Andrea Abate, Elisa Poncato, Maria Antonietta Barbieri, Greg Powell, Andrea Rossi, Simay Peker, Anders Hviid, Andrew Bate, Maurizio Sessa
{"title":"Off-the-Shelf Large Language Models for Causality Assessment of Individual Case Safety Reports: A Proof-of-Concept with COVID-19 Vaccines.","authors":"Andrea Abate, Elisa Poncato, Maria Antonietta Barbieri, Greg Powell, Andrea Rossi, Simay Peker, Anders Hviid, Andrew Bate, Maurizio Sessa","doi":"10.1007/s40264-025-01531-y","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>This study evaluated the feasibility of ChatGPT and Gemini, two off-the-shelf large language models (LLMs), to automate causality assessments, focusing on Adverse Events Following Immunizations (AEFIs) of myocarditis and pericarditis related to COVID-19 vaccines.</p><p><strong>Methods: </strong>We assessed 150 COVID-19-related cases of myocarditis and pericarditis reported to the Vaccine Adverse Event Reporting System (VAERS) in the United States of America (USA). Both LLMs and human experts conducted the World Health Organization (WHO) algorithm for vaccine causality assessments, and inter-rater agreement was measured using percentage agreement. Adherence to the WHO algorithm was evaluated by comparing LLM responses to the expected sequence of the algorithm. Statistical analyses, including descriptive statistics and Random Forest modeling, explored case complexity (e.g., string length measurements) and factors affecting LLM performance and adherence.</p><p><strong>Results: </strong>ChatGPT showed higher adherence to the WHO algorithm (34%) compared to Gemini (7%) and had moderate agreement (71%) with human experts, whereas Gemini had fair agreement (53%). Both LLMs often failed to recognize listed AEFIs, with ChatGPT and Gemini incorrectly identifying 6.7% and 13.3% of AEFIs, respectively. ChatGPT showed inconsistencies in 8.0% of cases and Gemini in 46.7%. For ChatGPT, adherence to the algorithm was associated with lower string complexity in prompt sections. The random forest analysis achieved an accuracy of 55% (95% confidence interval: 35.7-73.5) for predicting adherence to the WHO algorithm for ChatGPT.</p><p><strong>Conclusion: </strong>Notable limitations of ChatGPT and Gemini have been identified in their use for aiding causality assessments in vaccine safety. ChatGPT performed better, with higher adherence and agreement with human experts. In the investigated scenario, both models are better suited as complementary tools to human expertise.</p>","PeriodicalId":11382,"journal":{"name":"Drug Safety","volume":" ","pages":"805-820"},"PeriodicalIF":3.8000,"publicationDate":"2025-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12174240/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Drug Safety","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s40264-025-01531-y","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/3/12 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"PHARMACOLOGY & PHARMACY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: This study evaluated the feasibility of ChatGPT and Gemini, two off-the-shelf large language models (LLMs), to automate causality assessments, focusing on Adverse Events Following Immunizations (AEFIs) of myocarditis and pericarditis related to COVID-19 vaccines.
Methods: We assessed 150 COVID-19-related cases of myocarditis and pericarditis reported to the Vaccine Adverse Event Reporting System (VAERS) in the United States of America (USA). Both LLMs and human experts conducted the World Health Organization (WHO) algorithm for vaccine causality assessments, and inter-rater agreement was measured using percentage agreement. Adherence to the WHO algorithm was evaluated by comparing LLM responses to the expected sequence of the algorithm. Statistical analyses, including descriptive statistics and Random Forest modeling, explored case complexity (e.g., string length measurements) and factors affecting LLM performance and adherence.
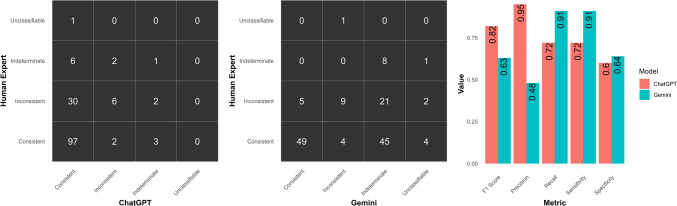
Results: ChatGPT showed higher adherence to the WHO algorithm (34%) compared to Gemini (7%) and had moderate agreement (71%) with human experts, whereas Gemini had fair agreement (53%). Both LLMs often failed to recognize listed AEFIs, with ChatGPT and Gemini incorrectly identifying 6.7% and 13.3% of AEFIs, respectively. ChatGPT showed inconsistencies in 8.0% of cases and Gemini in 46.7%. For ChatGPT, adherence to the algorithm was associated with lower string complexity in prompt sections. The random forest analysis achieved an accuracy of 55% (95% confidence interval: 35.7-73.5) for predicting adherence to the WHO algorithm for ChatGPT.
Conclusion: Notable limitations of ChatGPT and Gemini have been identified in their use for aiding causality assessments in vaccine safety. ChatGPT performed better, with higher adherence and agreement with human experts. In the investigated scenario, both models are better suited as complementary tools to human expertise.
期刊介绍:
Drug Safety is the official journal of the International Society of Pharmacovigilance. The journal includes:
Overviews of contentious or emerging issues.
Comprehensive narrative reviews that provide an authoritative source of information on epidemiology, clinical features, prevention and management of adverse effects of individual drugs and drug classes.
In-depth benefit-risk assessment of adverse effect and efficacy data for a drug in a defined therapeutic area.
Systematic reviews (with or without meta-analyses) that collate empirical evidence to answer a specific research question, using explicit, systematic methods as outlined by the PRISMA statement.
Original research articles reporting the results of well-designed studies in disciplines such as pharmacoepidemiology, pharmacovigilance, pharmacology and toxicology, and pharmacogenomics.
Editorials and commentaries on topical issues.
Additional digital features (including animated abstracts, video abstracts, slide decks, audio slides, instructional videos, infographics, podcasts and animations) can be published with articles; these are designed to increase the visibility, readership and educational value of the journal’s content. In addition, articles published in Drug Safety Drugs may be accompanied by plain language summaries to assist readers who have some knowledge of, but not in-depth expertise in, the area to understand important medical advances.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


