Loic Ah-Thiane, Pierre-Etienne Heudel, Mario Campone, Marie Robert, Victoire Brillaud-Meflah, Caroline Rousseau, Magali Le Blanc-Onfroy, Florine Tomaszewski, Stéphane Supiot, Tanguy Perennec, Augustin Mervoyer, Jean-Sébastien Frenel
{"title":"Large Language Models as Decision-Making Tools in Oncology: Comparing Artificial Intelligence Suggestions and Expert Recommendations.","authors":"Loic Ah-Thiane, Pierre-Etienne Heudel, Mario Campone, Marie Robert, Victoire Brillaud-Meflah, Caroline Rousseau, Magali Le Blanc-Onfroy, Florine Tomaszewski, Stéphane Supiot, Tanguy Perennec, Augustin Mervoyer, Jean-Sébastien Frenel","doi":"10.1200/CCI-24-00230","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>To determine the accuracy of large language models (LLMs) in generating appropriate treatment options for patients with early breast cancer on the basis of their medical records.</p><p><strong>Materials and methods: </strong>Retrospective study using anonymized medical records of patients with BC presented during multidisciplinary team meetings (MDTs) between January and April 2024. Three generalist artificial intelligence models (Claude3-Opus, GPT4-Turbo, and LLaMa3-70B) were used to generate treatment suggestions, which were compared with experts' decisions. The primary outcome was the rate of appropriate suggestions from the LLMs, compared with the reference experts' decisions. The secondary outcome was the LLMs' performances (F1 score and specificity) in generating appropriate suggestions for each treatment category.</p><p><strong>Results: </strong>The rates of appropriate suggestions were 86.6% (97/112), 85.7% (96/112), and 75.0% (84/112) for Claude3-Opus, GPT4-Turbo, and LLaMa3-70B, respectively. No significant difference was found between Claude3-Opus and GPT4-Turbo (<i>P</i> = .85), but both tended to perform better than LLaMa3-70B (<i>P</i> = .027 and <i>P</i> = .043, respectively). LLMs showed high accuracy for adjuvant endocrine therapy and targeted therapy indications. However, they tended to overestimate the need for adjuvant radiotherapy and had variable performances in suggesting adjuvant chemotherapy and genomic tests.</p><p><strong>Conclusion: </strong>LLMs, particularly Claude3-Opus and GPT4-Turbo, demonstrated promising accuracy in suggesting appropriate adjuvant treatments for patients with early BC on the basis of their medical records. Although LLMs showed limitations in validating surgery and indicating genomic tests, their performance in other treatment modalities highlights their potential to automate and augment decision making during MDTs. Further studies with fine-tuned LLMs and a prospective design are needed to demonstrate their utility in clinical practice.</p>","PeriodicalId":51626,"journal":{"name":"JCO Clinical Cancer Informatics","volume":"9 ","pages":"e2400230"},"PeriodicalIF":2.8000,"publicationDate":"2025-03-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11949217/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JCO Clinical Cancer Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1200/CCI-24-00230","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/3/20 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"ONCOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Purpose: To determine the accuracy of large language models (LLMs) in generating appropriate treatment options for patients with early breast cancer on the basis of their medical records.
Materials and methods: Retrospective study using anonymized medical records of patients with BC presented during multidisciplinary team meetings (MDTs) between January and April 2024. Three generalist artificial intelligence models (Claude3-Opus, GPT4-Turbo, and LLaMa3-70B) were used to generate treatment suggestions, which were compared with experts' decisions. The primary outcome was the rate of appropriate suggestions from the LLMs, compared with the reference experts' decisions. The secondary outcome was the LLMs' performances (F1 score and specificity) in generating appropriate suggestions for each treatment category.
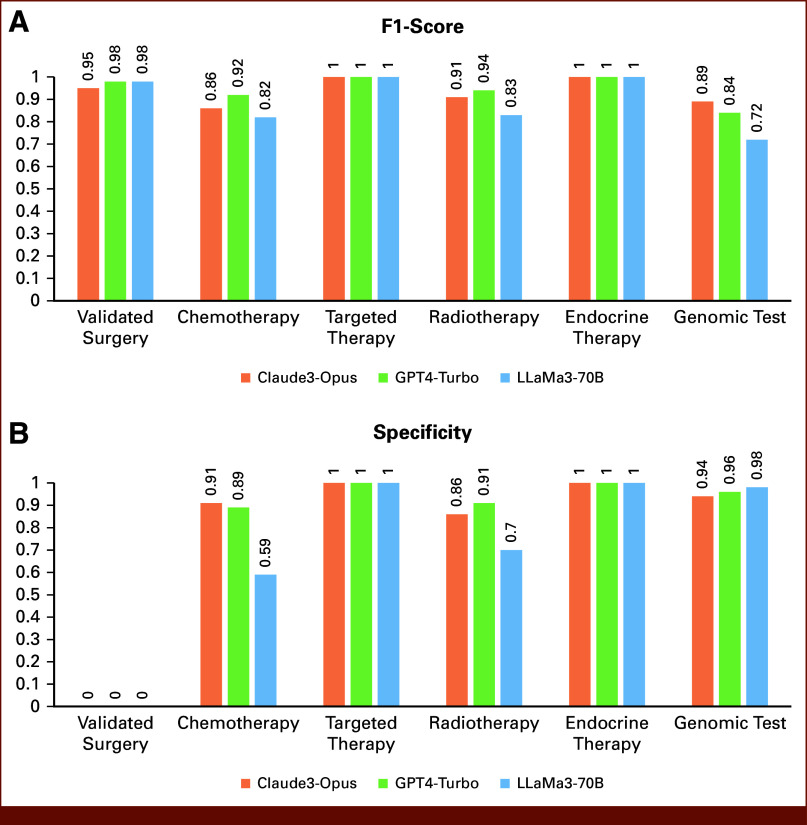
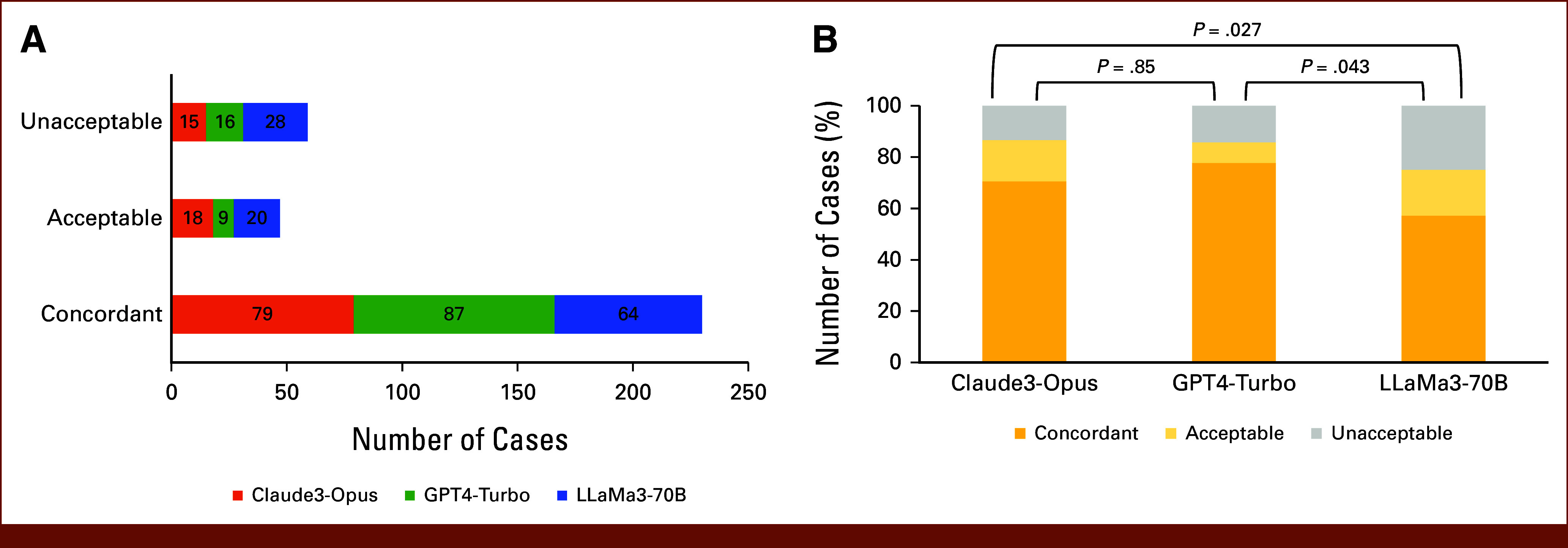
Results: The rates of appropriate suggestions were 86.6% (97/112), 85.7% (96/112), and 75.0% (84/112) for Claude3-Opus, GPT4-Turbo, and LLaMa3-70B, respectively. No significant difference was found between Claude3-Opus and GPT4-Turbo (P = .85), but both tended to perform better than LLaMa3-70B (P = .027 and P = .043, respectively). LLMs showed high accuracy for adjuvant endocrine therapy and targeted therapy indications. However, they tended to overestimate the need for adjuvant radiotherapy and had variable performances in suggesting adjuvant chemotherapy and genomic tests.
Conclusion: LLMs, particularly Claude3-Opus and GPT4-Turbo, demonstrated promising accuracy in suggesting appropriate adjuvant treatments for patients with early BC on the basis of their medical records. Although LLMs showed limitations in validating surgery and indicating genomic tests, their performance in other treatment modalities highlights their potential to automate and augment decision making during MDTs. Further studies with fine-tuned LLMs and a prospective design are needed to demonstrate their utility in clinical practice.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


