Levi Kaster, Ethan Hillis, Inez Y Oh, Bhooma R Aravamuthan, Virginia C Lanzotti, Casey R Vickstrom, Christina A Gurnett, Philip R O Payne, Aditi Gupta
{"title":"Automated extraction of functional biomarkers of verbal and ambulatory ability from multi-institutional clinical notes using large language models.","authors":"Levi Kaster, Ethan Hillis, Inez Y Oh, Bhooma R Aravamuthan, Virginia C Lanzotti, Casey R Vickstrom, Christina A Gurnett, Philip R O Payne, Aditi Gupta","doi":"10.1186/s11689-025-09612-w","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Functional biomarkers in neurodevelopmental disorders, such as verbal and ambulatory abilities, are essential for clinical care and research activities. Treatment planning, intervention monitoring, and identifying comorbid conditions in individuals with intellectual and developmental disabilities (IDDs) rely on standardized assessments of these abilities. However, traditional assessments impose a burden on patients and providers, often leading to longitudinal inconsistencies and inequities due to evolving guidelines and associated time-cost. Therefore, this study aimed to develop an automated approach to classify verbal and ambulatory abilities from EHR data of IDD and cerebral palsy (CP) patients. Application of large language models (LLMs) to clinical notes, which are rich in longitudinal data, may provide a low-burden pipeline for extracting functional biomarkers efficiently and accurately.</p><p><strong>Methods: </strong>Data from the multi-institutional National Brain Gene Registry (BGR) and a CP clinic cohort were utilized, comprising 3,245 notes from 125 individuals and 5,462 clinical notes from 260 individuals, respectively. Employing three LLMs-GPT-3.5 Turbo, GPT-4 Turbo, and GPT-4 Omni-we provided the models with a clinical note and utilized a detailed conversational format to prompt the models to answer: \"Does the individual use any words?\" and \"Can the individual walk without aid?\" These responses were evaluated against ground-truth abilities, which were established using neurobehavioral assessments collected for each dataset.</p><p><strong>Results: </strong>LLM pipelines demonstrated high accuracy (weighted-F1 scores > .90) in predicting ambulatory ability for both cohorts, likely due to the consistent use of Gross Motor Functional Classification System (GMFCS) as a consistent ground-truth standard. However, verbal ability predictions were more accurate in the BGR cohort, likely due to higher adherence between the prompt and ground-truth assessment questions. While LLMs can be computationally expensive, analysis of our protocol affirmed the cost effectiveness when applied to select notes from the EHR.</p><p><strong>Conclusions: </strong>LLMs are effective at extracting functional biomarkers from EHR data and broadly generalizable across variable note-taking practices and institutions. Individual verbal and ambulatory ability were accurately extracted, supporting the method's ability to streamline workflows by offering automated, efficient data extraction for patient care and research. Future studies are needed to extend this methodology to additional populations and to demonstrate more granular functional data classification.</p>","PeriodicalId":16530,"journal":{"name":"Journal of Neurodevelopmental Disorders","volume":"17 1","pages":"24"},"PeriodicalIF":4.0000,"publicationDate":"2025-04-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12042395/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Neurodevelopmental Disorders","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1186/s11689-025-09612-w","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CLINICAL NEUROLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Functional biomarkers in neurodevelopmental disorders, such as verbal and ambulatory abilities, are essential for clinical care and research activities. Treatment planning, intervention monitoring, and identifying comorbid conditions in individuals with intellectual and developmental disabilities (IDDs) rely on standardized assessments of these abilities. However, traditional assessments impose a burden on patients and providers, often leading to longitudinal inconsistencies and inequities due to evolving guidelines and associated time-cost. Therefore, this study aimed to develop an automated approach to classify verbal and ambulatory abilities from EHR data of IDD and cerebral palsy (CP) patients. Application of large language models (LLMs) to clinical notes, which are rich in longitudinal data, may provide a low-burden pipeline for extracting functional biomarkers efficiently and accurately.
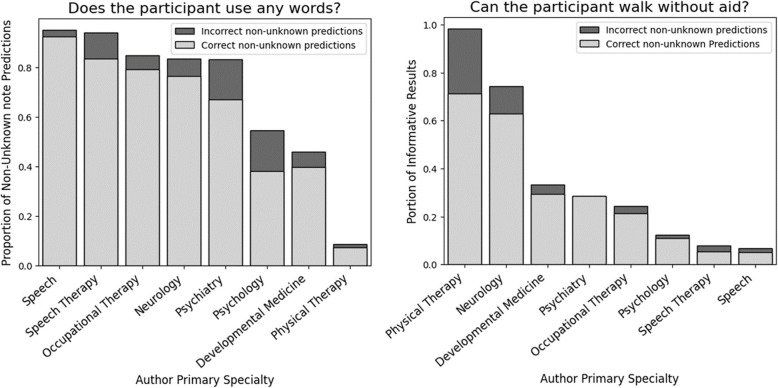
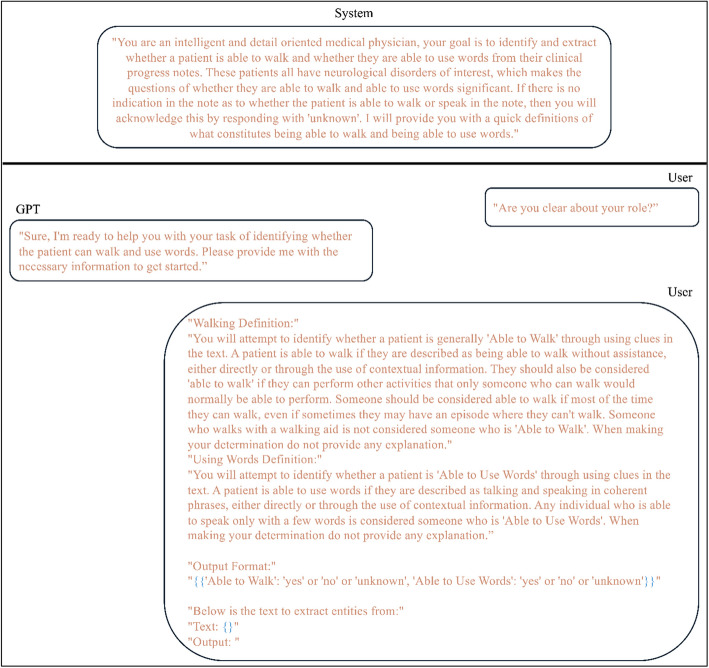
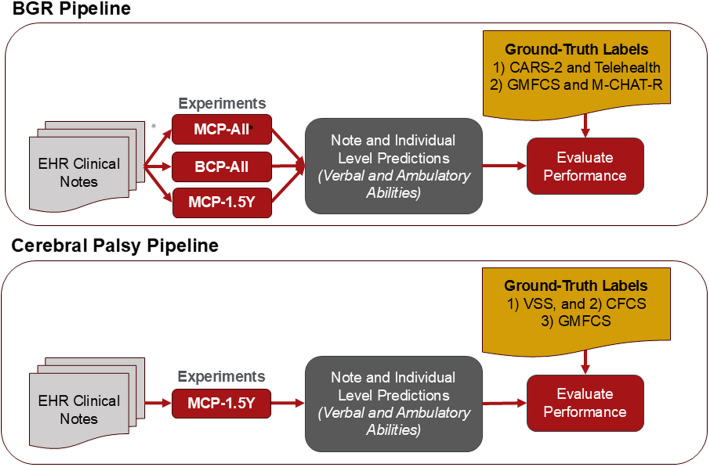
Methods: Data from the multi-institutional National Brain Gene Registry (BGR) and a CP clinic cohort were utilized, comprising 3,245 notes from 125 individuals and 5,462 clinical notes from 260 individuals, respectively. Employing three LLMs-GPT-3.5 Turbo, GPT-4 Turbo, and GPT-4 Omni-we provided the models with a clinical note and utilized a detailed conversational format to prompt the models to answer: "Does the individual use any words?" and "Can the individual walk without aid?" These responses were evaluated against ground-truth abilities, which were established using neurobehavioral assessments collected for each dataset.
Results: LLM pipelines demonstrated high accuracy (weighted-F1 scores > .90) in predicting ambulatory ability for both cohorts, likely due to the consistent use of Gross Motor Functional Classification System (GMFCS) as a consistent ground-truth standard. However, verbal ability predictions were more accurate in the BGR cohort, likely due to higher adherence between the prompt and ground-truth assessment questions. While LLMs can be computationally expensive, analysis of our protocol affirmed the cost effectiveness when applied to select notes from the EHR.
Conclusions: LLMs are effective at extracting functional biomarkers from EHR data and broadly generalizable across variable note-taking practices and institutions. Individual verbal and ambulatory ability were accurately extracted, supporting the method's ability to streamline workflows by offering automated, efficient data extraction for patient care and research. Future studies are needed to extend this methodology to additional populations and to demonstrate more granular functional data classification.
期刊介绍:
Journal of Neurodevelopmental Disorders is an open access journal that integrates current, cutting-edge research across a number of disciplines, including neurobiology, genetics, cognitive neuroscience, psychiatry and psychology. The journal’s primary focus is on the pathogenesis of neurodevelopmental disorders including autism, fragile X syndrome, tuberous sclerosis, Turner Syndrome, 22q Deletion Syndrome, Prader-Willi and Angelman Syndrome, Williams syndrome, lysosomal storage diseases, dyslexia, specific language impairment and fetal alcohol syndrome. With the discovery of specific genes underlying neurodevelopmental syndromes, the emergence of powerful tools for studying neural circuitry, and the development of new approaches for exploring molecular mechanisms, interdisciplinary research on the pathogenesis of neurodevelopmental disorders is now increasingly common. Journal of Neurodevelopmental Disorders provides a unique venue for researchers interested in comparing and contrasting mechanisms and characteristics related to the pathogenesis of the full range of neurodevelopmental disorders, sharpening our understanding of the etiology and relevant phenotypes of each condition.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


