{"title":"Preliminary assessment of large language models' performance in answering questions on developmental dysplasia of the hip.","authors":"Shiwei Li, Jun Jiang, Xiaodong Yang","doi":"10.1177/18632521251331772","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>To evaluate the performance of three large language models in answering questions regarding pediatric developmental dysplasia of the hip.</p><p><strong>Methods: </strong>We formulated 18 open-ended clinical questions in both Chinese and English and established a gold standard set of answers to benchmark the responses of the large language models. These questions were presented to ChatGPT-4o, Gemini, and Claude 3.5 Sonnet. The responses were evaluated by two independent reviewers using a 5-point scale. The average score, rounded to the nearest whole number, was taken as the final score. A final score of 4 or 5 indicated an accurate response, whereas a final score of 1, 2, or 3 indicated an inaccurate response.</p><p><strong>Results: </strong>The raters demonstrated a high level of agreement in scoring the answers, with weighted Kappa coefficients of 0.865 for Chinese responses (<i>p</i> < 0.001) and 0.875 for English responses (<i>p</i> < 0.001). No significant differences were observed among the three large language models in terms of accuracy when answering questions, with rates of 83.3%, 77.8%, and 77.8% for Claude 3.5 Sonnet, ChatGPT-4o, and Gemini in the Chinese responses (<i>p</i> = 1), and 83.3%, 83.3%, and 72.2% for ChatGPT-4o, Claude 3.5 Sonnet, and Gemini in the English responses (<i>p</i> = 0.761). In addition, there was no significant difference in the performance of the same large language model between the Chinese and English settings.</p><p><strong>Conclusions: </strong>Large language models demonstrate high accuracy in delivering information on dysplasia of the hip, maintaining consistent performance across both Chinese and English, which suggests their potential utility as medical support tools.</p><p><strong>Level of evidence: </strong>Level II.</p>","PeriodicalId":56060,"journal":{"name":"Journal of Childrens Orthopaedics","volume":" ","pages":"207-212"},"PeriodicalIF":1.6000,"publicationDate":"2025-04-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11999979/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Childrens Orthopaedics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1177/18632521251331772","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/6/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"ORTHOPEDICS","Score":null,"Total":0}
引用次数: 0
Abstract
Objective: To evaluate the performance of three large language models in answering questions regarding pediatric developmental dysplasia of the hip.
Methods: We formulated 18 open-ended clinical questions in both Chinese and English and established a gold standard set of answers to benchmark the responses of the large language models. These questions were presented to ChatGPT-4o, Gemini, and Claude 3.5 Sonnet. The responses were evaluated by two independent reviewers using a 5-point scale. The average score, rounded to the nearest whole number, was taken as the final score. A final score of 4 or 5 indicated an accurate response, whereas a final score of 1, 2, or 3 indicated an inaccurate response.
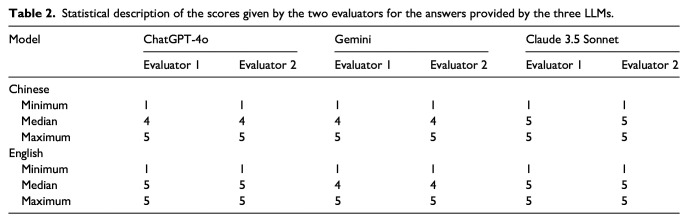
Results: The raters demonstrated a high level of agreement in scoring the answers, with weighted Kappa coefficients of 0.865 for Chinese responses (p < 0.001) and 0.875 for English responses (p < 0.001). No significant differences were observed among the three large language models in terms of accuracy when answering questions, with rates of 83.3%, 77.8%, and 77.8% for Claude 3.5 Sonnet, ChatGPT-4o, and Gemini in the Chinese responses (p = 1), and 83.3%, 83.3%, and 72.2% for ChatGPT-4o, Claude 3.5 Sonnet, and Gemini in the English responses (p = 0.761). In addition, there was no significant difference in the performance of the same large language model between the Chinese and English settings.
Conclusions: Large language models demonstrate high accuracy in delivering information on dysplasia of the hip, maintaining consistent performance across both Chinese and English, which suggests their potential utility as medical support tools.
期刊介绍:
Aims & Scope
The Journal of Children’s Orthopaedics is the official journal of the European Paediatric Orthopaedic Society (EPOS) and is published by The British Editorial Society of Bone & Joint Surgery.
It provides a forum for the advancement of the knowledge and education in paediatric orthopaedics and traumatology across geographical borders. It advocates an increased worldwide involvement in preventing and treating musculoskeletal diseases in children and adolescents.
The journal publishes high quality, peer-reviewed articles that focus on clinical practice, diagnosis and treatment of disorders unique to paediatric orthopaedics, as well as on basic and applied research. It aims to help physicians stay abreast of the latest and ever-changing developments in the field of paediatric orthopaedics and traumatology.
The journal welcomes original contributions submitted exclusively for review to the journal. This continuously published online journal is fully open access and will publish one print issue each year to coincide with the EPOS Annual Congress, featuring the meeting’s abstracts.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


