断和基于家庭的基因组分析研究,构建了包含6个种群的34 200个样本和7120个snp的综合数据集。在本文中,我们描述了数据集并提供了用于生成数据集的Python脚本,这些脚本可以扩展以创建额外的合成数据集,旨在推动基因组数据分析的进步。

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


