Lossless data compression by large models
IF 23.9
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
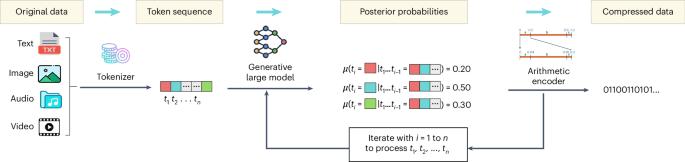
Data compression is a fundamental technology that enables efficient storage and transmission of information. However, traditional compression methods are approaching their theoretical limits after 80 years of research and development. At the same time, large artificial intelligence models have emerged, which, trained on vast amounts of data, are able to ‘understand’ various semantics. Intuitively, semantics conveys the meaning of data concisely, so large models hold the potential to revolutionize compression technology. Here we present LMCompress, a new method that leverages large models to compress data. LMCompress shatters all previous lossless compression records on four media types: text, images, video and audio. It halves the compression rates of JPEG-XL for images, FLAC for audio and H.264 for video, and it achieves nearly one-third of the compression rates of zpaq for text. Our results demonstrate that the better a model understands the data, the more effectively it can compress it, suggesting a deep connection between understanding and compression. Effective lossless compression requires that frequent patterns in the data can be identified. Li et al. explore using deep learning models to more effectively compress text, audio and video data.

大型模型的无损数据压缩
数据压缩是实现信息高效存储和传输的一项基础技术。然而,经过80年的研究和发展,传统的压缩方法正在接近其理论极限。与此同时,大型人工智能模型已经出现,这些模型经过大量数据的训练,能够“理解”各种语义。直观地说,语义简洁地传达了数据的含义,因此大型模型具有革新压缩技术的潜力。在这里,我们提出了LMCompress,一种利用大型模型来压缩数据的新方法。LMCompress打破了四种媒体类型上所有以前的无损压缩记录:文本,图像,视频和音频。它的图像压缩率是JPEG-XL的一半,音频压缩率是FLAC,视频压缩率是H.264,文本压缩率是zpaq的近三分之一。我们的研究结果表明,一个模型对数据的理解越好,它就能越有效地压缩数据,这表明理解和压缩之间存在着深刻的联系。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Nature Machine Intelligence
Multiple-
CiteScore
36.90
自引率
2.10%
发文量
127
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


