Thierry Hanser, Ernst Ahlberg, Alexander Amberg, Lennart T. Anger, Chris Barber, Richard J. Brennan, Alessandro Brigo, Annie Delaunois, Susanne Glowienke, Nigel Greene, Laura Johnston, Daniel Kuhn, Lara Kuhnke, Jean-François Marchaland, Wolfgang Muster, Jeffrey Plante, Friedrich Rippmann, Yogesh Sabnis, Friedemann Schmidt, Ruud van Deursen, Stéphane Werner, Angela White, Joerg Wichard, Tomoya Yukawa
{"title":"Data-driven federated learning in drug discovery with knowledge distillation","authors":"Thierry Hanser, Ernst Ahlberg, Alexander Amberg, Lennart T. Anger, Chris Barber, Richard J. Brennan, Alessandro Brigo, Annie Delaunois, Susanne Glowienke, Nigel Greene, Laura Johnston, Daniel Kuhn, Lara Kuhnke, Jean-François Marchaland, Wolfgang Muster, Jeffrey Plante, Friedrich Rippmann, Yogesh Sabnis, Friedemann Schmidt, Ruud van Deursen, Stéphane Werner, Angela White, Joerg Wichard, Tomoya Yukawa","doi":"10.1038/s42256-025-00991-2","DOIUrl":null,"url":null,"abstract":"<p>A main challenge for artificial intelligence in scientific research is ensuring access to sufficient, high-quality data for the development of impactful models. Despite the abundance of public data, the most valuable knowledge often remains embedded within confidential corporate data silos. Although industries are increasingly open to sharing non-competitive insights, such collaboration is often constrained by the confidentiality of the underlying data. Federated learning makes it possible to share knowledge without compromising data privacy, but it has notable limitations. Here, we introduce FLuID (federated learning using information distillation), a data-centric application of federated distillation tailored to drug discovery aiming to preserve data privacy. We validate FLuID in two experiments, first involving public data simulating a virtual consortium and second in a real-world research collaboration between eight pharmaceutical companies. Although the alignment of the models with the partner specific domain remains challenging, the data-driven nature of FLuID offers several avenues to mitigate domain shift. FLuID fosters knowledge sharing among pharmaceutical organizations, paving the way for a new generation of models with enhanced performance and an expanded applicability domain in biological activity predictions.</p>","PeriodicalId":48533,"journal":{"name":"Nature Machine Intelligence","volume":"211 1","pages":""},"PeriodicalIF":18.8000,"publicationDate":"2025-03-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Machine Intelligence","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1038/s42256-025-00991-2","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
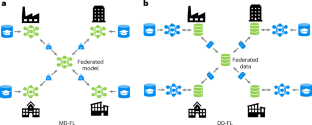
A main challenge for artificial intelligence in scientific research is ensuring access to sufficient, high-quality data for the development of impactful models. Despite the abundance of public data, the most valuable knowledge often remains embedded within confidential corporate data silos. Although industries are increasingly open to sharing non-competitive insights, such collaboration is often constrained by the confidentiality of the underlying data. Federated learning makes it possible to share knowledge without compromising data privacy, but it has notable limitations. Here, we introduce FLuID (federated learning using information distillation), a data-centric application of federated distillation tailored to drug discovery aiming to preserve data privacy. We validate FLuID in two experiments, first involving public data simulating a virtual consortium and second in a real-world research collaboration between eight pharmaceutical companies. Although the alignment of the models with the partner specific domain remains challenging, the data-driven nature of FLuID offers several avenues to mitigate domain shift. FLuID fosters knowledge sharing among pharmaceutical organizations, paving the way for a new generation of models with enhanced performance and an expanded applicability domain in biological activity predictions.
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


