Raissa Souza, Emma A. M. Stanley, Anthony J. Winder, Chris Kang, Kimberly Amador, Erik Y. Ohara, Gabrielle Dagasso, Richard Camicioli, Oury Monchi, Zahinoor Ismail, Matthias Wilms, Nils D. Forkert
{"title":"Self-supervised identification and elimination of harmful datasets in distributed machine learning for medical image analysis","authors":"Raissa Souza, Emma A. M. Stanley, Anthony J. Winder, Chris Kang, Kimberly Amador, Erik Y. Ohara, Gabrielle Dagasso, Richard Camicioli, Oury Monchi, Zahinoor Ismail, Matthias Wilms, Nils D. Forkert","doi":"10.1038/s41746-025-01499-0","DOIUrl":null,"url":null,"abstract":"<p>Distributed learning enables collaborative machine learning model training without requiring cross-institutional data sharing, thereby addressing privacy concerns. However, local quality control variability can negatively impact model performance while systematic human visual inspection is time-consuming and may violate the goal of keeping data inaccessible outside acquisition centers. This work proposes a novel self-supervised method to identify and eliminate harmful data during distributed learning model training fully-automatically. Harmful data is defined as samples that, when included in training, increase misdiagnosis rates. The method was tested using neuroimaging data from 83 centers for Parkinson’s disease classification with simulated inclusion of a few harmful data samples. The proposed method reliably identified harmful images, with centers providing only harmful datasets being easier to identify than single harmful images within otherwise good datasets. While only evaluated using neuroimaging data, the presented method is application-agnostic and presents a step towards automated quality control in distributed learning.</p>","PeriodicalId":19349,"journal":{"name":"NPJ Digital Medicine","volume":"79 6 1","pages":""},"PeriodicalIF":12.4000,"publicationDate":"2025-02-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"NPJ Digital Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1038/s41746-025-01499-0","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
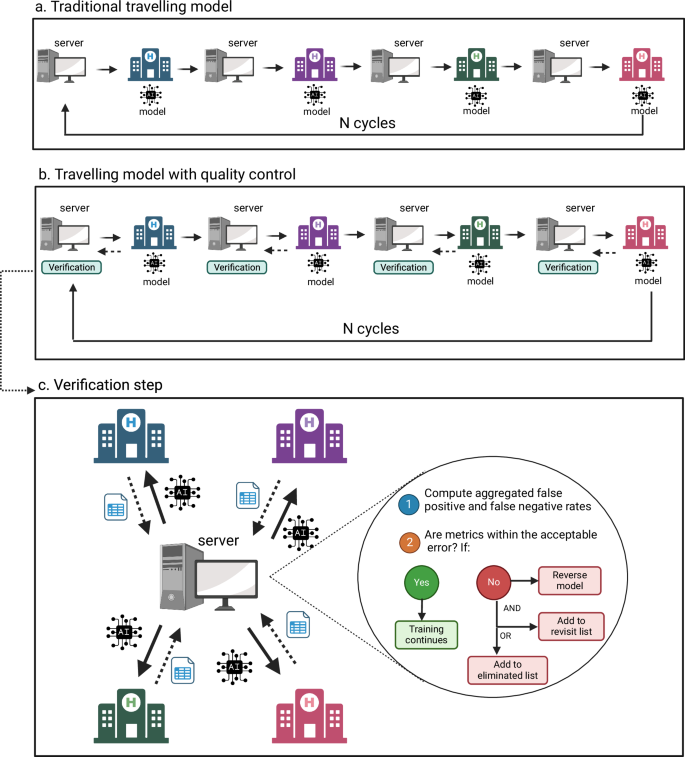
Distributed learning enables collaborative machine learning model training without requiring cross-institutional data sharing, thereby addressing privacy concerns. However, local quality control variability can negatively impact model performance while systematic human visual inspection is time-consuming and may violate the goal of keeping data inaccessible outside acquisition centers. This work proposes a novel self-supervised method to identify and eliminate harmful data during distributed learning model training fully-automatically. Harmful data is defined as samples that, when included in training, increase misdiagnosis rates. The method was tested using neuroimaging data from 83 centers for Parkinson’s disease classification with simulated inclusion of a few harmful data samples. The proposed method reliably identified harmful images, with centers providing only harmful datasets being easier to identify than single harmful images within otherwise good datasets. While only evaluated using neuroimaging data, the presented method is application-agnostic and presents a step towards automated quality control in distributed learning.
期刊介绍:
npj Digital Medicine is an online open-access journal that focuses on publishing peer-reviewed research in the field of digital medicine. The journal covers various aspects of digital medicine, including the application and implementation of digital and mobile technologies in clinical settings, virtual healthcare, and the use of artificial intelligence and informatics.
The primary goal of the journal is to support innovation and the advancement of healthcare through the integration of new digital and mobile technologies. When determining if a manuscript is suitable for publication, the journal considers four important criteria: novelty, clinical relevance, scientific rigor, and digital innovation.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


