Sebastian Duesing, Jason Bennett, James A Overton, Randi Vita, Bjoern Peters
{"title":"Standardizing free-text data exemplified by two fields from the Immune Epitope Database.","authors":"Sebastian Duesing, Jason Bennett, James A Overton, Randi Vita, Bjoern Peters","doi":"10.1186/s13326-025-00324-7","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>While unstructured data, such as free text, constitutes a large amount of publicly available biomedical data, it is underutilized in automated analyses due to the difficulty of extracting meaning from it. Normalizing free-text data, i.e., removing inessential variance, enables the use of structured vocabularies like ontologies to represent the data and allow for harmonized queries over it. This paper presents an adaptable tool for free-text normalization and an evaluation of the application of this tool to two different fields curated from the literature in the Immune Epitope Database (IEDB): \"age\" and \"data-location\" (the part of a paper in which data was found).</p><p><strong>Results: </strong>Free text entries for the database fields for subject age (4095 distinct values) and publication data-location (251,810 distinct values) in the IEDB were analyzed. Normalization was performed in three steps, namely character normalization, word normalization, and phrase normalization, using generalizable rules developed and applied with the tool presented in this manuscript. For the age dataset, in the character stage, the application of 21 rules resulted in 99.97% output validity; in the word stage, the application of 94 rules resulted in 98.06% output validity; and in the phrase stage, the application of 16 rules resulted in 83.81% output validity. For the data-location dataset, in the character stage, the application of 39 rules resulted in 99.99% output validity; in the word stage, the application of 187 rules resulted in 98.46% output validity; and in the phrase stage, the application of 12 rules resulted in 97.95% output validity.</p><p><strong>Conclusions: </strong>We developed a generalizable approach for normalization of free text as found in database fields with content on a specific topic. Creating and testing the rules took a one-time effort for a given field that can now be applied to data as it is being curated. The standardization achieved in two datasets tested produces significantly reduced variance in the content which enhances the findability and usability of that data, chiefly by improving search functionality and enabling linkages with formal ontologies.</p>","PeriodicalId":15055,"journal":{"name":"Journal of Biomedical Semantics","volume":"16 1","pages":"5"},"PeriodicalIF":2.0000,"publicationDate":"2025-03-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11929277/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Semantics","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1186/s13326-025-00324-7","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: While unstructured data, such as free text, constitutes a large amount of publicly available biomedical data, it is underutilized in automated analyses due to the difficulty of extracting meaning from it. Normalizing free-text data, i.e., removing inessential variance, enables the use of structured vocabularies like ontologies to represent the data and allow for harmonized queries over it. This paper presents an adaptable tool for free-text normalization and an evaluation of the application of this tool to two different fields curated from the literature in the Immune Epitope Database (IEDB): "age" and "data-location" (the part of a paper in which data was found).
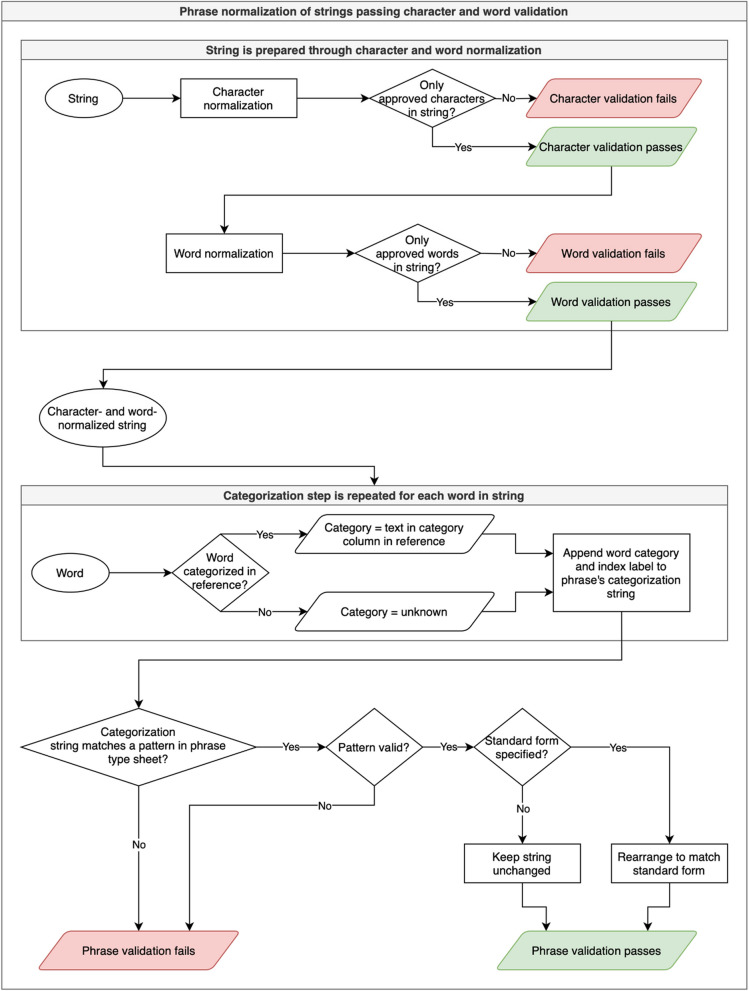
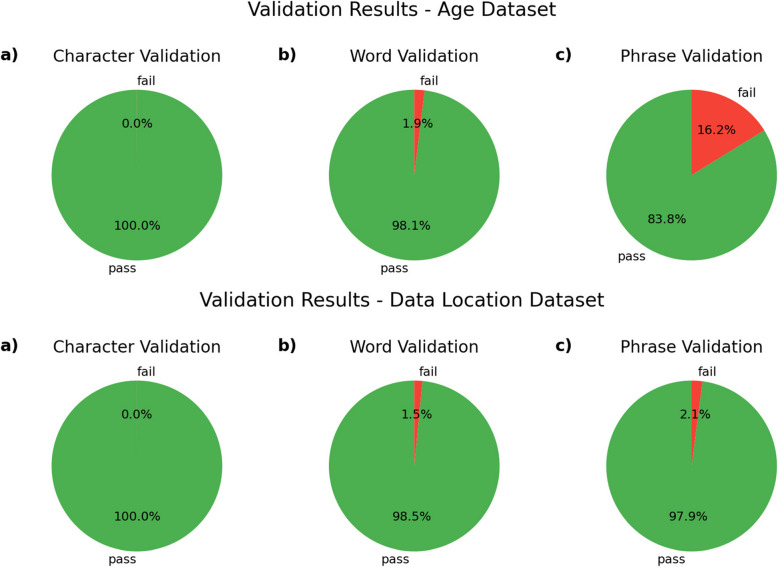
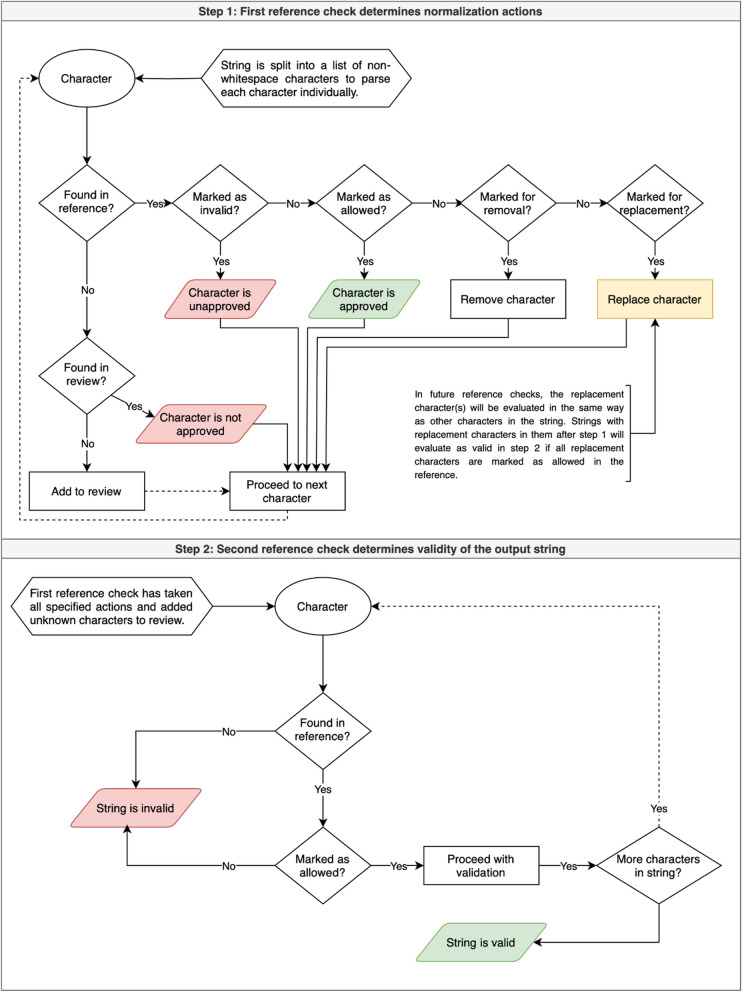
Results: Free text entries for the database fields for subject age (4095 distinct values) and publication data-location (251,810 distinct values) in the IEDB were analyzed. Normalization was performed in three steps, namely character normalization, word normalization, and phrase normalization, using generalizable rules developed and applied with the tool presented in this manuscript. For the age dataset, in the character stage, the application of 21 rules resulted in 99.97% output validity; in the word stage, the application of 94 rules resulted in 98.06% output validity; and in the phrase stage, the application of 16 rules resulted in 83.81% output validity. For the data-location dataset, in the character stage, the application of 39 rules resulted in 99.99% output validity; in the word stage, the application of 187 rules resulted in 98.46% output validity; and in the phrase stage, the application of 12 rules resulted in 97.95% output validity.
Conclusions: We developed a generalizable approach for normalization of free text as found in database fields with content on a specific topic. Creating and testing the rules took a one-time effort for a given field that can now be applied to data as it is being curated. The standardization achieved in two datasets tested produces significantly reduced variance in the content which enhances the findability and usability of that data, chiefly by improving search functionality and enabling linkages with formal ontologies.
期刊介绍:
Journal of Biomedical Semantics addresses issues of semantic enrichment and semantic processing in the biomedical domain. The scope of the journal covers two main areas:
Infrastructure for biomedical semantics: focusing on semantic resources and repositories, meta-data management and resource description, knowledge representation and semantic frameworks, the Biomedical Semantic Web, and semantic interoperability.
Semantic mining, annotation, and analysis: focusing on approaches and applications of semantic resources; and tools for investigation, reasoning, prediction, and discoveries in biomedicine.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


