Katherine E Brown, Chao Yan, Zhuohang Li, Xinmeng Zhang, Benjamin X Collins, You Chen, Ellen Wright Clayton, Murat Kantarcioglu, Yevgeniy Vorobeychik, Bradley A Malin
{"title":"Large language models are less effective at clinical prediction tasks than locally trained machine learning models.","authors":"Katherine E Brown, Chao Yan, Zhuohang Li, Xinmeng Zhang, Benjamin X Collins, You Chen, Ellen Wright Clayton, Murat Kantarcioglu, Yevgeniy Vorobeychik, Bradley A Malin","doi":"10.1093/jamia/ocaf038","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>To determine the extent to which current large language models (LLMs) can serve as substitutes for traditional machine learning (ML) as clinical predictors using data from electronic health records (EHRs), we investigated various factors that can impact their adoption, including overall performance, calibration, fairness, and resilience to privacy protections that reduce data fidelity.</p><p><strong>Materials and methods: </strong>We evaluated GPT-3.5, GPT-4, and traditional ML (as gradient-boosting trees) on clinical prediction tasks in EHR data from Vanderbilt University Medical Center (VUMC) and MIMIC IV. We measured predictive performance with area under the receiver operating characteristic (AUROC) and model calibration using Brier Score. To evaluate the impact of data privacy protections, we assessed AUROC when demographic variables are generalized. We evaluated algorithmic fairness using equalized odds and statistical parity across race, sex, and age of patients. We also considered the impact of using in-context learning by incorporating labeled examples within the prompt.</p><p><strong>Results: </strong>Traditional ML [AUROC: 0.847, 0.894 (VUMC, MIMIC)] substantially outperformed GPT-3.5 (AUROC: 0.537, 0.517) and GPT-4 (AUROC: 0.629, 0.602) (with and without in-context learning) in predictive performance and output probability calibration [Brier Score (ML vs GPT-3.5 vs GPT-4): 0.134 vs 0.384 vs 0.251, 0.042 vs 0.06 vs 0.219)].</p><p><strong>Discussion: </strong>Traditional ML is more robust than GPT-3.5 and GPT-4 in generalizing demographic information to protect privacy. GPT-4 is the fairest model according to our selected metrics but at the cost of poor model performance.</p><p><strong>Conclusion: </strong>These findings suggest that non-fine-tuned LLMs are less effective and robust than locally trained ML for clinical prediction tasks, but they are improving across releases.</p>","PeriodicalId":50016,"journal":{"name":"Journal of the American Medical Informatics Association","volume":" ","pages":"811-822"},"PeriodicalIF":4.6000,"publicationDate":"2025-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12012369/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of the American Medical Informatics Association","FirstCategoryId":"91","ListUrlMain":"https://doi.org/10.1093/jamia/ocaf038","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: To determine the extent to which current large language models (LLMs) can serve as substitutes for traditional machine learning (ML) as clinical predictors using data from electronic health records (EHRs), we investigated various factors that can impact their adoption, including overall performance, calibration, fairness, and resilience to privacy protections that reduce data fidelity.
Materials and methods: We evaluated GPT-3.5, GPT-4, and traditional ML (as gradient-boosting trees) on clinical prediction tasks in EHR data from Vanderbilt University Medical Center (VUMC) and MIMIC IV. We measured predictive performance with area under the receiver operating characteristic (AUROC) and model calibration using Brier Score. To evaluate the impact of data privacy protections, we assessed AUROC when demographic variables are generalized. We evaluated algorithmic fairness using equalized odds and statistical parity across race, sex, and age of patients. We also considered the impact of using in-context learning by incorporating labeled examples within the prompt.
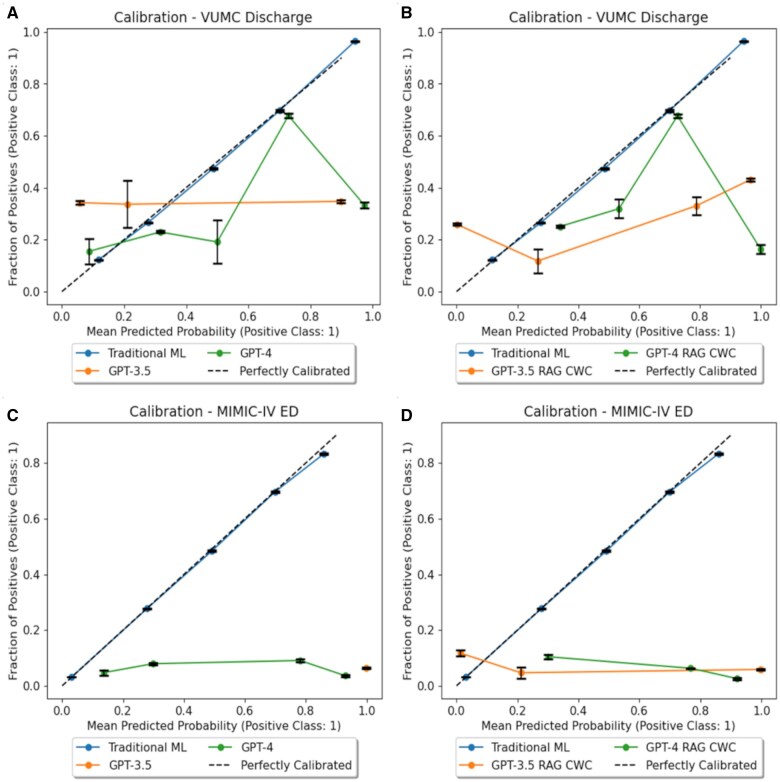
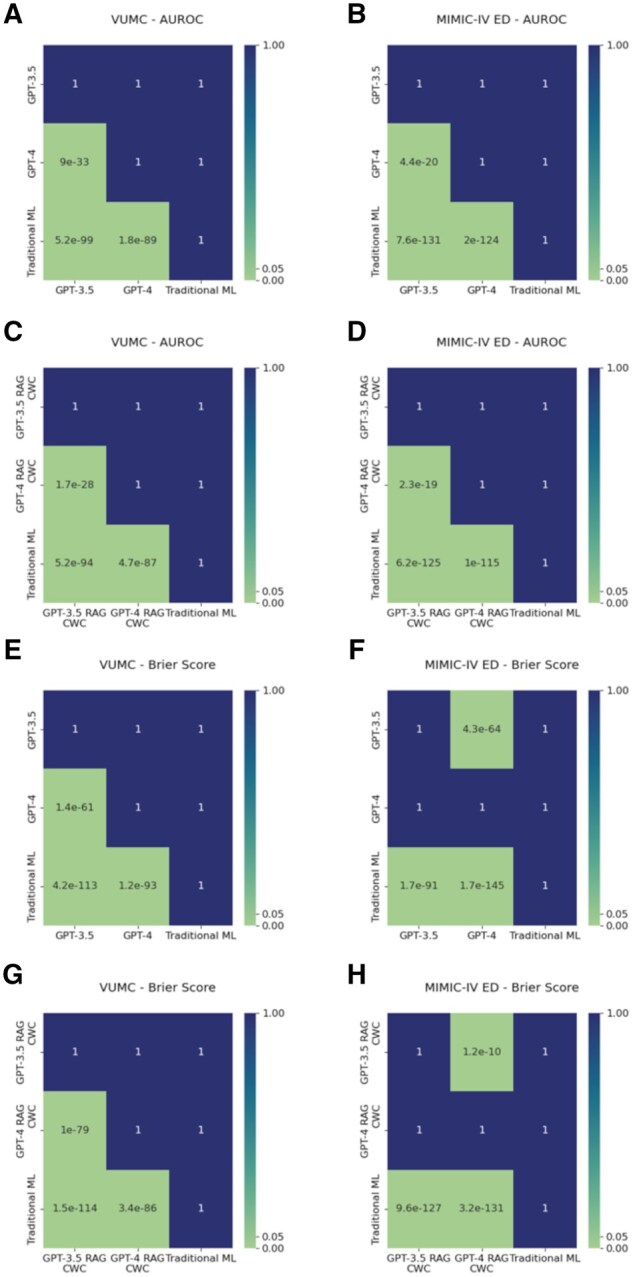
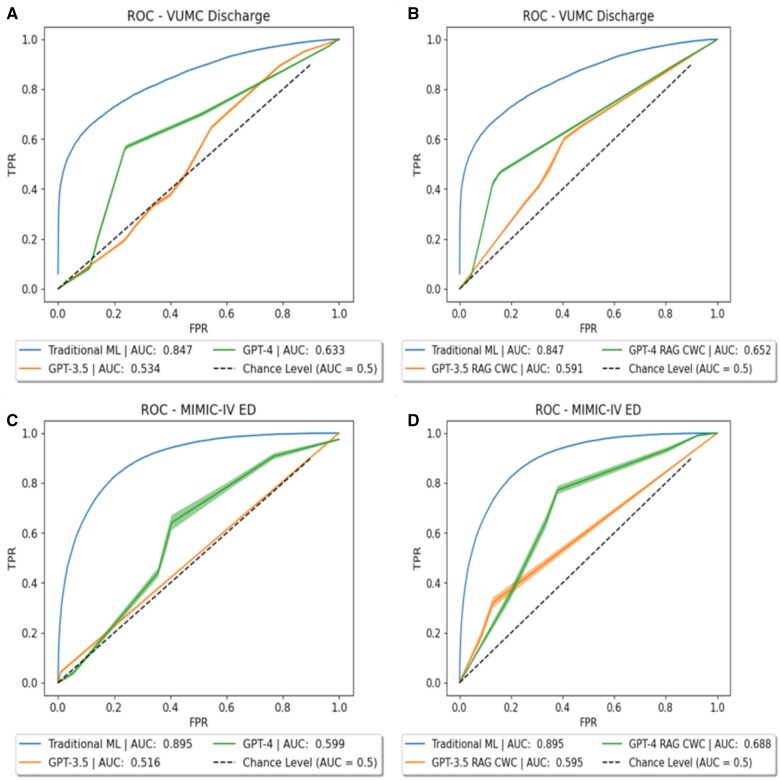
Results: Traditional ML [AUROC: 0.847, 0.894 (VUMC, MIMIC)] substantially outperformed GPT-3.5 (AUROC: 0.537, 0.517) and GPT-4 (AUROC: 0.629, 0.602) (with and without in-context learning) in predictive performance and output probability calibration [Brier Score (ML vs GPT-3.5 vs GPT-4): 0.134 vs 0.384 vs 0.251, 0.042 vs 0.06 vs 0.219)].
Discussion: Traditional ML is more robust than GPT-3.5 and GPT-4 in generalizing demographic information to protect privacy. GPT-4 is the fairest model according to our selected metrics but at the cost of poor model performance.
Conclusion: These findings suggest that non-fine-tuned LLMs are less effective and robust than locally trained ML for clinical prediction tasks, but they are improving across releases.
目的:为了确定当前大型语言模型(llm)在多大程度上可以作为传统机器学习(ML)的替代品,利用电子健康记录(EHRs)的数据作为临床预测指标,我们调查了影响其采用的各种因素,包括整体性能、校准、公平性和对降低数据保真度的隐私保护的弹性。材料和方法:我们评估了GPT-3.5、GPT-4和传统ML(作为梯度增强树)在范德比尔特大学医学中心(VUMC)和MIMIC IV的EHR数据中的临床预测任务。我们使用受试者工作特征下面积(AUROC)和Brier评分来测量预测性能。为了评估数据隐私保护的影响,我们在人口统计变量普遍化时评估了AUROC。我们使用种族、性别和年龄患者的均等几率和统计均等来评估算法的公平性。我们还考虑了通过在提示中加入标记示例来使用上下文学习的影响。结果:传统ML [AUROC: 0.847, 0.894 (VUMC, MIMIC)]在预测性能和输出概率校准方面的表现明显优于GPT-3.5 (AUROC: 0.537, 0.517)和GPT-4 (AUROC: 0.629, 0.602)(有和没有上下文学习)[Brier评分(ML vs GPT-3.5 vs GPT-4): 0.134 vs 0.384 vs 0.251, 0.042 vs 0.06 vs 0.219]。讨论:在概括人口统计信息以保护隐私方面,传统ML比GPT-3.5和GPT-4更健壮。根据我们选择的指标,GPT-4是最公平的模型,但代价是模型性能较差。结论:这些发现表明,在临床预测任务中,非微调llm的有效性和鲁棒性不如本地训练的ML,但它们在不同版本中都有所改善。
期刊介绍:
JAMIA is AMIA''s premier peer-reviewed journal for biomedical and health informatics. Covering the full spectrum of activities in the field, JAMIA includes informatics articles in the areas of clinical care, clinical research, translational science, implementation science, imaging, education, consumer health, public health, and policy. JAMIA''s articles describe innovative informatics research and systems that help to advance biomedical science and to promote health. Case reports, perspectives and reviews also help readers stay connected with the most important informatics developments in implementation, policy and education.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


