Rohan Sanghera, Arun James Thirunavukarasu, Marc El Khoury, Jessica O'Logbon, Yuqing Chen, Archie Watt, Mustafa Mahmood, Hamid Butt, George Nishimura, Andrew A S Soltan
{"title":"High-performance automated abstract screening with large language model ensembles.","authors":"Rohan Sanghera, Arun James Thirunavukarasu, Marc El Khoury, Jessica O'Logbon, Yuqing Chen, Archie Watt, Mustafa Mahmood, Hamid Butt, George Nishimura, Andrew A S Soltan","doi":"10.1093/jamia/ocaf050","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>screening is a labor-intensive component of systematic review involving repetitive application of inclusion and exclusion criteria on a large volume of studies. We aimed to validate large language models (LLMs) used to automate abstract screening.</p><p><strong>Materials and methods: </strong>LLMs (GPT-3.5 Turbo, GPT-4 Turbo, GPT-4o, Llama 3 70B, Gemini 1.5 Pro, and Claude Sonnet 3.5) were trialed across 23 Cochrane Library systematic reviews to evaluate their accuracy in zero-shot binary classification for abstract screening. Initial evaluation on a balanced development dataset (n = 800) identified optimal prompting strategies, and the best performing LLM-prompt combinations were then validated on a comprehensive dataset of replicated search results (n = 119 695).</p><p><strong>Results: </strong>On the development dataset, LLMs exhibited superior performance to human researchers in terms of sensitivity (LLMmax = 1.000, humanmax = 0.775), precision (LLMmax = 0.927, humanmax = 0.911), and balanced accuracy (LLMmax = 0.904, humanmax = 0.865). When evaluated on the comprehensive dataset, the best performing LLM-prompt combinations exhibited consistent sensitivity (range 0.756-1.000) but diminished precision (range 0.004-0.096) due to class imbalance. In addition, 66 LLM-human and LLM-LLM ensembles exhibited perfect sensitivity with a maximal precision of 0.458 with the development dataset, decreasing to 0.1450 over the comprehensive dataset; but conferring workload reductions ranging between 37.55% and 99.11%.</p><p><strong>Discussion: </strong>Automated abstract screening can reduce the screening workload in systematic review while maintaining quality. Performance variation between reviews highlights the importance of domain-specific validation before autonomous deployment. LLM-human ensembles can achieve similar benefits while maintaining human oversight over all records.</p><p><strong>Conclusion: </strong>LLMs may reduce the human labor cost of systematic review with maintained or improved accuracy, thereby increasing the efficiency and quality of evidence synthesis.</p>","PeriodicalId":50016,"journal":{"name":"Journal of the American Medical Informatics Association","volume":" ","pages":"893-904"},"PeriodicalIF":4.6000,"publicationDate":"2025-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12012331/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of the American Medical Informatics Association","FirstCategoryId":"91","ListUrlMain":"https://doi.org/10.1093/jamia/ocaf050","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
Objective: screening is a labor-intensive component of systematic review involving repetitive application of inclusion and exclusion criteria on a large volume of studies. We aimed to validate large language models (LLMs) used to automate abstract screening.
Materials and methods: LLMs (GPT-3.5 Turbo, GPT-4 Turbo, GPT-4o, Llama 3 70B, Gemini 1.5 Pro, and Claude Sonnet 3.5) were trialed across 23 Cochrane Library systematic reviews to evaluate their accuracy in zero-shot binary classification for abstract screening. Initial evaluation on a balanced development dataset (n = 800) identified optimal prompting strategies, and the best performing LLM-prompt combinations were then validated on a comprehensive dataset of replicated search results (n = 119 695).
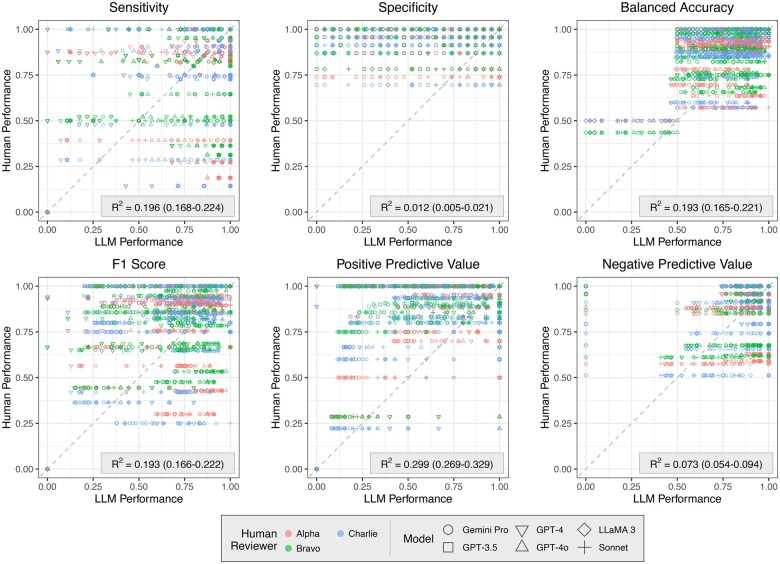
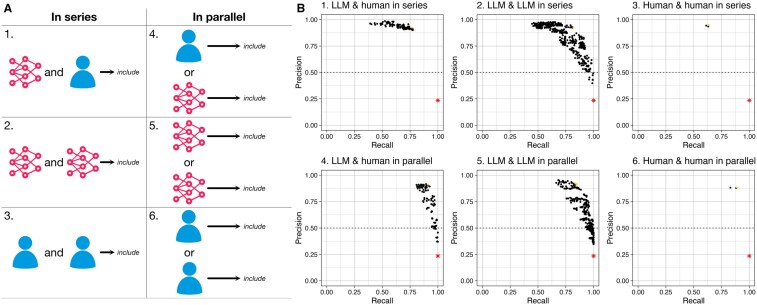
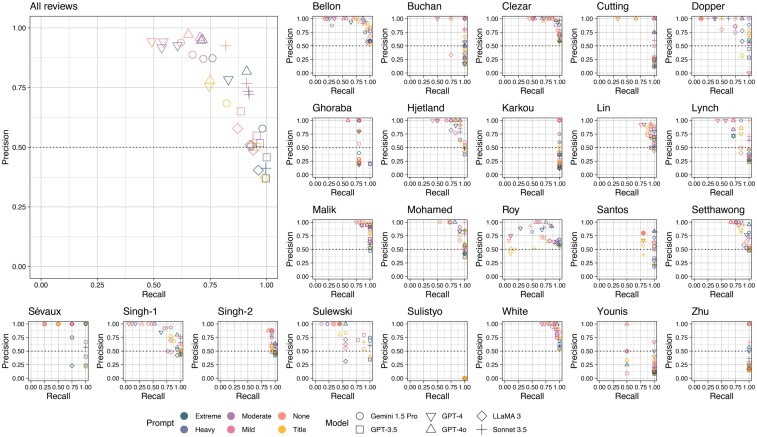
Results: On the development dataset, LLMs exhibited superior performance to human researchers in terms of sensitivity (LLMmax = 1.000, humanmax = 0.775), precision (LLMmax = 0.927, humanmax = 0.911), and balanced accuracy (LLMmax = 0.904, humanmax = 0.865). When evaluated on the comprehensive dataset, the best performing LLM-prompt combinations exhibited consistent sensitivity (range 0.756-1.000) but diminished precision (range 0.004-0.096) due to class imbalance. In addition, 66 LLM-human and LLM-LLM ensembles exhibited perfect sensitivity with a maximal precision of 0.458 with the development dataset, decreasing to 0.1450 over the comprehensive dataset; but conferring workload reductions ranging between 37.55% and 99.11%.
Discussion: Automated abstract screening can reduce the screening workload in systematic review while maintaining quality. Performance variation between reviews highlights the importance of domain-specific validation before autonomous deployment. LLM-human ensembles can achieve similar benefits while maintaining human oversight over all records.
Conclusion: LLMs may reduce the human labor cost of systematic review with maintained or improved accuracy, thereby increasing the efficiency and quality of evidence synthesis.
期刊介绍:
JAMIA is AMIA''s premier peer-reviewed journal for biomedical and health informatics. Covering the full spectrum of activities in the field, JAMIA includes informatics articles in the areas of clinical care, clinical research, translational science, implementation science, imaging, education, consumer health, public health, and policy. JAMIA''s articles describe innovative informatics research and systems that help to advance biomedical science and to promote health. Case reports, perspectives and reviews also help readers stay connected with the most important informatics developments in implementation, policy and education.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


