Large Language Models for Pediatric Differential Diagnoses in Rural Health Care: Multicenter Retrospective Cohort Study Comparing GPT-3 With Pediatrician Performance.
Masab Mansoor, Andrew F Ibrahim, David Grindem, Asad Baig
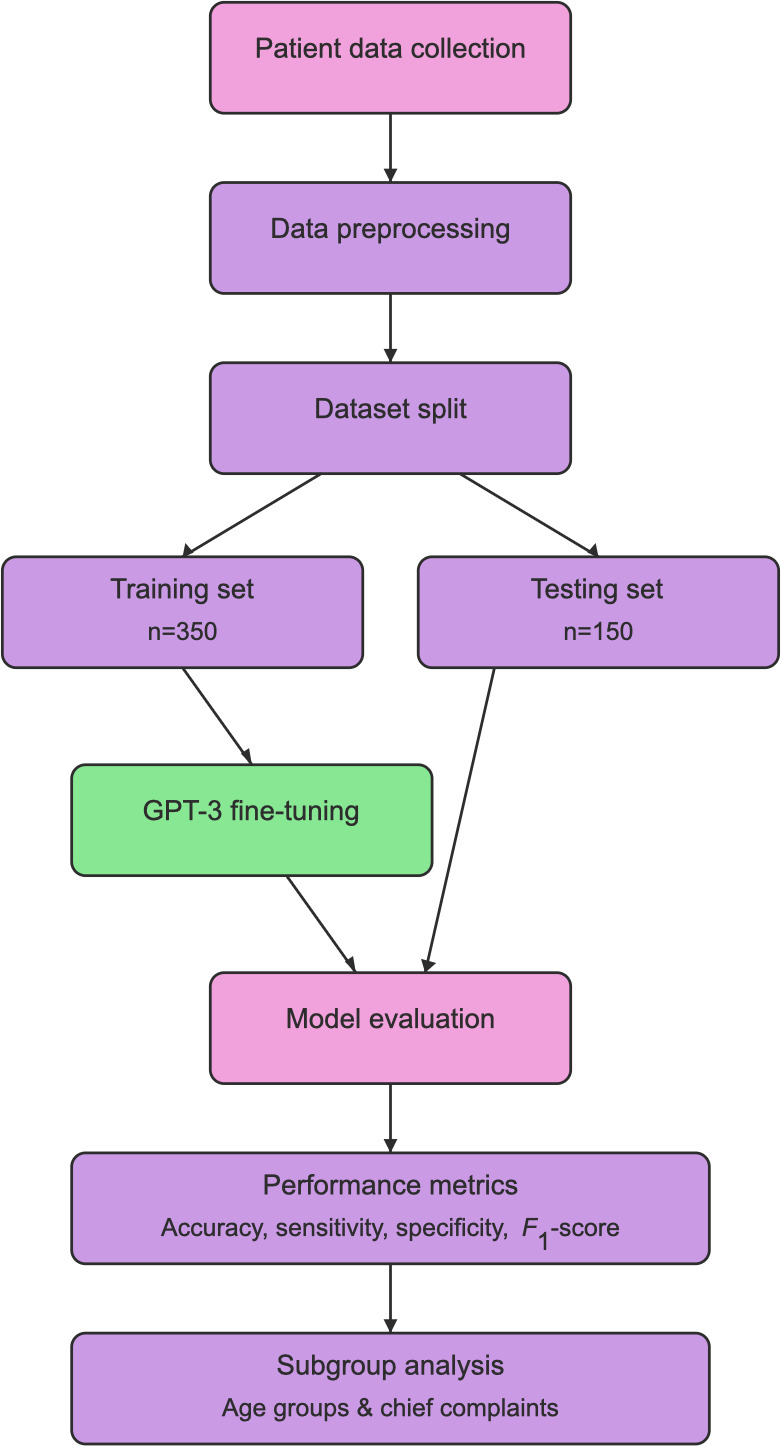
{"title":"Large Language Models for Pediatric Differential Diagnoses in Rural Health Care: Multicenter Retrospective Cohort Study Comparing GPT-3 With Pediatrician Performance.","authors":"Masab Mansoor, Andrew F Ibrahim, David Grindem, Asad Baig","doi":"10.2196/65263","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Rural health care providers face unique challenges such as limited specialist access and high patient volumes, making accurate diagnostic support tools essential. Large language models like GPT-3 have demonstrated potential in clinical decision support but remain understudied in pediatric differential diagnosis.</p><p><strong>Objective: </strong>This study aims to evaluate the diagnostic accuracy and reliability of a fine-tuned GPT-3 model compared to board-certified pediatricians in rural health care settings.</p><p><strong>Methods: </strong>This multicenter retrospective cohort study analyzed 500 pediatric encounters (ages 0-18 years; n=261, 52.2% female) from rural health care organizations in Central Louisiana between January 2020 and December 2021. The GPT-3 model (DaVinci version) was fine-tuned using the OpenAI application programming interface and trained on 350 encounters, with 150 reserved for testing. Five board-certified pediatricians (mean experience: 12, SD 5.8 years) provided reference standard diagnoses. Model performance was assessed using accuracy, sensitivity, specificity, and subgroup analyses.</p><p><strong>Results: </strong>The GPT-3 model achieved an accuracy of 87.3% (131/150 cases), sensitivity of 85% (95% CI 82%-88%), and specificity of 90% (95% CI 87%-93%), comparable to pediatricians' accuracy of 91.3% (137/150 cases; P=.47). Performance was consistent across age groups (0-5 years: 54/62, 87%; 6-12 years: 47/53, 89%; 13-18 years: 30/35, 86%) and common complaints (fever: 36/39, 92%; abdominal pain: 20/23, 87%). For rare diagnoses (n=20), accuracy was slightly lower (16/20, 80%) but comparable to pediatricians (17/20, 85%; P=.62).</p><p><strong>Conclusions: </strong>This study demonstrates that a fine-tuned GPT-3 model can provide diagnostic support comparable to pediatricians, particularly for common presentations, in rural health care. Further validation in diverse populations is necessary before clinical implementation.</p>","PeriodicalId":73558,"journal":{"name":"JMIRx med","volume":"6 ","pages":"e65263"},"PeriodicalIF":0.0000,"publicationDate":"2025-03-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11939124/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIRx med","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/65263","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Rural health care providers face unique challenges such as limited specialist access and high patient volumes, making accurate diagnostic support tools essential. Large language models like GPT-3 have demonstrated potential in clinical decision support but remain understudied in pediatric differential diagnosis.
Objective: This study aims to evaluate the diagnostic accuracy and reliability of a fine-tuned GPT-3 model compared to board-certified pediatricians in rural health care settings.
Methods: This multicenter retrospective cohort study analyzed 500 pediatric encounters (ages 0-18 years; n=261, 52.2% female) from rural health care organizations in Central Louisiana between January 2020 and December 2021. The GPT-3 model (DaVinci version) was fine-tuned using the OpenAI application programming interface and trained on 350 encounters, with 150 reserved for testing. Five board-certified pediatricians (mean experience: 12, SD 5.8 years) provided reference standard diagnoses. Model performance was assessed using accuracy, sensitivity, specificity, and subgroup analyses.
Results: The GPT-3 model achieved an accuracy of 87.3% (131/150 cases), sensitivity of 85% (95% CI 82%-88%), and specificity of 90% (95% CI 87%-93%), comparable to pediatricians' accuracy of 91.3% (137/150 cases; P=.47). Performance was consistent across age groups (0-5 years: 54/62, 87%; 6-12 years: 47/53, 89%; 13-18 years: 30/35, 86%) and common complaints (fever: 36/39, 92%; abdominal pain: 20/23, 87%). For rare diagnoses (n=20), accuracy was slightly lower (16/20, 80%) but comparable to pediatricians (17/20, 85%; P=.62).
Conclusions: This study demonstrates that a fine-tuned GPT-3 model can provide diagnostic support comparable to pediatricians, particularly for common presentations, in rural health care. Further validation in diverse populations is necessary before clinical implementation.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


