Hirotaka Takita, Shannon L Walston, Yasuhito Mitsuyama, Ko Watanabe, Shoya Ishimaru, Daiju Ueda
{"title":"Comparative performance of large language models in structuring head CT radiology reports: multi-institutional validation study in Japan.","authors":"Hirotaka Takita, Shannon L Walston, Yasuhito Mitsuyama, Ko Watanabe, Shoya Ishimaru, Daiju Ueda","doi":"10.1007/s11604-025-01799-1","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>To compare the diagnostic performance of three proprietary large language models (LLMs)-Claude, GPT, and Gemini-in structuring free-text Japanese radiology reports for intracranial hemorrhage and skull fractures, and to assess the impact of three different prompting approaches on model accuracy.</p><p><strong>Materials and methods: </strong>In this retrospective study, head CT reports from the Japan Medical Imaging Database between 2018 and 2023 were collected. Two board-certified radiologists established the ground truth regarding intracranial hemorrhage and skull fractures through independent review and consensus. Each radiology report was analyzed by three LLMs using three prompting strategies-Standard, Chain of Thought, and Self Consistency prompting. Diagnostic performance (accuracy, precision, recall, and F1-score) was calculated for each LLM-prompt combination and compared using McNemar's tests with Bonferroni correction. Misclassified cases underwent qualitative error analysis.</p><p><strong>Results: </strong>A total of 3949 head CT reports from 3949 patients (mean age 59 ± 25 years, 56.2% male) were enrolled. Across all institutions, 856 patients (21.6%) had intracranial hemorrhage and 264 patients (6.6%) had skull fractures. All nine LLM-prompt combinations achieved very high accuracy. Claude demonstrated significantly higher accuracy for intracranial hemorrhage than GPT and Gemini, and also outperformed Gemini for skull fractures (p < 0.0001). Gemini's performance improved notably with Chain of Thought prompting. Error analysis revealed common challenges including ambiguous phrases and findings unrelated to intracranial hemorrhage or skull fractures, underscoring the importance of careful prompt design.</p><p><strong>Conclusion: </strong>All three proprietary LLMs exhibited strong performance in structuring free-text head CT reports for intracranial hemorrhage and skull fractures. While the choice of prompting method influenced accuracy, all models demonstrated robust potential for clinical and research applications. Future work should refine the prompts and validate these approaches in prospective, multilingual settings.</p>","PeriodicalId":14691,"journal":{"name":"Japanese Journal of Radiology","volume":" ","pages":"1445-1455"},"PeriodicalIF":2.1000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12396994/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Japanese Journal of Radiology","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s11604-025-01799-1","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/5/14 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
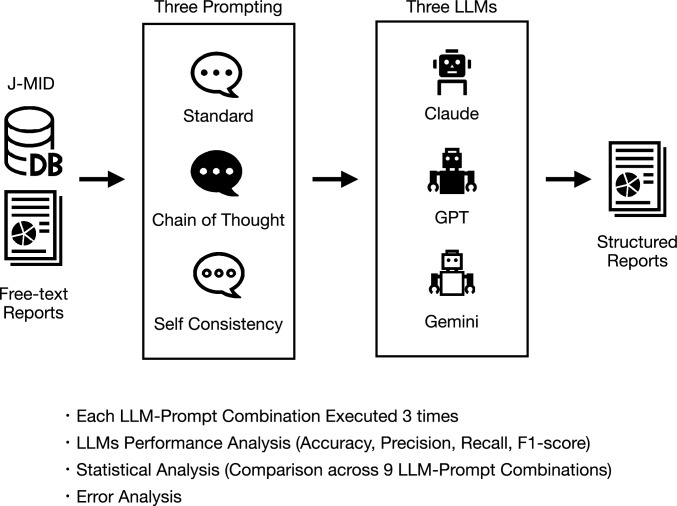
Purpose: To compare the diagnostic performance of three proprietary large language models (LLMs)-Claude, GPT, and Gemini-in structuring free-text Japanese radiology reports for intracranial hemorrhage and skull fractures, and to assess the impact of three different prompting approaches on model accuracy.
Materials and methods: In this retrospective study, head CT reports from the Japan Medical Imaging Database between 2018 and 2023 were collected. Two board-certified radiologists established the ground truth regarding intracranial hemorrhage and skull fractures through independent review and consensus. Each radiology report was analyzed by three LLMs using three prompting strategies-Standard, Chain of Thought, and Self Consistency prompting. Diagnostic performance (accuracy, precision, recall, and F1-score) was calculated for each LLM-prompt combination and compared using McNemar's tests with Bonferroni correction. Misclassified cases underwent qualitative error analysis.
Results: A total of 3949 head CT reports from 3949 patients (mean age 59 ± 25 years, 56.2% male) were enrolled. Across all institutions, 856 patients (21.6%) had intracranial hemorrhage and 264 patients (6.6%) had skull fractures. All nine LLM-prompt combinations achieved very high accuracy. Claude demonstrated significantly higher accuracy for intracranial hemorrhage than GPT and Gemini, and also outperformed Gemini for skull fractures (p < 0.0001). Gemini's performance improved notably with Chain of Thought prompting. Error analysis revealed common challenges including ambiguous phrases and findings unrelated to intracranial hemorrhage or skull fractures, underscoring the importance of careful prompt design.
Conclusion: All three proprietary LLMs exhibited strong performance in structuring free-text head CT reports for intracranial hemorrhage and skull fractures. While the choice of prompting method influenced accuracy, all models demonstrated robust potential for clinical and research applications. Future work should refine the prompts and validate these approaches in prospective, multilingual settings.
期刊介绍:
Japanese Journal of Radiology is a peer-reviewed journal, officially published by the Japan Radiological Society. The main purpose of the journal is to provide a forum for the publication of papers documenting recent advances and new developments in the field of radiology in medicine and biology. The scope of Japanese Journal of Radiology encompasses but is not restricted to diagnostic radiology, interventional radiology, radiation oncology, nuclear medicine, radiation physics, and radiation biology. Additionally, the journal covers technical and industrial innovations. The journal welcomes original articles, technical notes, review articles, pictorial essays and letters to the editor. The journal also provides announcements from the boards and the committees of the society. Membership in the Japan Radiological Society is not a prerequisite for submission. Contributions are welcomed from all parts of the world.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


