Hilal Yağar, Ender Gümüşoğlu, Zeynel Mert Asfuroğlu
{"title":"Assessing the performance of ChatGPT-4o on the Turkish Orthopedics and Traumatology Board Examination.","authors":"Hilal Yağar, Ender Gümüşoğlu, Zeynel Mert Asfuroğlu","doi":"10.52312/jdrs.2025.1958","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>This study aims to assess the overall performance of ChatGPT version 4-omni (GPT-4o) on the Turkish Orthopedics and Traumatology Board Examination (TOTBE) using actual examinees as a reference point to evaluate and compare the performance of GPT-4o with that of human participants.</p><p><strong>Materials and methods: </strong>In this study, GPT-4o was tested with multiple-choice questions that formed the first step of 14 TOTBEs conducted between 2010 and 2023. The assessment of image-based questions was conducted separately for all exams. The questions were classified based on the subspecialties for the five exams (2010-2014). The performance of GPT-4o was assessed and compared to those of actual examinees of the TOTBE.</p><p><strong>Results: </strong>The mean total score of GPT-4o was 70.2±5.64 (range, 61 to 84), whereas that of actual examinees was 58±3.28 (range, 53.6 to 64.6). Considering accuracy rates, GPT-4o demonstrated 62% accuracy on image-based questions and 70% accuracy on text-based questions. It also demonstrated superior performance in the field of basic sciences, whereas actual examinees performed better in the specialty of reconstruction. Both GPT-4o and actual examinees exhibited the lowest scores in the subspecialty of lower extremity and foot.</p><p><strong>Conclusion: </strong>Our study results showed that GPT-4o performed well on the TOTBE, particularly in basic sciences. While it demonstrated accuracy comparable to actual examinees in some areas, these findings highlight its potential as a helpful tool in medical education.</p>","PeriodicalId":73560,"journal":{"name":"Joint diseases and related surgery","volume":"36 2","pages":"304-310"},"PeriodicalIF":1.9000,"publicationDate":"2025-04-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12086493/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Joint diseases and related surgery","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.52312/jdrs.2025.1958","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ORTHOPEDICS","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: This study aims to assess the overall performance of ChatGPT version 4-omni (GPT-4o) on the Turkish Orthopedics and Traumatology Board Examination (TOTBE) using actual examinees as a reference point to evaluate and compare the performance of GPT-4o with that of human participants.
Materials and methods: In this study, GPT-4o was tested with multiple-choice questions that formed the first step of 14 TOTBEs conducted between 2010 and 2023. The assessment of image-based questions was conducted separately for all exams. The questions were classified based on the subspecialties for the five exams (2010-2014). The performance of GPT-4o was assessed and compared to those of actual examinees of the TOTBE.
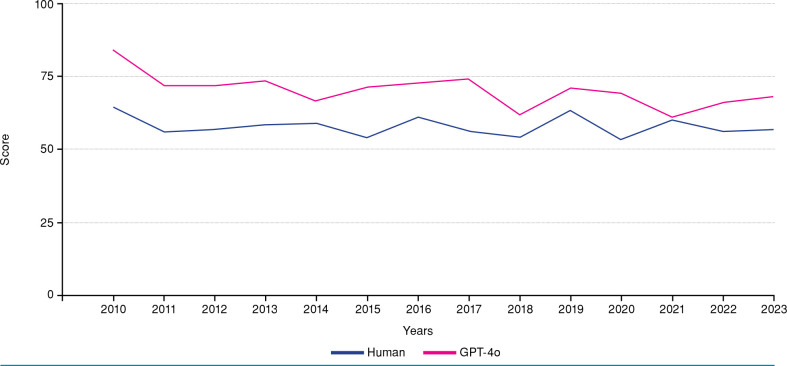
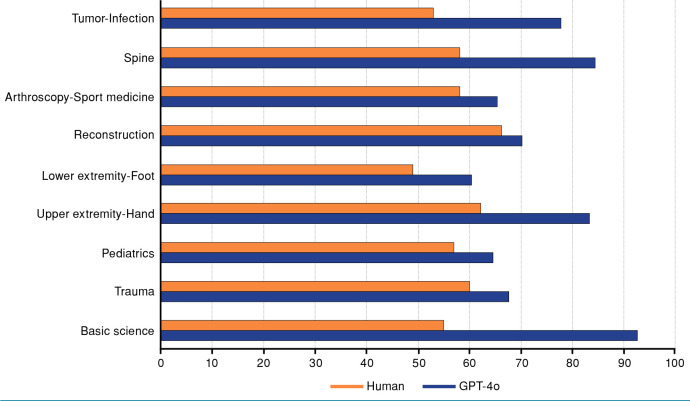
Results: The mean total score of GPT-4o was 70.2±5.64 (range, 61 to 84), whereas that of actual examinees was 58±3.28 (range, 53.6 to 64.6). Considering accuracy rates, GPT-4o demonstrated 62% accuracy on image-based questions and 70% accuracy on text-based questions. It also demonstrated superior performance in the field of basic sciences, whereas actual examinees performed better in the specialty of reconstruction. Both GPT-4o and actual examinees exhibited the lowest scores in the subspecialty of lower extremity and foot.
Conclusion: Our study results showed that GPT-4o performed well on the TOTBE, particularly in basic sciences. While it demonstrated accuracy comparable to actual examinees in some areas, these findings highlight its potential as a helpful tool in medical education.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


