Magdalena T Weber, Richard Noll, Alexandra Marchl, Carlo Facchinello, Achim Grünewaldt, Christian Hügel, Khader Musleh, Thomas O F Wagner, Holger Storf, Jannik Schaaf
{"title":"MedBot vs RealDoc: efficacy of large language modeling in physician-patient communication for rare diseases.","authors":"Magdalena T Weber, Richard Noll, Alexandra Marchl, Carlo Facchinello, Achim Grünewaldt, Christian Hügel, Khader Musleh, Thomas O F Wagner, Holger Storf, Jannik Schaaf","doi":"10.1093/jamia/ocaf034","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>This study assesses the abilities of 2 large language models (LLMs), GPT-4 and BioMistral 7B, in responding to patient queries, particularly concerning rare diseases, and compares their performance with that of physicians.</p><p><strong>Materials and methods: </strong>A total of 103 patient queries and corresponding physician answers were extracted from EXABO, a question-answering forum dedicated to rare respiratory diseases. The responses provided by physicians and generated by LLMs were ranked on a Likert scale by a panel of 4 experts based on 4 key quality criteria for health communication: correctness, comprehensibility, relevance, and empathy.</p><p><strong>Results: </strong>The performance of generative pretrained transformer 4 (GPT-4) was significantly better than the performance of the physicians and BioMistral 7B. While the overall ranking considers GPT-4's responses to be mostly correct, comprehensive, relevant, and emphatic, the responses provided by BioMistral 7B were only partially correct and empathetic. The responses given by physicians rank in between. The experts concur that an LLM could lighten the load for physicians, rigorous validation is considered essential to guarantee dependability and efficacy.</p><p><strong>Discussion: </strong>Open-source models such as BioMistral 7B offer the advantage of privacy by running locally in health-care settings. GPT-4, on the other hand, demonstrates proficiency in communication and knowledge depth. However, challenges persist, including the management of response variability, the balancing of comprehensibility with medical accuracy, and the assurance of consistent performance across different languages.</p><p><strong>Conclusion: </strong>The performance of GPT-4 underscores the potential of LLMs in facilitating physician-patient communication. However, it is imperative that these systems are handled with care, as erroneous responses have the potential to cause harm without the requisite validation procedures.</p>","PeriodicalId":50016,"journal":{"name":"Journal of the American Medical Informatics Association","volume":" ","pages":"775-783"},"PeriodicalIF":4.6000,"publicationDate":"2025-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12012358/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of the American Medical Informatics Association","FirstCategoryId":"91","ListUrlMain":"https://doi.org/10.1093/jamia/ocaf034","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: This study assesses the abilities of 2 large language models (LLMs), GPT-4 and BioMistral 7B, in responding to patient queries, particularly concerning rare diseases, and compares their performance with that of physicians.
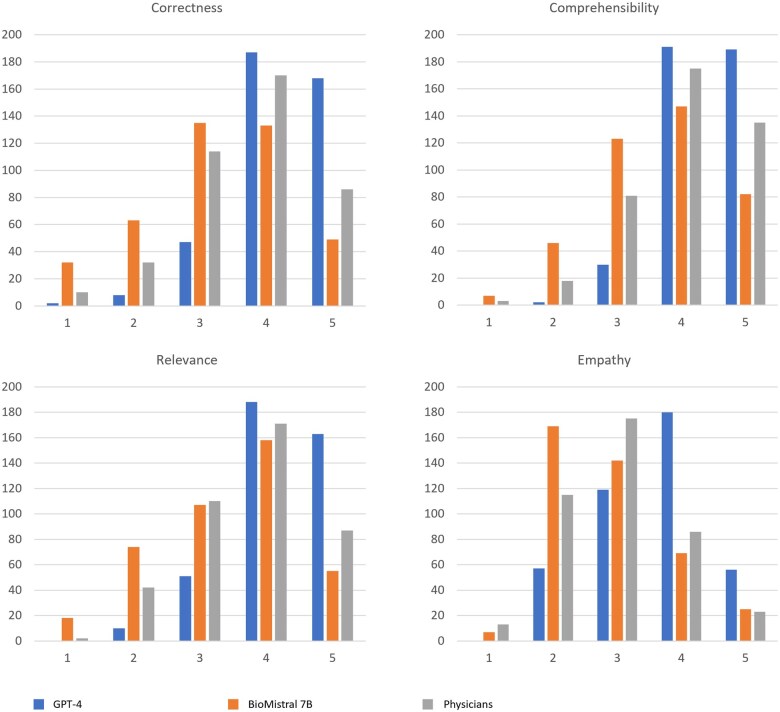
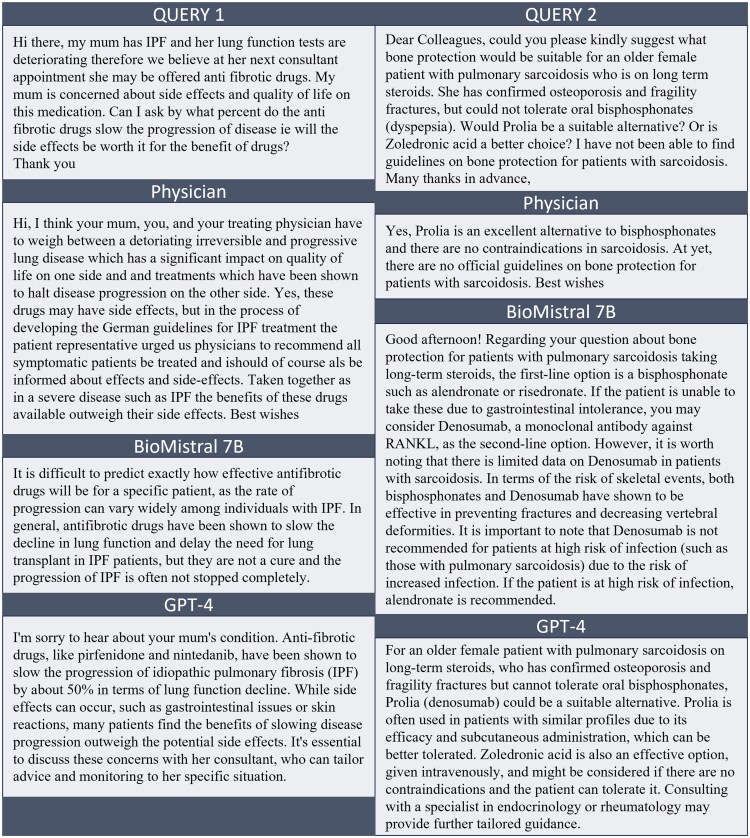
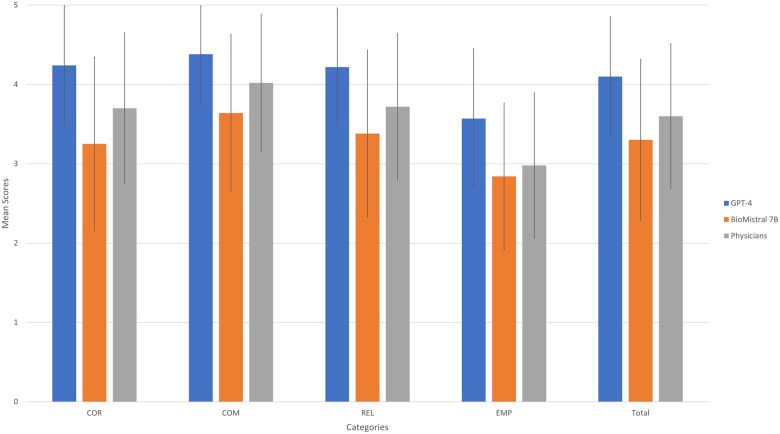
Materials and methods: A total of 103 patient queries and corresponding physician answers were extracted from EXABO, a question-answering forum dedicated to rare respiratory diseases. The responses provided by physicians and generated by LLMs were ranked on a Likert scale by a panel of 4 experts based on 4 key quality criteria for health communication: correctness, comprehensibility, relevance, and empathy.
Results: The performance of generative pretrained transformer 4 (GPT-4) was significantly better than the performance of the physicians and BioMistral 7B. While the overall ranking considers GPT-4's responses to be mostly correct, comprehensive, relevant, and emphatic, the responses provided by BioMistral 7B were only partially correct and empathetic. The responses given by physicians rank in between. The experts concur that an LLM could lighten the load for physicians, rigorous validation is considered essential to guarantee dependability and efficacy.
Discussion: Open-source models such as BioMistral 7B offer the advantage of privacy by running locally in health-care settings. GPT-4, on the other hand, demonstrates proficiency in communication and knowledge depth. However, challenges persist, including the management of response variability, the balancing of comprehensibility with medical accuracy, and the assurance of consistent performance across different languages.
Conclusion: The performance of GPT-4 underscores the potential of LLMs in facilitating physician-patient communication. However, it is imperative that these systems are handled with care, as erroneous responses have the potential to cause harm without the requisite validation procedures.
期刊介绍:
JAMIA is AMIA''s premier peer-reviewed journal for biomedical and health informatics. Covering the full spectrum of activities in the field, JAMIA includes informatics articles in the areas of clinical care, clinical research, translational science, implementation science, imaging, education, consumer health, public health, and policy. JAMIA''s articles describe innovative informatics research and systems that help to advance biomedical science and to promote health. Case reports, perspectives and reviews also help readers stay connected with the most important informatics developments in implementation, policy and education.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


