Liz Salmi, Dana M Lewis, Jennifer L Clarke, Zhiyong Dong, Rudy Fischmann, Emily I McIntosh, Chethan R Sarabu, Catherine M DesRoches
{"title":"A proof-of-concept study for patient use of open notes with large language models.","authors":"Liz Salmi, Dana M Lewis, Jennifer L Clarke, Zhiyong Dong, Rudy Fischmann, Emily I McIntosh, Chethan R Sarabu, Catherine M DesRoches","doi":"10.1093/jamiaopen/ooaf021","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>The use of large language models (LLMs) is growing for both clinicians and patients. While researchers and clinicians have explored LLMs to manage patient portal messages and reduce burnout, there is less documentation about how patients use these tools to understand clinical notes and inform decision-making. This proof-of-concept study examined the reliability and accuracy of LLMs in responding to patient queries based on an open visit note.</p><p><strong>Materials and methods: </strong>In a cross-sectional proof-of-concept study, 3 commercially available LLMs (ChatGPT 4o, Claude 3 Opus, Gemini 1.5) were evaluated using 4 distinct prompt series-<i>Standard</i>, <i>Randomized</i>, <i>Persona</i>, and <i>Randomized Persona</i>-with multiple questions, designed by patients, in response to a single neuro-oncology progress note. LLM responses were scored by the note author (neuro-oncologist) and a patient who receives care from the note author, using an 8-criterion rubric that assessed <i>Accuracy</i>, <i>Relevance</i>, <i>Clarity</i>, <i>Actionability</i>, <i>Empathy/Tone</i>, <i>Completeness</i>, <i>Evidence</i>, and <i>Consistency</i>. Descriptive statistics were used to summarize the performance of each LLM across all prompts.</p><p><strong>Results: </strong>Overall, the Standard and Persona-based prompt series yielded the best results across all criterion regardless of LLM. Chat-GPT 4o using Persona-based prompts scored highest in all categories. All LLMs scored low in the use of <i>Evidence</i>.</p><p><strong>Discussion: </strong>This proof-of-concept study highlighted the potential for LLMs to assist patients in interpreting open notes. The most effective LLM responses were achieved by applying <i>Persona</i>-style prompts to a patient's question.</p><p><strong>Conclusion: </strong>Optimizing LLMs for patient-driven queries, and patient education and counseling around the use of LLMs, have potential to enhance patient use and understanding of their health information.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"8 2","pages":"ooaf021"},"PeriodicalIF":3.4000,"publicationDate":"2025-04-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11980777/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooaf021","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/4/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: The use of large language models (LLMs) is growing for both clinicians and patients. While researchers and clinicians have explored LLMs to manage patient portal messages and reduce burnout, there is less documentation about how patients use these tools to understand clinical notes and inform decision-making. This proof-of-concept study examined the reliability and accuracy of LLMs in responding to patient queries based on an open visit note.
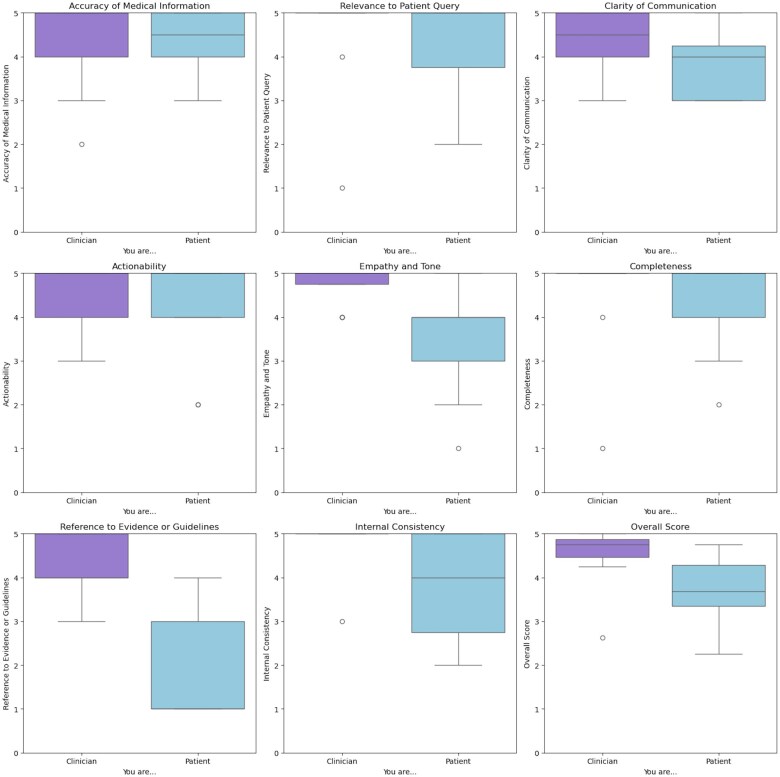
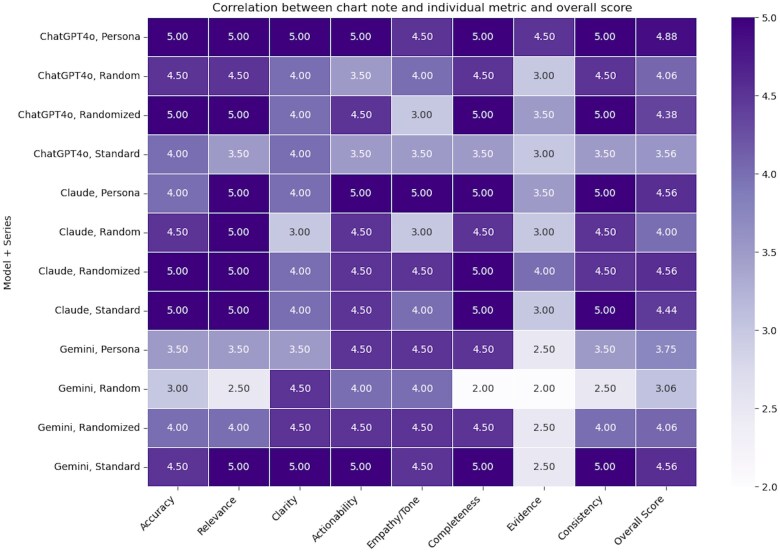
Materials and methods: In a cross-sectional proof-of-concept study, 3 commercially available LLMs (ChatGPT 4o, Claude 3 Opus, Gemini 1.5) were evaluated using 4 distinct prompt series-Standard, Randomized, Persona, and Randomized Persona-with multiple questions, designed by patients, in response to a single neuro-oncology progress note. LLM responses were scored by the note author (neuro-oncologist) and a patient who receives care from the note author, using an 8-criterion rubric that assessed Accuracy, Relevance, Clarity, Actionability, Empathy/Tone, Completeness, Evidence, and Consistency. Descriptive statistics were used to summarize the performance of each LLM across all prompts.
Results: Overall, the Standard and Persona-based prompt series yielded the best results across all criterion regardless of LLM. Chat-GPT 4o using Persona-based prompts scored highest in all categories. All LLMs scored low in the use of Evidence.
Discussion: This proof-of-concept study highlighted the potential for LLMs to assist patients in interpreting open notes. The most effective LLM responses were achieved by applying Persona-style prompts to a patient's question.
Conclusion: Optimizing LLMs for patient-driven queries, and patient education and counseling around the use of LLMs, have potential to enhance patient use and understanding of their health information.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


