Vimig Socrates, Donald S Wright, Thomas Huang, Soraya Fereydooni, Christine Dien, Ling Chi, Jesse Albano, Brian Patterson, Naga Sasidhar Kanaparthy, Catherine X Wright, Andrew Loza, David Chartash, Mark Iscoe, Richard Andrew Taylor
{"title":"Identifying Deprescribing Opportunities With Large Language Models in Older Adults: Retrospective Cohort Study.","authors":"Vimig Socrates, Donald S Wright, Thomas Huang, Soraya Fereydooni, Christine Dien, Ling Chi, Jesse Albano, Brian Patterson, Naga Sasidhar Kanaparthy, Catherine X Wright, Andrew Loza, David Chartash, Mark Iscoe, Richard Andrew Taylor","doi":"10.2196/69504","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Polypharmacy, the concurrent use of multiple medications, is prevalent among older adults and associated with increased risks for adverse drug events including falls. Deprescribing, the systematic process of discontinuing potentially inappropriate medications, aims to mitigate these risks. However, the practical application of deprescribing criteria in emergency settings remains limited due to time constraints and criteria complexity.</p><p><strong>Objective: </strong>This study aims to evaluate the performance of a large language model (LLM)-based pipeline in identifying deprescribing opportunities for older emergency department (ED) patients with polypharmacy, using 3 different sets of criteria: Beers, Screening Tool of Older People's Prescriptions, and Geriatric Emergency Medication Safety Recommendations. The study further evaluates LLM confidence calibration and its ability to improve recommendation performance.</p><p><strong>Methods: </strong>We conducted a retrospective cohort study of older adults presenting to an ED in a large academic medical center in the Northeast United States from January 2022 to March 2022. A random sample of 100 patients (712 total oral medications) was selected for detailed analysis. The LLM pipeline consisted of two steps: (1) filtering high-yield deprescribing criteria based on patients' medication lists, and (2) applying these criteria using both structured and unstructured patient data to recommend deprescribing. Model performance was assessed by comparing model recommendations to those of trained medical students, with discrepancies adjudicated by board-certified ED physicians. Selective prediction, a method that allows a model to abstain from low-confidence predictions to improve overall reliability, was applied to assess the model's confidence and decision-making thresholds.</p><p><strong>Results: </strong>The LLM was significantly more effective in identifying deprescribing criteria (positive predictive value: 0.83; negative predictive value: 0.93; McNemar test for paired proportions: χ<sup>2</sup><sub>1</sub>=5.985; P=.02) relative to medical students, but showed limitations in making specific deprescribing recommendations (positive predictive value=0.47; negative predictive value=0.93). Adjudication revealed that while the model excelled at identifying when there was a deprescribing criterion related to one of the patient's medications, it often struggled with determining whether that criterion applied to the specific case due to complex inclusion and exclusion criteria (54.5% of errors) and ambiguous clinical contexts (eg, missing information; 39.3% of errors). Selective prediction only marginally improved LLM performance due to poorly calibrated confidence estimates.</p><p><strong>Conclusions: </strong>This study highlights the potential of LLMs to support deprescribing decisions in the ED by effectively filtering relevant criteria. However, challenges remain in applying these criteria to complex clinical scenarios, as the LLM demonstrated poor performance on more intricate decision-making tasks, with its reported confidence often failing to align with its actual success in these cases. The findings underscore the need for clearer deprescribing guidelines, improved LLM calibration for real-world use, and better integration of human-artificial intelligence workflows to balance artificial intelligence recommendations with clinician judgment.</p>","PeriodicalId":36245,"journal":{"name":"JMIR Aging","volume":"8 ","pages":"e69504"},"PeriodicalIF":4.8000,"publicationDate":"2025-04-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12032504/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Aging","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/69504","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"GERIATRICS & GERONTOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Polypharmacy, the concurrent use of multiple medications, is prevalent among older adults and associated with increased risks for adverse drug events including falls. Deprescribing, the systematic process of discontinuing potentially inappropriate medications, aims to mitigate these risks. However, the practical application of deprescribing criteria in emergency settings remains limited due to time constraints and criteria complexity.
Objective: This study aims to evaluate the performance of a large language model (LLM)-based pipeline in identifying deprescribing opportunities for older emergency department (ED) patients with polypharmacy, using 3 different sets of criteria: Beers, Screening Tool of Older People's Prescriptions, and Geriatric Emergency Medication Safety Recommendations. The study further evaluates LLM confidence calibration and its ability to improve recommendation performance.
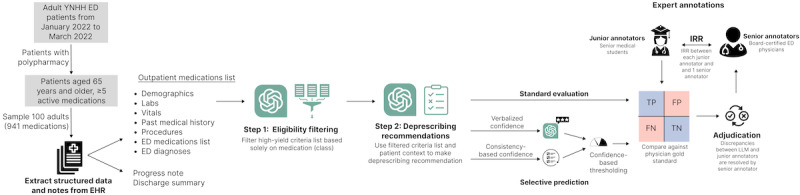
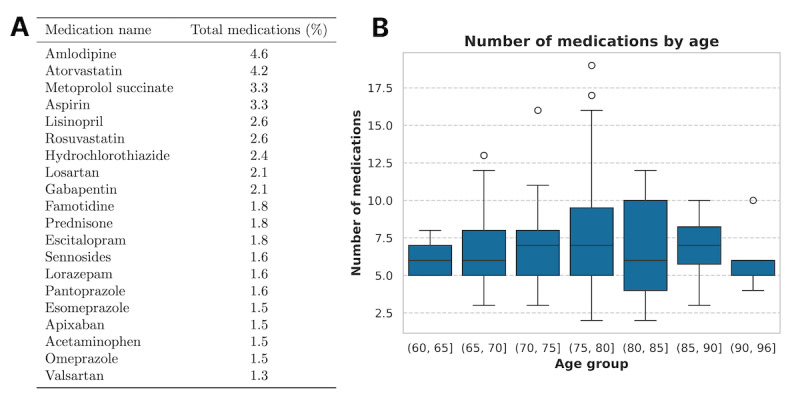
Methods: We conducted a retrospective cohort study of older adults presenting to an ED in a large academic medical center in the Northeast United States from January 2022 to March 2022. A random sample of 100 patients (712 total oral medications) was selected for detailed analysis. The LLM pipeline consisted of two steps: (1) filtering high-yield deprescribing criteria based on patients' medication lists, and (2) applying these criteria using both structured and unstructured patient data to recommend deprescribing. Model performance was assessed by comparing model recommendations to those of trained medical students, with discrepancies adjudicated by board-certified ED physicians. Selective prediction, a method that allows a model to abstain from low-confidence predictions to improve overall reliability, was applied to assess the model's confidence and decision-making thresholds.
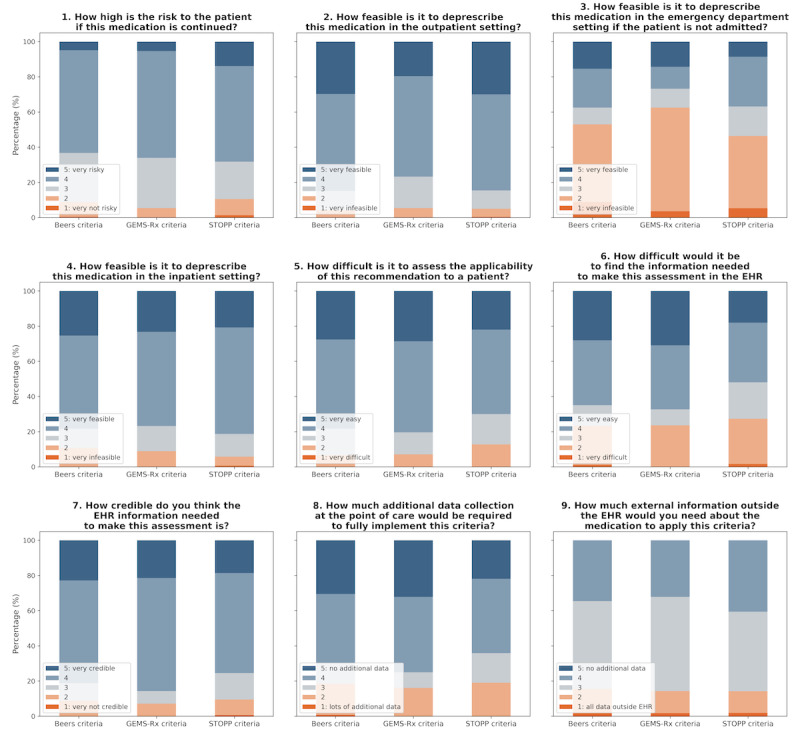
Results: The LLM was significantly more effective in identifying deprescribing criteria (positive predictive value: 0.83; negative predictive value: 0.93; McNemar test for paired proportions: χ21=5.985; P=.02) relative to medical students, but showed limitations in making specific deprescribing recommendations (positive predictive value=0.47; negative predictive value=0.93). Adjudication revealed that while the model excelled at identifying when there was a deprescribing criterion related to one of the patient's medications, it often struggled with determining whether that criterion applied to the specific case due to complex inclusion and exclusion criteria (54.5% of errors) and ambiguous clinical contexts (eg, missing information; 39.3% of errors). Selective prediction only marginally improved LLM performance due to poorly calibrated confidence estimates.
Conclusions: This study highlights the potential of LLMs to support deprescribing decisions in the ED by effectively filtering relevant criteria. However, challenges remain in applying these criteria to complex clinical scenarios, as the LLM demonstrated poor performance on more intricate decision-making tasks, with its reported confidence often failing to align with its actual success in these cases. The findings underscore the need for clearer deprescribing guidelines, improved LLM calibration for real-world use, and better integration of human-artificial intelligence workflows to balance artificial intelligence recommendations with clinician judgment.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


