Leveraging mixed-effects regression trees for the analysis of high-dimensional longitudinal data to identify the low and high-risk subgroups: simulation study with application to genetic study.
IF 6.1 3区 生物学Q1 MATHEMATICAL & COMPUTATIONAL BIOLOGY
Mina Jahangiri, Anoshirvan Kazemnejad, Keith S Goldfeld, Maryam S Daneshpour, Mehdi Momen, Shayan Mostafaei, Davood Khalili, Mahdi Akbarzadeh
{"title":"Leveraging mixed-effects regression trees for the analysis of high-dimensional longitudinal data to identify the low and high-risk subgroups: simulation study with application to genetic study.","authors":"Mina Jahangiri, Anoshirvan Kazemnejad, Keith S Goldfeld, Maryam S Daneshpour, Mehdi Momen, Shayan Mostafaei, Davood Khalili, Mahdi Akbarzadeh","doi":"10.1186/s13040-025-00437-w","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The linear mixed-effects model (LME) is a conventional parametric method mainly used for analyzing longitudinal and clustered data in genetic studies. Previous studies have shown that this model can be sensitive to parametric assumptions and provides less predictive performance than non-parametric methods such as random effects-expectation maximization (RE-EM) and unbiased RE-EM regression tree algorithms. These longitudinal regression trees utilize classification and regression trees (CART) and conditional inference trees (Ctree) to estimate the fixed-effects components of the mixed-effects model. While CART is a well-known tree algorithm, it suffers from greediness. To mitigate this issue, we used the Evtree algorithm to estimate the fixed-effects part of the LME for handling longitudinal and clustered data in genome association studies.</p><p><strong>Methods: </strong>In this study, we propose a new non-parametric longitudinal-based algorithm called \"Ev-RE-EM\" for modeling a continuous response variable using the Evtree algorithm to estimate the fixed-effects part of the LME. We compared its predictive performance with other tree algorithms, such as RE-EM and unbiased RE-EM, with and without considering the structure for autocorrelation between errors within subjects to analyze the longitudinal data in the genetic study. The autocorrelation structures include a first-order autoregressive process, a compound symmetric structure with a constant correlation, and a general correlation matrix. The real data was obtained from the longitudinal Tehran cardiometabolic genetic study (TCGS). The data modeling used body mass index (BMI) as the phenotype and included predictor variables such as age, sex, and 25,640 single nucleotide polymorphisms (SNPs).</p><p><strong>Results: </strong>The results demonstrated that the predictive performance of Ev-RE-EM and unbiased RE-EM was nearly similar. Additionally, the Ev-RE-EM algorithm generated smaller trees than the unbiased RE-EM algorithm, enhancing tree interpretability.</p><p><strong>Conclusion: </strong>The results showed that the unbiased RE-EM and Ev-RE-EM algorithms outperformed the RE-EM algorithm. Since algorithm performance varies across datasets, researchers should test different algorithms on the dataset of interest and select the best-performing one. Accurately predicting and diagnosing an individual's genetic profile is crucial in medical studies. The model with the highest accuracy should be used to enhance understanding of the genetics of complex traits, improve disease prevention and diagnosis, and aid in treating complex human diseases.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"18 1","pages":"22"},"PeriodicalIF":6.1000,"publicationDate":"2025-03-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11924713/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-025-00437-w","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
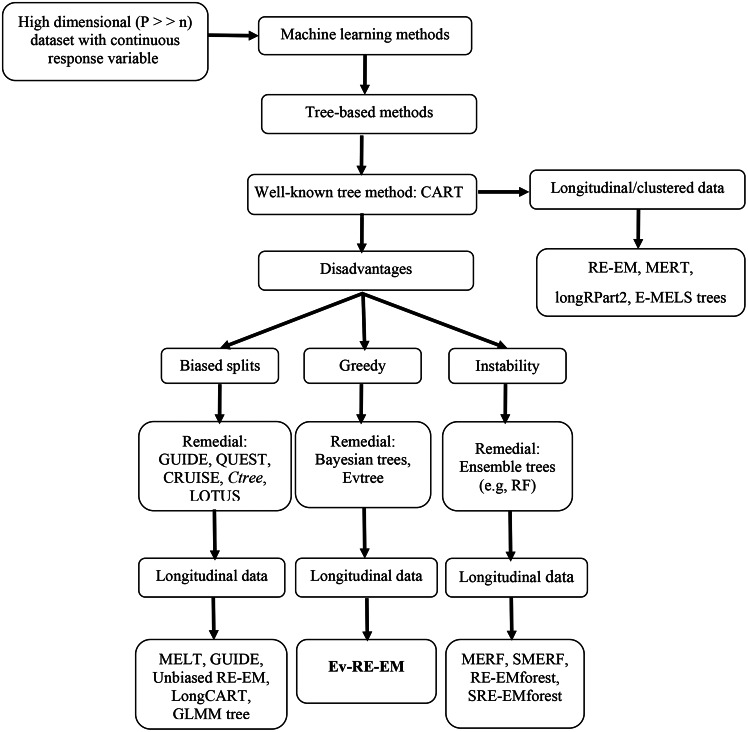
Background: The linear mixed-effects model (LME) is a conventional parametric method mainly used for analyzing longitudinal and clustered data in genetic studies. Previous studies have shown that this model can be sensitive to parametric assumptions and provides less predictive performance than non-parametric methods such as random effects-expectation maximization (RE-EM) and unbiased RE-EM regression tree algorithms. These longitudinal regression trees utilize classification and regression trees (CART) and conditional inference trees (Ctree) to estimate the fixed-effects components of the mixed-effects model. While CART is a well-known tree algorithm, it suffers from greediness. To mitigate this issue, we used the Evtree algorithm to estimate the fixed-effects part of the LME for handling longitudinal and clustered data in genome association studies.
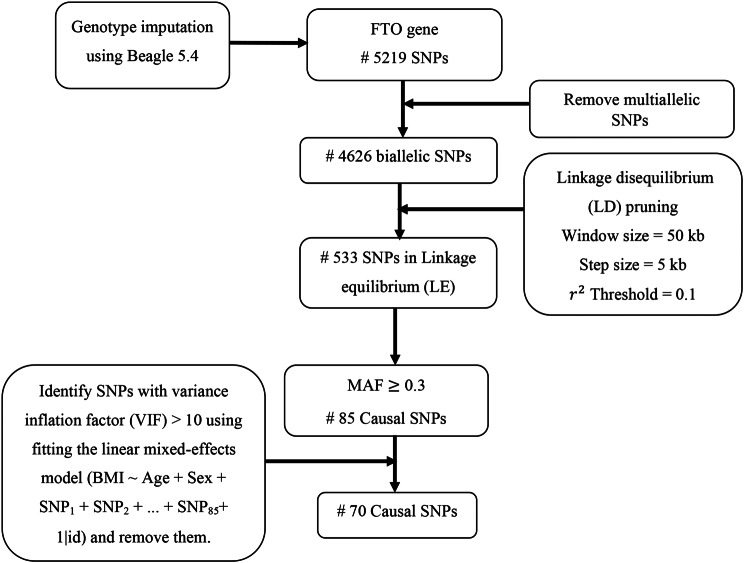
Methods: In this study, we propose a new non-parametric longitudinal-based algorithm called "Ev-RE-EM" for modeling a continuous response variable using the Evtree algorithm to estimate the fixed-effects part of the LME. We compared its predictive performance with other tree algorithms, such as RE-EM and unbiased RE-EM, with and without considering the structure for autocorrelation between errors within subjects to analyze the longitudinal data in the genetic study. The autocorrelation structures include a first-order autoregressive process, a compound symmetric structure with a constant correlation, and a general correlation matrix. The real data was obtained from the longitudinal Tehran cardiometabolic genetic study (TCGS). The data modeling used body mass index (BMI) as the phenotype and included predictor variables such as age, sex, and 25,640 single nucleotide polymorphisms (SNPs).
Results: The results demonstrated that the predictive performance of Ev-RE-EM and unbiased RE-EM was nearly similar. Additionally, the Ev-RE-EM algorithm generated smaller trees than the unbiased RE-EM algorithm, enhancing tree interpretability.
Conclusion: The results showed that the unbiased RE-EM and Ev-RE-EM algorithms outperformed the RE-EM algorithm. Since algorithm performance varies across datasets, researchers should test different algorithms on the dataset of interest and select the best-performing one. Accurately predicting and diagnosing an individual's genetic profile is crucial in medical studies. The model with the highest accuracy should be used to enhance understanding of the genetics of complex traits, improve disease prevention and diagnosis, and aid in treating complex human diseases.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


