Lailil Muflikhah, Tirana Noor Fatyanosa, Nashi Widodo, Rizal Setya Perdana, Solimun, Hana Ratnawati
{"title":"Feature Selection for Hypertension Risk Prediction Using XGBoost on Single Nucleotide Polymorphism Data.","authors":"Lailil Muflikhah, Tirana Noor Fatyanosa, Nashi Widodo, Rizal Setya Perdana, Solimun, Hana Ratnawati","doi":"10.4258/hir.2025.31.1.16","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>Hypertension, commonly known as high blood pressure, is a prevalent and serious condition affecting a significant portion of the adult population globally. It is a chronic medical issue that, if left unaddressed, can lead to severe health complications, including kidney problems, heart disease, and stroke. This study aims to develop a feature selection model using the XGBoost algorithm to identify specific single nucleotide polymorphisms (SNPs) as biomarkers for detecting hypertension risk.</p><p><strong>Methods: </strong>We propose using the high dimensionality of genetic variations (i.e., SNPs) to build a classifier model for prediction. In this study, SNPs were used as markers for hypertension in patients. We utilized the OpenSNP dataset, which includes 19,697 SNPs from 2,052 samples. Extreme gradient boosting (XGBoost) is an ensemble machine learning method employed here for feature selection, which incrementally adjusts weights in a series of steps.</p><p><strong>Results: </strong>The experimental results identified 292 SNPs that exhibited high performance, with an F1-score of 98.55%, precision of 98.73%, recall of 98.38%, and overall accuracy of 98%. This study provides compelling evidence that the XGBoost feature selection method outperforms other representative feature selection methods, such as genetic algorithms, analysis of variance, chi-square, and principal component analysis, in predicting hypertension risk, demonstrating its effectiveness.</p><p><strong>Conclusions: </strong>We developed a model for predicting hypertension using the SNPs dataset. The high dimensionality of SNP data was effectively managed to identify significant features as biomarkers using the XGBoost feature selection method. The results indicate high performance in predicting the risk of hypertension.</p>","PeriodicalId":12947,"journal":{"name":"Healthcare Informatics Research","volume":"31 1","pages":"16-22"},"PeriodicalIF":2.1000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11854617/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Healthcare Informatics Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4258/hir.2025.31.1.16","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/31 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: Hypertension, commonly known as high blood pressure, is a prevalent and serious condition affecting a significant portion of the adult population globally. It is a chronic medical issue that, if left unaddressed, can lead to severe health complications, including kidney problems, heart disease, and stroke. This study aims to develop a feature selection model using the XGBoost algorithm to identify specific single nucleotide polymorphisms (SNPs) as biomarkers for detecting hypertension risk.
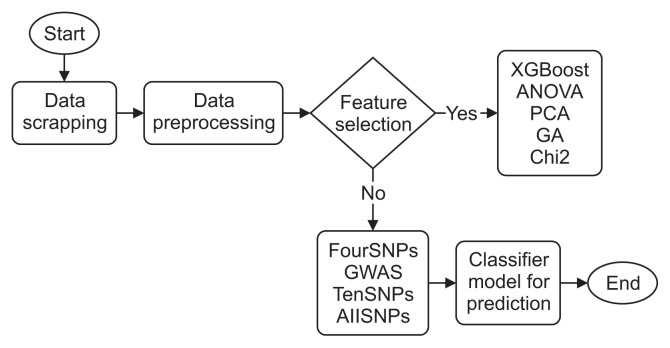
Methods: We propose using the high dimensionality of genetic variations (i.e., SNPs) to build a classifier model for prediction. In this study, SNPs were used as markers for hypertension in patients. We utilized the OpenSNP dataset, which includes 19,697 SNPs from 2,052 samples. Extreme gradient boosting (XGBoost) is an ensemble machine learning method employed here for feature selection, which incrementally adjusts weights in a series of steps.
Results: The experimental results identified 292 SNPs that exhibited high performance, with an F1-score of 98.55%, precision of 98.73%, recall of 98.38%, and overall accuracy of 98%. This study provides compelling evidence that the XGBoost feature selection method outperforms other representative feature selection methods, such as genetic algorithms, analysis of variance, chi-square, and principal component analysis, in predicting hypertension risk, demonstrating its effectiveness.
Conclusions: We developed a model for predicting hypertension using the SNPs dataset. The high dimensionality of SNP data was effectively managed to identify significant features as biomarkers using the XGBoost feature selection method. The results indicate high performance in predicting the risk of hypertension.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


