Ayesha Sania, Nicolò Pini, Morgan E Nelson, Michael M Myers, Lauren C Shuffrey, Maristella Lucchini, Amy J Elliott, Hein J Odendaal, William P Fifer
{"title":"K-nearest neighbor algorithm for imputing missing longitudinal prenatal alcohol data.","authors":"Ayesha Sania, Nicolò Pini, Morgan E Nelson, Michael M Myers, Lauren C Shuffrey, Maristella Lucchini, Amy J Elliott, Hein J Odendaal, William P Fifer","doi":"10.3389/adar.2024.13449","DOIUrl":null,"url":null,"abstract":"<p><strong>Aims: </strong>The objective of this study is to illustrate the application of a machine learning algorithm, K Nearest Neighbor (<i>k-NN</i>) to impute missing alcohol data in a prospective study among pregnant women.</p><p><strong>Methods: </strong>We used data from the Safe Passage study (n = 11,083). Daily alcohol consumption for the last reported drinking day and 30 days prior was recorded using the Timeline Follow back method, which generated a variable amount of missing data per participants. Of the 3.2 million person-days of observation, data were missing for 0.36 million (11.4%). Using the <i>k-NN</i> imputed values were weighted for the distances and matched for the day of the week. Since participants with no missing days were not comparable to those with missing data, segments of non-missing data from all participants were included as a reference. Validation was done after randomly deleting data for 5-15 consecutive days from the first trimester.</p><p><strong>Results: </strong>We found that data from 5 nearest neighbors (i.e., K = 5) and segments of 55 days provided imputed values with least imputation error. After deleting data segments from the first trimester data set with no missing days, there was no difference between actual and predicted values for 64% of deleted segments. For 31% of the segments, imputed data were within +/-1 drink/day of the actual. Imputation accuracy varied by study site because of the differences in the magnitude of drinking and proportion of missing data.</p><p><strong>Conclusion: </strong><i>k-NN</i> can be used to impute missing data from longitudinal studies of alcohol during pregnancy with high accuracy.</p>","PeriodicalId":72092,"journal":{"name":"Advances in drug and alcohol research","volume":"4 ","pages":"13449"},"PeriodicalIF":0.0000,"publicationDate":"2025-01-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11811783/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advances in drug and alcohol research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/adar.2024.13449","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Aims: The objective of this study is to illustrate the application of a machine learning algorithm, K Nearest Neighbor (k-NN) to impute missing alcohol data in a prospective study among pregnant women.
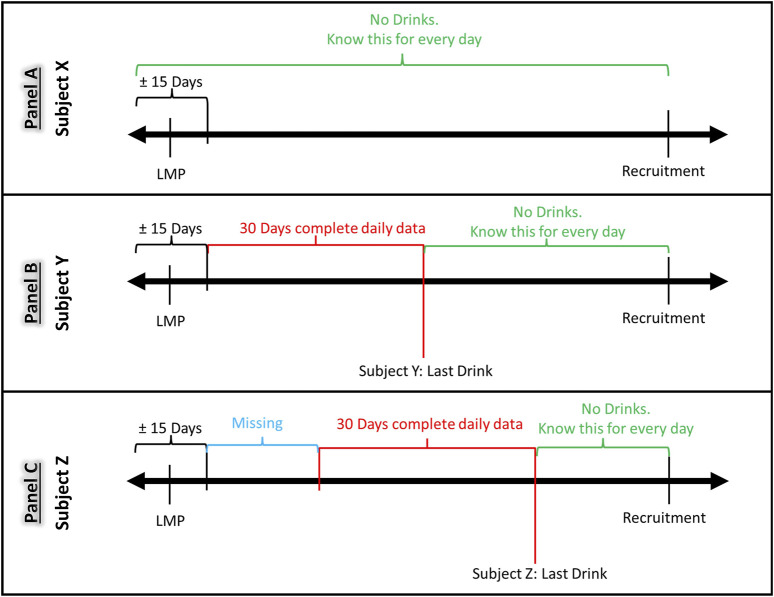
Methods: We used data from the Safe Passage study (n = 11,083). Daily alcohol consumption for the last reported drinking day and 30 days prior was recorded using the Timeline Follow back method, which generated a variable amount of missing data per participants. Of the 3.2 million person-days of observation, data were missing for 0.36 million (11.4%). Using the k-NN imputed values were weighted for the distances and matched for the day of the week. Since participants with no missing days were not comparable to those with missing data, segments of non-missing data from all participants were included as a reference. Validation was done after randomly deleting data for 5-15 consecutive days from the first trimester.
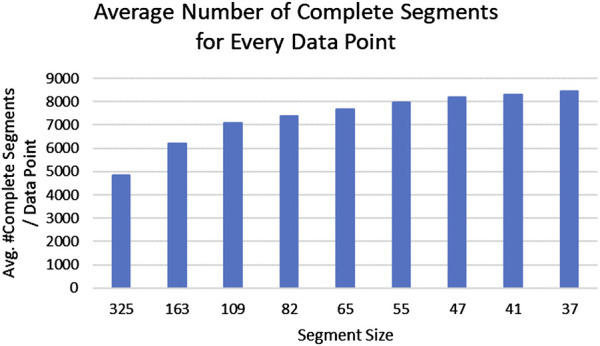
Results: We found that data from 5 nearest neighbors (i.e., K = 5) and segments of 55 days provided imputed values with least imputation error. After deleting data segments from the first trimester data set with no missing days, there was no difference between actual and predicted values for 64% of deleted segments. For 31% of the segments, imputed data were within +/-1 drink/day of the actual. Imputation accuracy varied by study site because of the differences in the magnitude of drinking and proportion of missing data.
Conclusion: k-NN can be used to impute missing data from longitudinal studies of alcohol during pregnancy with high accuracy.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


