Mazhar Ortaç, Rıfat Burak Ergül, Hüseyin Burak Yazılı, Muhammet Firat Özervarlı, Şenol Tonyalı, Omer Sarılar, Faruk Özgör
{"title":"ChatGPT's competence in responding to urological emergencies.","authors":"Mazhar Ortaç, Rıfat Burak Ergül, Hüseyin Burak Yazılı, Muhammet Firat Özervarlı, Şenol Tonyalı, Omer Sarılar, Faruk Özgör","doi":"10.14744/tjtes.2024.03377","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>In recent years, artificial intelligence (AI) applications have been increasingly used as sources of medical information, alongside their applications in many other fields. This study is the first to evaluate ChatGPT's performance in addressing urological emergencies (UE).</p><p><strong>Methods: </strong>The study included frequently asked questions (FAQs) by the public regarding UE, as well as UE-related questions formulated based on the European Association of Urology (EAU) guidelines. The FAQs were selected from questions posed by patients to doctors and hospital accounts on social media platforms (Facebook, Instagram, and X) and on websites. All questions were presented to ChatGPT 4 (premium version) in English, and the responses were recorded. Two urologists assessed the quality of the responses using a Global Quality Score (GQS) on a scale of 1 to 5.</p><p><strong>Results: </strong>Of the 73 total FAQs, 53 (72.6%) received a GQS score of 5, while only two (2.7%) received a GQS score of 1. The questions with a GQS score of 1 pertained to priapism and urosepsis. The topic with the highest proportion of responses receiving a GQS score of 5 was urosepsis (82.3%), whereas the lowest scores were observed in questions related to renal trauma (66.7%) and postrenal acute kidney injury (66.7%). A total of 42 questions were formulated based on the EAU guidelines, of which 23 (54.8%) received a GQS score of 5 from the physicians. The mean GQS score for FAQs was 4.38+-1.14, which was significantly higher (p=0.009) than the mean GQS score for EAU guideline-based questions (3.88+-1.47).</p><p><strong>Conclusion: </strong>This study demonstrated for the first time that nearly three out of four FAQs were answered accurately and satisfactorily by ChatGPT. However, the accuracy and proficiency of ChatGPT's responses significantly decreased when addressing guideline-based questions on UE.</p>","PeriodicalId":94263,"journal":{"name":"Ulusal travma ve acil cerrahi dergisi = Turkish journal of trauma & emergency surgery : TJTES","volume":"31 3","pages":"291-295"},"PeriodicalIF":1.0000,"publicationDate":"2025-03-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11894229/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Ulusal travma ve acil cerrahi dergisi = Turkish journal of trauma & emergency surgery : TJTES","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.14744/tjtes.2024.03377","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: In recent years, artificial intelligence (AI) applications have been increasingly used as sources of medical information, alongside their applications in many other fields. This study is the first to evaluate ChatGPT's performance in addressing urological emergencies (UE).
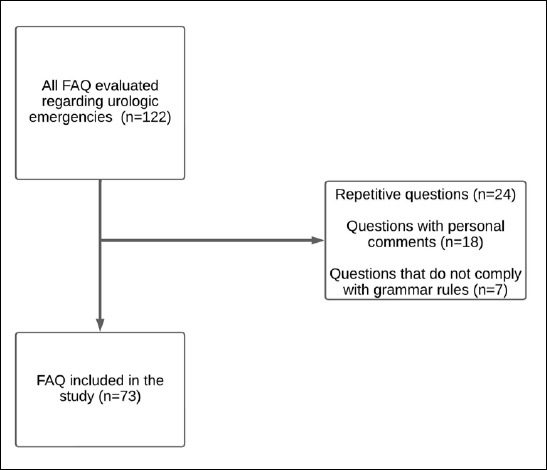
Methods: The study included frequently asked questions (FAQs) by the public regarding UE, as well as UE-related questions formulated based on the European Association of Urology (EAU) guidelines. The FAQs were selected from questions posed by patients to doctors and hospital accounts on social media platforms (Facebook, Instagram, and X) and on websites. All questions were presented to ChatGPT 4 (premium version) in English, and the responses were recorded. Two urologists assessed the quality of the responses using a Global Quality Score (GQS) on a scale of 1 to 5.
Results: Of the 73 total FAQs, 53 (72.6%) received a GQS score of 5, while only two (2.7%) received a GQS score of 1. The questions with a GQS score of 1 pertained to priapism and urosepsis. The topic with the highest proportion of responses receiving a GQS score of 5 was urosepsis (82.3%), whereas the lowest scores were observed in questions related to renal trauma (66.7%) and postrenal acute kidney injury (66.7%). A total of 42 questions were formulated based on the EAU guidelines, of which 23 (54.8%) received a GQS score of 5 from the physicians. The mean GQS score for FAQs was 4.38+-1.14, which was significantly higher (p=0.009) than the mean GQS score for EAU guideline-based questions (3.88+-1.47).
Conclusion: This study demonstrated for the first time that nearly three out of four FAQs were answered accurately and satisfactorily by ChatGPT. However, the accuracy and proficiency of ChatGPT's responses significantly decreased when addressing guideline-based questions on UE.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


