{"title":"Leveraging deep learning to detect stance in Spanish tweets on COVID-19 vaccination.","authors":"Guillermo Blanco, Rubén Yáñez Martínez, Anália Lourenço","doi":"10.1093/jamiaopen/ooaf007","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>The automatic detection of stance on social media is an important task for public health applications, especially in the context of health crises. Unfortunately, existing models are typically trained on English corpora. Considering the benefits of extending research to other widely spoken languages, the goal of this study is to develop stance detection models for social media posts in Spanish.</p><p><strong>Materials and methods: </strong>A corpus of 6170 tweets about COVID-19 vaccination, posted between March 1, 2020 and January 4, 2022, was manually annotated by native speakers. Traditional predictive models were compared with deep learning models to ascertain a baseline performance for the detection of stance in Spanish tweets. The evaluation focused on the ability of multilingual and language-specific embeddings to contextualize the topic of those short texts adequately.</p><p><strong>Results: </strong>The BERT-Multi+BiLSTM combination yielded the best results (macroaveraged F1 and Matthews correlation coefficient scores of 0.86 and 0.79, respectively; interpolated area under the receiver operating curve [AUC] of 0.95 for tweets against vaccination and 0.85 in favor of vaccination and a score of 0.97 for tweets containing no stance information), closely followed by the BETO+BiLSTM and RoBERTa BNE-LSTM Spanish models and the term frequency-inverse document frequency+SVM model (average AUC decrease of 0.01). The main differentiating factor among these models was the ability to predict tweets against vaccination.</p><p><strong>Discussion: </strong>The BERT Multi+BILSTM model outperformed the other models in terms of per class prediction capacity. The main assumption is that language-specific embeddings do not outperform multilingual embeddings or TF-IDF features because of the context of the topic. The inherent context of BERT or RoBERTa embeddings is general. So, these embeddings are not familiar with the slang commonly used on Twitter and, more specifically, during the pandemic.</p><p><strong>Conclusion: </strong>The best performing model detects tweet stance with performance high enough to ensure its usefulness for public health applications, namely awareness campaigns, misinformation detection and other early intervention and prevention actions seeking to improve an individual's well-being based on autoreported experiences and opinions. The dataset and code of the study are available on GitHub.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"8 1","pages":"ooaf007"},"PeriodicalIF":3.4000,"publicationDate":"2025-01-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11854073/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooaf007","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/2/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: The automatic detection of stance on social media is an important task for public health applications, especially in the context of health crises. Unfortunately, existing models are typically trained on English corpora. Considering the benefits of extending research to other widely spoken languages, the goal of this study is to develop stance detection models for social media posts in Spanish.
Materials and methods: A corpus of 6170 tweets about COVID-19 vaccination, posted between March 1, 2020 and January 4, 2022, was manually annotated by native speakers. Traditional predictive models were compared with deep learning models to ascertain a baseline performance for the detection of stance in Spanish tweets. The evaluation focused on the ability of multilingual and language-specific embeddings to contextualize the topic of those short texts adequately.
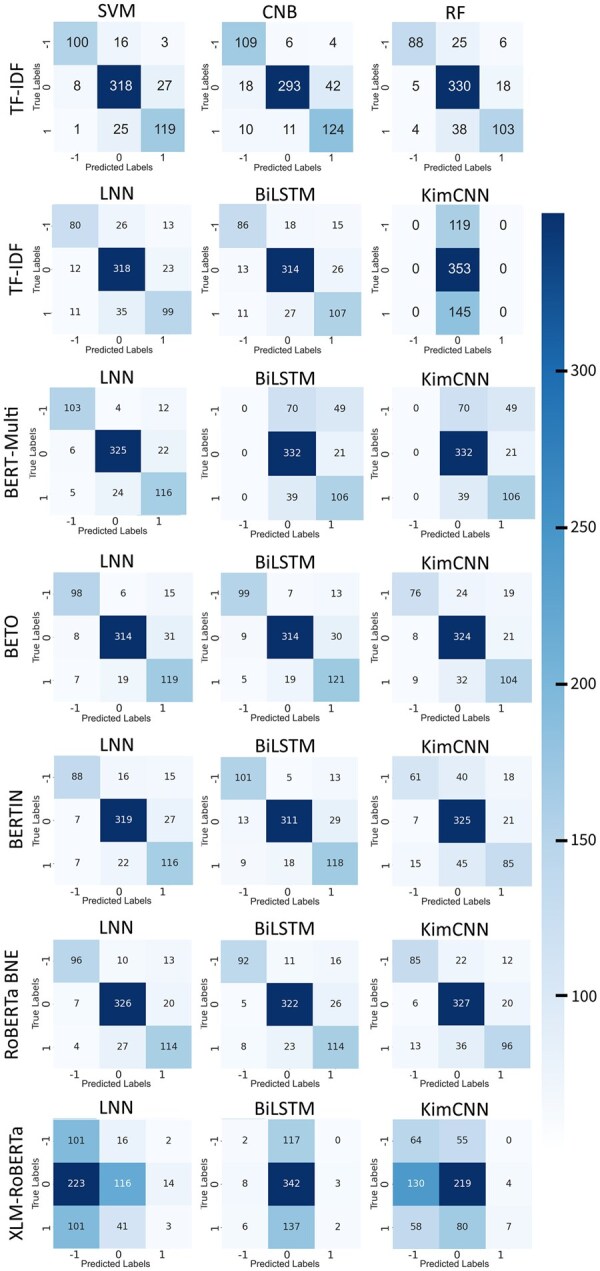
Results: The BERT-Multi+BiLSTM combination yielded the best results (macroaveraged F1 and Matthews correlation coefficient scores of 0.86 and 0.79, respectively; interpolated area under the receiver operating curve [AUC] of 0.95 for tweets against vaccination and 0.85 in favor of vaccination and a score of 0.97 for tweets containing no stance information), closely followed by the BETO+BiLSTM and RoBERTa BNE-LSTM Spanish models and the term frequency-inverse document frequency+SVM model (average AUC decrease of 0.01). The main differentiating factor among these models was the ability to predict tweets against vaccination.
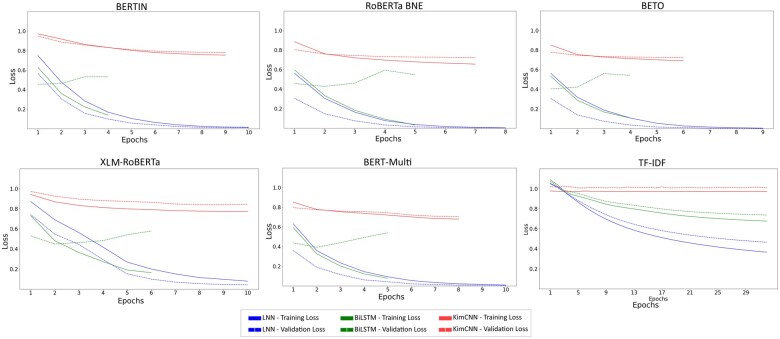
Discussion: The BERT Multi+BILSTM model outperformed the other models in terms of per class prediction capacity. The main assumption is that language-specific embeddings do not outperform multilingual embeddings or TF-IDF features because of the context of the topic. The inherent context of BERT or RoBERTa embeddings is general. So, these embeddings are not familiar with the slang commonly used on Twitter and, more specifically, during the pandemic.
Conclusion: The best performing model detects tweet stance with performance high enough to ensure its usefulness for public health applications, namely awareness campaigns, misinformation detection and other early intervention and prevention actions seeking to improve an individual's well-being based on autoreported experiences and opinions. The dataset and code of the study are available on GitHub.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


